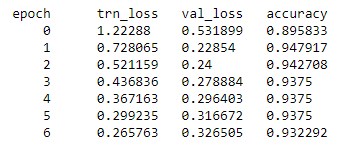
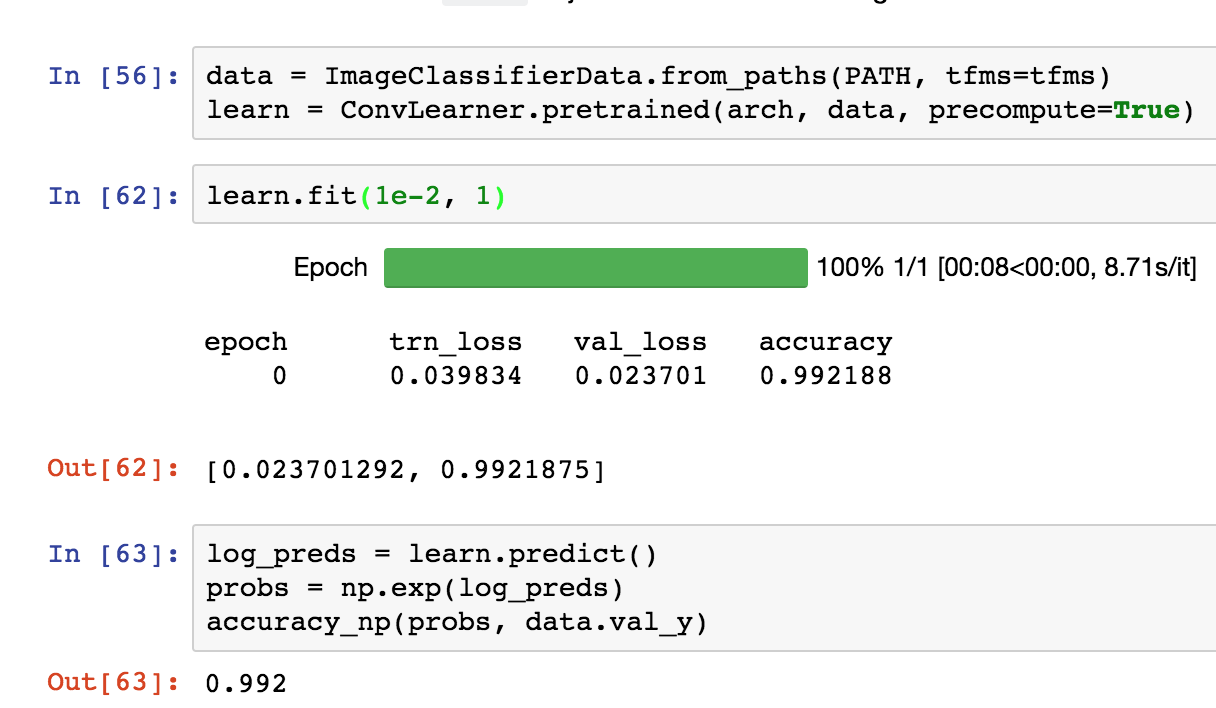
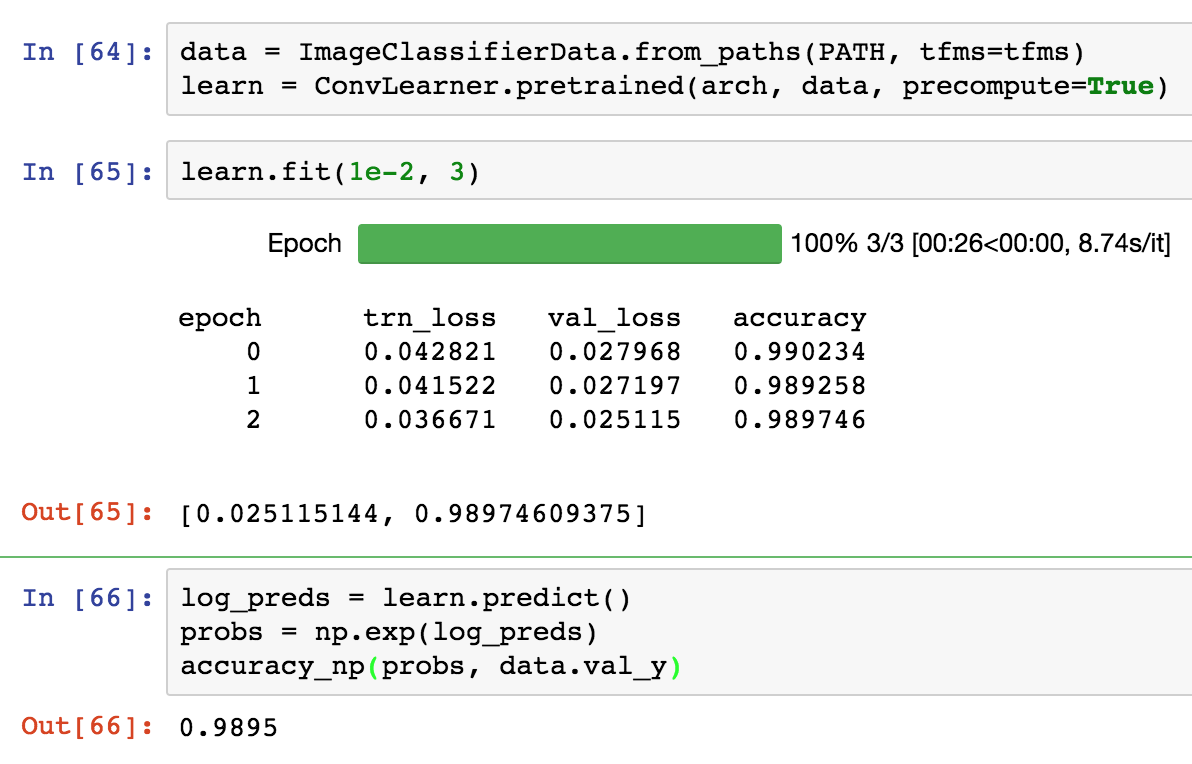
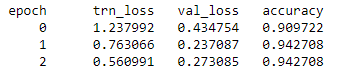The accuracy printed when the training is running is the training set accuracy (as shown below).
It can be seen that the training loss is decreasing steadily.
And at the same time we see, validation loss decreasing then increasing (after second epoch). This shows us that the model is overfitting.
But why does the training set accuracy show a similar trend to the validation loss: that is increase then subsequent decrease (opposite because loss and accuracy are inversely related).
The training set accuracy show follow similar trends as the training set loss: accuracy should keep increasing with epochs.
Very interesting. Do you have your code and dataset somewhere in github or gist.github.com so we can get to the bottom of this? I couldn’t see what’s wrong, but @jeremy might be able to explain this behavior.
The relevant section name is ‘personal testing’.
It contains the code and results which were found after running the code.
Notebook was created after running the code in that section.
I did a quick test with Dogs vs. Cats and don’t see the problem. Can you confirm two things - Do a git pull to update your fast.ai code (hopefully you are not using the pip version?)
