Let’s say I have a Transformer like architecture where there’s various attention layers. I want to visualize the attention weights on the inputs. I can already plot the weights in a graph. But this is for a single layer.
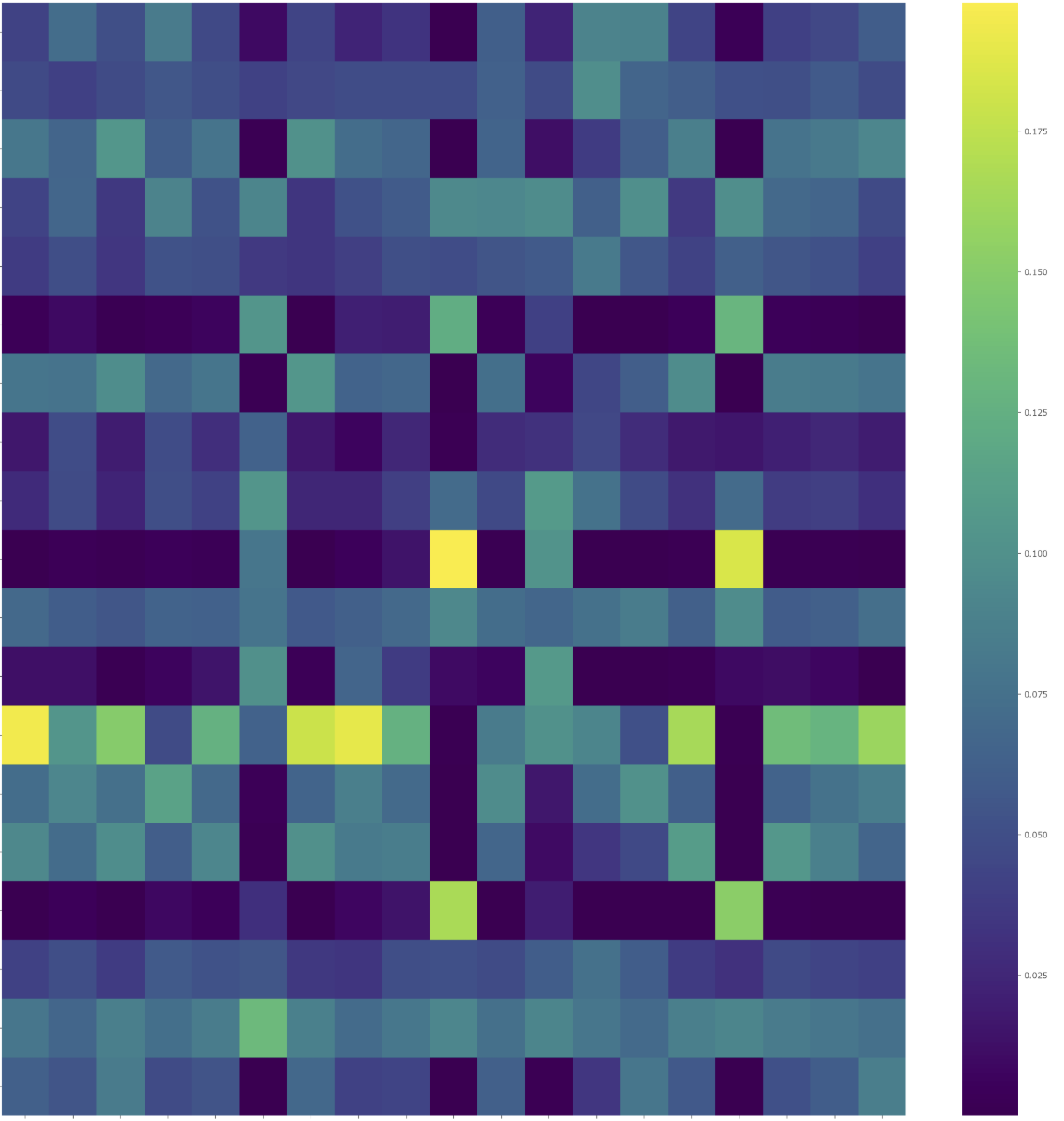
My question is about how do I handle the multi-heads in the multi-head attention and the fact that there’s multiple layers if my goal is to know how much total attention was devoted to a single input.
My transformer has 4 heads per attention layer and let’s say I have 2 layers of attention. My model spits out a matrix of size [batch_size, 2, 4, 512, 512]. 512 being the maximum sentence length.
I could grab weights[0,0] to get the first layer and the first head attentions and visualize this matrix, but it’s just the weights of one head in one layer.
What would be the best way to aggregate the attention weights to get a picture of how much total attention was given to a single input from the sequence?
Any pointer to papers or code (ideally in pytorch) would be greatly appreciated!
Thanks,