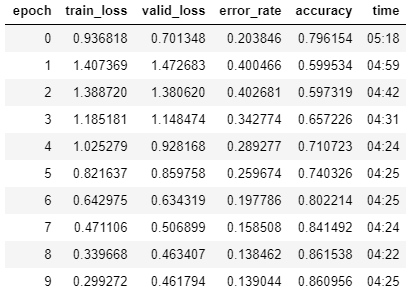
I’m working with the Stanford Dogs 120 dataset, and have noticed that I get the following pattern with ResNet-50 and ResNet-101 where in the second epoch the training and validation loss increases followed by the training and validation loss decreasing in the following epochs.
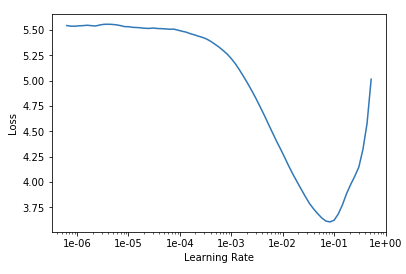
I am using lr_find() to select a learning rate where the slope is steepest, and have experimented with different weight wd and dropout ps, but the pattern still happens. I’m wondering if this is normal or if it means there’s a setting I should change?
I am using padding_mode='zeros' because reflection and border error out and it produces a more accurate results than squishing or cropping. tfms are the defaults.Then I create the model, call lr_find
I saw that you split by folder.
Probably the reason of the behavior you’ve described is the specific validation set you’ve chosen, that is not randomly selected from the same distribution as the training set, but is fixed and pre-defined (maybe holdout).
I’m pretty sure that if you randomly split train and validation set with 80% 20% and re-train the model, you’ll see the accuracy increasing up to the maximum as expected.