The purpose of this topic is to share experiences with hyperparameter for training the Tranformer XL.
Here is my experience:
the architecture uses a lot of GPU which makes experimentation more lengthy. To minimize restarting the jupyter kernel i have started to use stas’ “with gpu_mem_restore_ctx():” in the notebook when making grid search
training time to “convergence” increase dramatically as the number of data increases
training is very sensitive to hyperparameters setting and can diverge late in the training. i made a training that diverged after 120 hours
hyperparameters that works for small datasets does not necessarily work with large datasets so we need to find settings that are valid over a wide range (x1000 ) of datasets sizes
I started to run a semiautomatic grid search for hyperparameters start with 2.5e5 training data and 2.5e6 data.
In the experiment below i used:
nbtokens (using sentencepiece) =2.5e6
drop_mult=2
epochs=2:
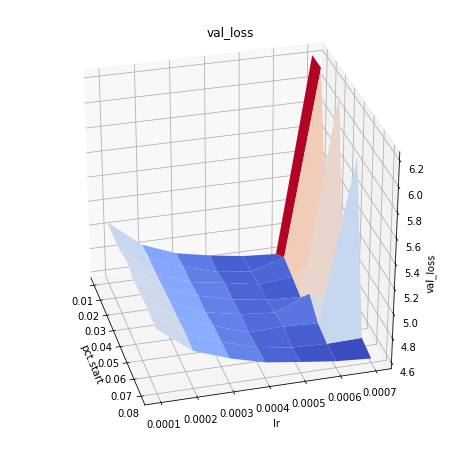
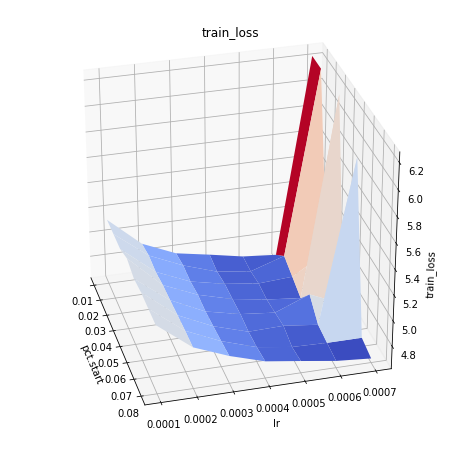
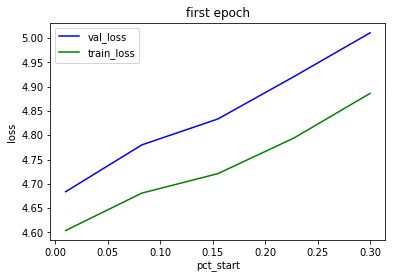
pct_start vs max learning rate:
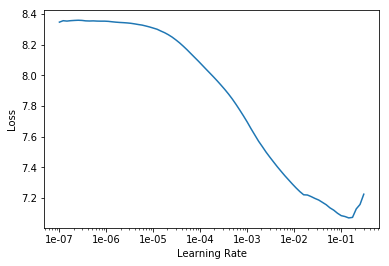
max_lr = 5e-4 gives the smallest loss and is independent of the shown range for pct_start. Higher values of max_lr are risky and often result in much higher loss.
lr_finder shows this. That is max_lr must be select to the left of the steepest slop.
for max_lr = 5e-4 pct_start = 0.02 result in the smallest loss.
