I’ve been working through Lessons 1 and 2, substituting the default dataset to a dataset of lichen images. Classes are lichen genera.
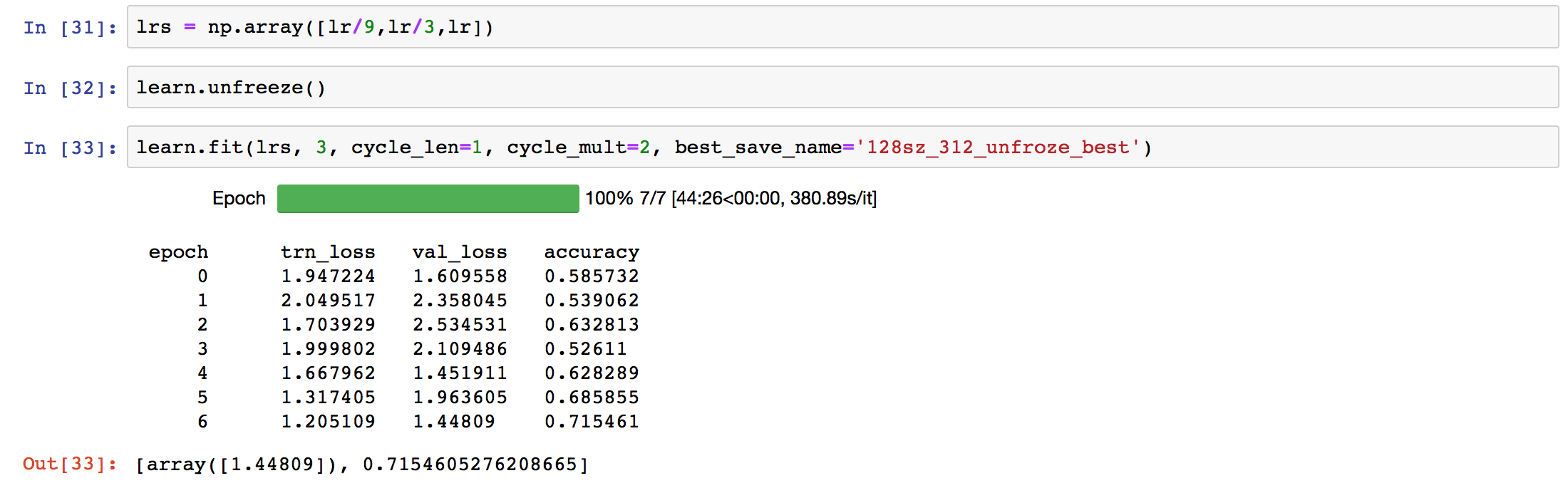
I’ve been curious to try the strategy in the lesson 2 notebook, of sequentially increasing the image size. I start out at small sizes, 64, training with layers frozen and then unfrozen. Then I increase size to 128, repeating the training in both frozen and unfrozen states. The frozen epochs seem pretty stable:
Would anyone have any idea what is happening here? After epoch 0, it appears as though the model begins to overfit, but then in epoch 4 it jumps back to something that looks promising, and then again descends into overfit territory.
The losses look fine. Sure there are some jitters but overall the training and validation losses both decreased over the epochs. Your accuracy is still increasing a lot every epoch - I would say the model has room to improve further. I would try training more at a lower learning rate - that might help the model settle down a bit more.
One thing I would suggest is adding learn.bn_freeze(True) after learn.unfreeze() to keep the batchnorm values of the base model constant.
I’ve had some success thanks to the encouragement here, and am approaching 83% accuracy. I’ve increased size sequentially, starting at 64, 128, 224, and 299, training a resnext101 architecture. I cycle through a frozen and unfrozen sequence for each. I’m curious to try greater sizes, though I’m definitely seeing diminishing returns at 299. The value of unfreezing and training the lower layers via differential learning rates seems to decrease with size increase. Does that resemble anyone else experience?
After reading through many threads on this forum, I still don’t understand why one should learn.bn_freeze(True) after learn.unfreeze() during finetuning. We are still training the NN, and the activations (or layer inputs) are still been normalized, so the NN should still be allowed to learn the batchnorm parameters so prevent “covariate shift”.