Then run the cats vs. Dogs for the same cells and let me know what you get -
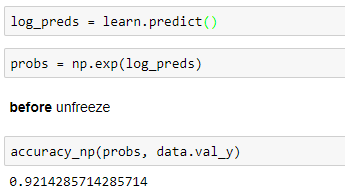
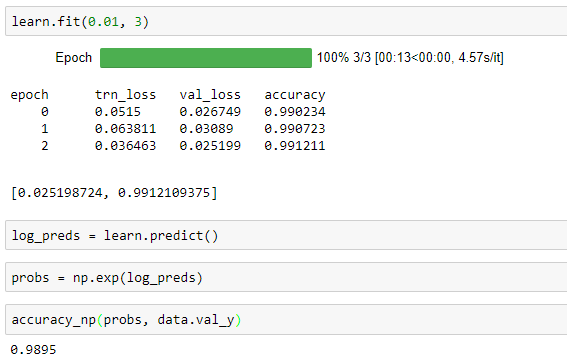
@parth_hehe - Figured out what was going on. The learn.fit method calculates Accuracy for each Batch and then averages them across all the batches at the end, whereas learn.predict calculates the average across all the predictions in one go and not per-batch.
In your data, your validation data was 140 rows and batch_size 64. So it did 64, 64, 12. Since the third batch is much smaller than the first two, when we do average of the averages in each batch, it results in different results. I will create a pull request to fix it in the next day. Thanks for your help to get to the bottom of this issue.
@parth_hehe - The pull request is now merged. Can you update your fastai (git pull) and then give it a try and let us know if that resolved your issue.
I tried to find it on the forum and couldn’t get a simple answer.
How is it possible to see training accuracy for example on resnet34?
In his book Machine Learning Yearning Andrew Ng recommends to compare training accuracy and validation accuracy to figure out priorities in moving forward with a project’s direction.