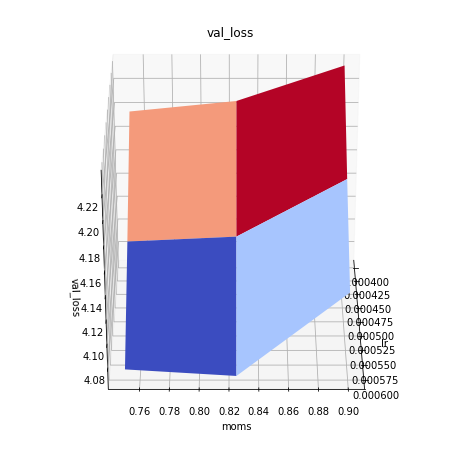
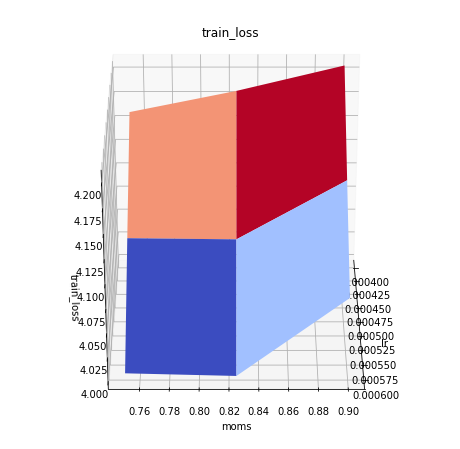
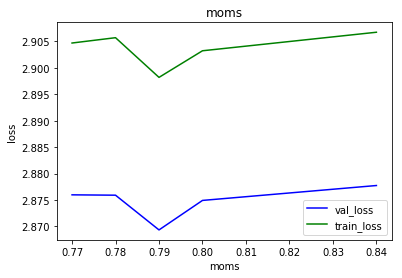
max_lr vs moms.
Here i use:
drop_mult=1
epoch = 5
the plots show a center_moms used to set moms in fit_one_cycle to (center_moms-0.05,center_moms+0.05)
This and the table below shows that center_moms 0.9 is too high and that there is little difference between center_moms = 0.75 and 0.825 for equal max_lr
max_lr
moms
val_loss
train_loss
0
0.0004
0.900
4.236100
4.2085323
1
0.0004
0.825
4.206955
4.1826377
2
0.0004
0.750
4.198223
4.1608105
3
0.0005
0.900
4.183878
4.142299
4
0.0005
0.825
4.136231
4.0814295
5
0.0005
0.750
4.132095
4.082628
6
0.0006
0.900
4.136360
4.0789223
7
0.0006
0.825
4.066686
3.9977622
8
0.0006
0.750
4.072268
4.000567
The best setting so far are:
-pct_start = 0.02
-max_lr = 5e-4
-center_moms = between 0.75 and 0.825
Work to do:
confirm that pct-start must be low. I have done it for nb training tokens = 2.5e5 but need to to it for 2.5e6
Thanks for starting that thread. I’m also planning to use this architecture over the next couple of weeks and happy to share in this thread when I get to it. What dataset did you use? Do you have a background training example with AWD LSTM on the same dataset? Here are some minor thoughts; please take them with a grain of salt since I haven’t played with transformer XL yet. Based on prior experience in language models, from the lr_finder plot you’ve shown I’d have probably picked a much lower rate despite the slower early convergence, but this is based on the AWD LSTM or plain LSTM architectures, so it’s possible that things are very different with Transformer-XL. Mixing the pct_start with the max_lr based on a limited set of batches from find_lr can be confusing, so I’d recommend against it for starters (The learning rate finder will only scan through a small subset of learning rates with the limited batches that it sees, and these learning rates will of course scale differently depending on the shape of the training curve which is changed with pct_start. I’d suspect that pc_start doesn’t have to be so low, but it’s hard to guess from the early training behavior.) How about picking a max_lr and train over a couple dozens epochs, and then perhaps sample a handful of such points? It sounds like you might have done such experiments already.
The target is to compare awd_lstm and TransformerXL over a wide range of datasizes from 2.5e6 training tokens to 2.5e9. This is a bit too ambitious for my TI1080. I have already done it using a modified awd_lstm but will redo it using the standard awd_lstm.
i am not using lr_find to make the grid search. I am running from 1-5 epoch (thus many batches). I use bs=64 and bptt=94 .
Concerning pc_start. Will make a plot later today to validate that - soo we will see. There are however reports from users of Tensor2Tensor that a slow start is advantageous
so i guess the streams must be processed in parallel in batches where each row represent a separate stream:
feature 1 …
feature 2 …
…
feature n …
where each dot is a sample.
if this is the case then the dataloader LanguageModelPreLoader should be rewritten because although it ensures continuity of sentences between batches for each row in the batch. When a sentence finishes we just add another sentence. That would not make sense in your case.
