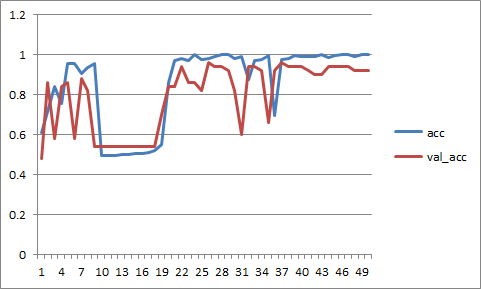
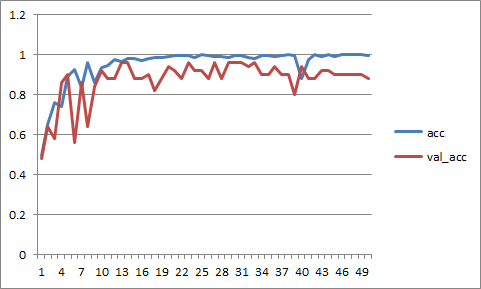
I’m working through the notebooks and I’m currently around lesson 2 and 3. I’m experimenting with layers in Keras and wanting to try training different dense layer configurations. To make this clean I thought I would export the convolutional part of the vgg net and then for each experiment load that part of the net, create completely new dense layers and train (in the example below to keep things simple i’m just using the same architecture of dense layers). My problem is that the training does not even start to converge and in fact seems to settle on exactly 50% error. Clearly I must be missing something in my code or understanding… but I’m not seeing it!
import utils; reload(utils)
from utils import *
%matplotlib inline
from vgg16 import Vgg16
vgg = Vgg16()
model = vgg.model
layers = model.layers
Get the index of the first dense layer…
first_dense_idx = [index for index,layer in enumerate(layers) if type(layer) is Dense][0]
also save the weights
path = "data/redux/sample/"
models_path = "data/redux/models/"
train_path = path + "train/"
valid_path = path + “valid/”
Drop this and all subsequent layers
num_del = len(layers) - first_dense_idx
for i in range (0, num_del): model.pop()
Set all layers to non-trainable (these are the conv layers)
for layer in model.layers: layer.trainable=False
serialize model to JSON and save to a file
model_json = model.to_json()
with open(models_path+“vgg16_conv.json”, “w”) as json_file:
json_file.write(model_json)
model.save_weights(models_path+“vgg16_conv.h5”)
Now load the model (I usually do this in a different notebook)
from keras.models import model_from_json
note i had to move this line inside vgg_preprocess in vgg16.py for the saving/loading to work properly
vgg_mean = np.array([123.68, 116.779, 103.939], dtype=np.float32).reshape((3,1,1))
load json and create model
json_file = open(models_path+“vgg16_conv.json”, “r”)
loaded_model_json = json_file.read()
json_file.close()
model = model_from_json(loaded_model_json)
load weights into new model
model.load_weights(models_path+“vgg16_conv.h5”)
print(“Loaded model from disk”)
#get the batches
batch_size = 64
train_batches = image.ImageDataGenerator().flow_from_directory(train_path, target_size=(224,224),
class_mode=‘categorical’, shuffle=True, batch_size=batch_size)
valid_batches = image.ImageDataGenerator().flow_from_directory(valid_path, target_size=(224,224),
class_mode=‘categorical’, shuffle=True, batch_size=batch_size)
num_target_classes = train_batches.nb_class
the model is now loaded and the weights loaded into it
add dense layers… in this example i’m just adding the same architecture of layers as the original vgg
model.add(Dense(4096, activation=‘relu’))
model.add(Dropout(0.5))
model.add(Dense(4096, activation=‘relu’))
model.add(Dropout(0.5))
model.add(Dense(num_target_classes, activation=‘softmax’))
as i understand it i should now have a model where the convolutional layers are the same as vgg
with the same weights. these layers should be non trainable
plus dense layers have the same architecture as vgg but with fresh random weights ready to be trained
I use SGD with a fairly large learning rate as the weights are completely random
model.compile(optimizer=SGD(lr=0.01), loss=‘categorical_crossentropy’, metrics=[‘accuracy’])
now retrain the model:
model.fit_generator(train_batches, samples_per_epoch=train_batches.nb_sample, nb_epoch=50,
validation_data=valid_batches, nb_val_samples=valid_batches.nb_sample)
i get the following output…!
