Hi everyone,
When training on a real life data of 3 classes (very similar classes), my model training and val accuracy is reaching 95% but on test dataset, the model is not performing good. I know this is a clear case of overfitting. So to counter that, I removed very similar images from dataset (images were taken out from videos and they were quite similar to one another) and now model accuracy has decreased from 95 to 85 but it is performing better on test data.
So is it good to say that we need to train the model on less but distinct images rather than more images that are similar? @jeremy
P.S: I finetuned some last layers on inception model. I will try Resnet as we used soon to compare the results but it won’t make much difference.
Double check that you are actually matching up your filenames correctly to your images. I have had an identical issue and it was because I didn’t have them matched up. For me it was because I was using Keras’ flow_from_directory and I needed to set shuffle = false to keep the filenames and the images together. A test you could do is plot one of the test images and put the filename you think it is next to it and go check to see if it actually is.
I would think you would at least be able to come in the ballpark of the validation set with your testing set. I would be more concerned with overfitting if the training was really high, but the validation was really low, but if validation is decently high as well, it makes me think overfitting isn’t the main problem. Then again, I’m not an expert.
It’s hard to help without seeing the training results - if you could share your code or a screenshot of your training, we can probably be more helpful…
I think I did not explained my question well before.
I had 1000 images per class. I used 700 for training, 200 for val and 100 for testing. My training accuracy was 96%, val accuracy: 94% and testing accuracy: 90%. Now since out of 1000 images I took out some for testing, I thought my model has generalized well seeing my results.
Now, I asked some users to collect some images of same product in a bit different conditions and to check the results. Now my model is performing really bad. Like upon testing 200 images, my accuracy was 35%.
The ques is: Has my model learnt a lot of noises and is not performing well on different backgrounds or what could be the reason for it @KevinB@jeremy ?
Yes, this shows that your training data wasn’t varied enough. Best way to fix is by curating a more varied set of data to train on. Otherwise, you’ll need to try to come up with some data augmentation methods that approximate that variation.
I trained with fewer images but varied ones and the performance on the real test data set was better. So I agree with your point. So can I assume lesser datasets with high variance is a better choice than more data with less variance.
I have some 3D rendered models of the same dataset and I took a lot of images out of it with varied backgrounds. I am testing on those. I will share the results soon. Just asking theoretically: Will these varied 3D models will help in some way or will they make the thing worse?
@jeremy - Trying to do CNN (started with lesson 1) on a different dataset but get this error. I organised the data same as the dogs cats dataset. What do i do?
In my dataset i have 6 diff animals instead of 2 (like in dogscats). so based on this:
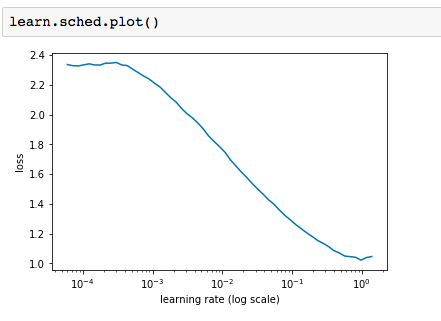
i chose LR = 1e-1.(Is it correct?)
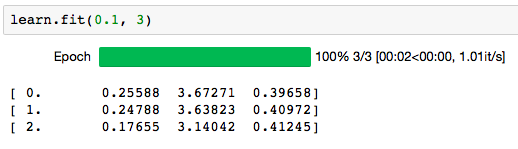
But when i do this (started with 1 epoch and went up to 3):
It is bad. What am i doing wrong?
lr is correct. you can also try 1e-2. it looks like huge overfit, but it is strange this happens starting from epoch 1. Can you try some antioverfit pills (augmentation, increase drop rate)?
How do you get this pretty green progressbar and neat formatting? On google colab there’s just text progressbar and not so beautifully formatted output overall.
Please point me to the mechanisms behind jupiter notebooks, couldn’t really google nothing.