But i do believe that TransformerXL can be used to process parallel streams of data.
Thanks for the additional clarifications. What is the vocabulary size that you used in your own tokenization of the wikipedia? The loss function appears very high. Also, can you add as a metric the accuracy? Amazing as it seems, the best english-language models models get about 1/3 of the next token exactly correct when the vocabulary is about 60K.
I do not training to convergence when doing grid search - that would take insanely long.
The bedst validation loss that i have reached before the grid search was 2.703404 (ie perplexity 15) - notice that it cannot be compared to spacy’s word based tokens
bptt=70. had to reduce it from 94 due to a change in fastai
nb training tokens = 2.5e6
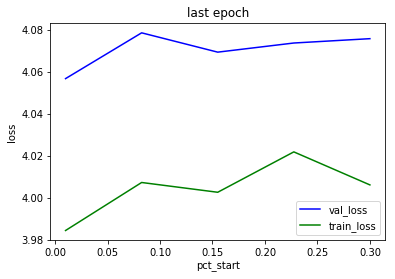
If we look at the loss after the first epoch then the difference is more pronounced:
This clearly show that using a high “pct_start” impact the training in a negative way
Status is that pct_start=0.02 found in the previous post is the best value so far.
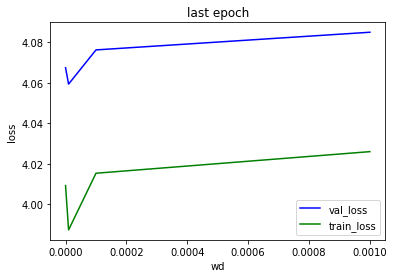
Here is weight decay with minimum loss for wd=1e-5 :
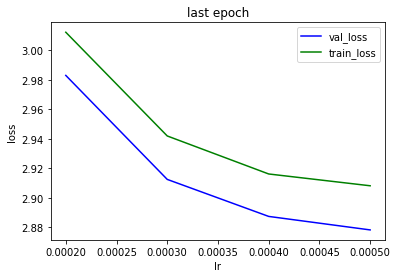
Here is search for max_lr with:
-nb training tokens = 2.5e8 and validation tokens 0.5e8
-drop-mult = 0.05
-learn.fit_one_cycle(cyc_len=1, max_lr=lr, moms=(0.75, 0.85), wd=1e-5, pct_start=0.02)
This confirms that 5e-4 is the best value for max_lr. The decrease in loss fades out when approaching mx_lr = 5e-4 . We saw earlier max_lr > 6e-4 tend to be unstable
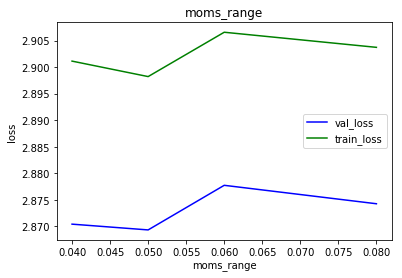
The search for moms and its range does not show a clear minimum so we keep moms = 0.79-0.05 , 0.79+0.05. More precise settings require running the search for more epochs
Hi again. Happy to help with the search if you can provide the exact prep process. It’s the little details on the exact datasets and on how to tokenize that would otherwise make our numbers incomparable.
I have done some cleaning and is currently testing whether that broke anything - will let you know.
I believe that the script will work for all western languages. For other languages you will have to adapt all the regular expression stuff in the beginning of fastai_sentencepiece.py and the rules in wikijson2TrainingData.
The cleaning of the wiki_text can be improved by taking a more systemtic approach to finding sentence with outliers (ie sentence with too many control characters).
I keep parentheses “( some text or number)” but i suspect that the language model will be better if parentheses and their content were removed. Some sentences have so many parentheses that they are difficult to read - even for humans
Thank you @Kaspar for the great insight into the model’s hyper parameters. I’m using them to train with a Spanish corpus, and it’s working pretty well! 29.99 perplexity with 60k vocab. Have you played with mem_len as well?