Epoch 1/50
200/200 [==============================] - 7s - loss: 7.2976 - acc: 0.5200 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 2/50
200/200 [==============================] - 6s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 3/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 4/50
200/200 [==============================] - 6s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 5/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 6/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 7/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 8/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 9/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 10/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 11/50
200/200 [==============================] - 6s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 12/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 13/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 14/50
200/200 [==============================] - 6s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
Epoch 15/50
200/200 [==============================] - 7s - loss: 7.9785 - acc: 0.5050 - val_loss: 8.7038 - val_acc: 0.4600
… etc
model.summary gives the following output
Layer (type) Output Shape Param # Connected to
lambda_3 (Lambda) (None, 3, 224, 224) 0 lambda_input_6[0][0]
zeropadding2d_27 (ZeroPadding2D) (None, 3, 226, 226) 0 lambda_3[0][0]
convolution2d_27 (Convolution2D) (None, 64, 224, 224) 0 zeropadding2d_27[0][0]
zeropadding2d_28 (ZeroPadding2D) (None, 64, 226, 226) 0 convolution2d_27[0][0]
convolution2d_28 (Convolution2D) (None, 64, 224, 224) 0 zeropadding2d_28[0][0]
maxpooling2d_11 (MaxPooling2D) (None, 64, 112, 112) 0 convolution2d_28[0][0]
zeropadding2d_29 (ZeroPadding2D) (None, 64, 114, 114) 0 maxpooling2d_11[0][0]
convolution2d_29 (Convolution2D) (None, 128, 112, 112) 0 zeropadding2d_29[0][0]
zeropadding2d_30 (ZeroPadding2D) (None, 128, 114, 114) 0 convolution2d_29[0][0]
convolution2d_30 (Convolution2D) (None, 128, 112, 112) 0 zeropadding2d_30[0][0]
maxpooling2d_12 (MaxPooling2D) (None, 128, 56, 56) 0 convolution2d_30[0][0]
zeropadding2d_31 (ZeroPadding2D) (None, 128, 58, 58) 0 maxpooling2d_12[0][0]
convolution2d_31 (Convolution2D) (None, 256, 56, 56) 0 zeropadding2d_31[0][0]
zeropadding2d_32 (ZeroPadding2D) (None, 256, 58, 58) 0 convolution2d_31[0][0]
convolution2d_32 (Convolution2D) (None, 256, 56, 56) 0 zeropadding2d_32[0][0]
zeropadding2d_33 (ZeroPadding2D) (None, 256, 58, 58) 0 convolution2d_32[0][0]
convolution2d_33 (Convolution2D) (None, 256, 56, 56) 0 zeropadding2d_33[0][0]
maxpooling2d_13 (MaxPooling2D) (None, 256, 28, 28) 0 convolution2d_33[0][0]
zeropadding2d_34 (ZeroPadding2D) (None, 256, 30, 30) 0 maxpooling2d_13[0][0]
convolution2d_34 (Convolution2D) (None, 512, 28, 28) 0 zeropadding2d_34[0][0]
zeropadding2d_35 (ZeroPadding2D) (None, 512, 30, 30) 0 convolution2d_34[0][0]
convolution2d_35 (Convolution2D) (None, 512, 28, 28) 0 zeropadding2d_35[0][0]
zeropadding2d_36 (ZeroPadding2D) (None, 512, 30, 30) 0 convolution2d_35[0][0]
convolution2d_36 (Convolution2D) (None, 512, 28, 28) 0 zeropadding2d_36[0][0]
maxpooling2d_14 (MaxPooling2D) (None, 512, 14, 14) 0 convolution2d_36[0][0]
zeropadding2d_37 (ZeroPadding2D) (None, 512, 16, 16) 0 maxpooling2d_14[0][0]
convolution2d_37 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_37[0][0]
zeropadding2d_38 (ZeroPadding2D) (None, 512, 16, 16) 0 convolution2d_37[0][0]
convolution2d_38 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_38[0][0]
zeropadding2d_39 (ZeroPadding2D) (None, 512, 16, 16) 0 convolution2d_38[0][0]
convolution2d_39 (Convolution2D) (None, 512, 14, 14) 0 zeropadding2d_39[0][0]
maxpooling2d_15 (MaxPooling2D) (None, 512, 7, 7) 0 convolution2d_39[0][0]
flatten_3 (Flatten) (None, 25088) 0 maxpooling2d_15[0][0]
dense_17 (Dense) (None, 4096) 102764544 flatten_3[0][0]
dropout_13 (Dropout) (None, 4096) 0 dense_17[0][0]
dense_18 (Dense) (None, 4096) 16781312 dropout_13[0][0]
dropout_14 (Dropout) (None, 4096) 0 dense_18[0][0]
dense_19 (Dense) (None, 2) 8194 dropout_14[0][0]
Total params: 119554050