Hello!
TL;DR: Can I get some tips on training a language model at least 1GB data in the form of wikitext-103 on a graphics card with 3GB memory?
As a part of my master thesis I’m making a language model in Swedish which I’ll later on implement my primary architecture on (I’m building a summarizer using ULMFiT backbone), but I’ve run into some issues.
The main problem is that the graphics card which I can use is a 780 Ti, which has 3GB graphical memory. I datamined the Swedish wikipedia to be in the same format as wikitext-103 which lands around 600k articles, or 3GB. Now I’m somewhat happy with the data mining, and I’d like to use at least 1GB of sv-wiki in order to create a good enough model, but this proved hard to achieve.
Through extensive trial and error I found I can’t train on more than about 5k articles at once (20MB) using:
data = (TextList.from_folder(path_to_one_batch,vocab=vocab).split_from_folder() .split_for_lm().databunch(bs=16))
learner= language_model_learner(data, LSTM_AWD, ... ),
since that seems to allocate too much memory (even using batch size lower than 8). So to solve it I split up the articles in 120 prebatches, one batch per folder 0-119, 5000 articles per batch in their own text file (article0.txt, article1.txt, …), in a train, test, validate folder structure in order to be loaded by the fastai library seamlessly, then i iterated through each and created a db which i saved to pkl for easy loading when training. My core idea here is that the order “shouldn’t” really matter (worst case it’ll become soft reboot discriminate learning, or something like that) as long as I train on enough tokens and train the same learner.
Now I couldn’t simply replace the data from the learner since this caused some sort of CUDA error, so as a workaround i save the encoder of the learner, create a new learner and then load the encoder of the previously trained learner. In theory it should keep training on the same learner iteration to iteration. Said and done, it executes anyway!
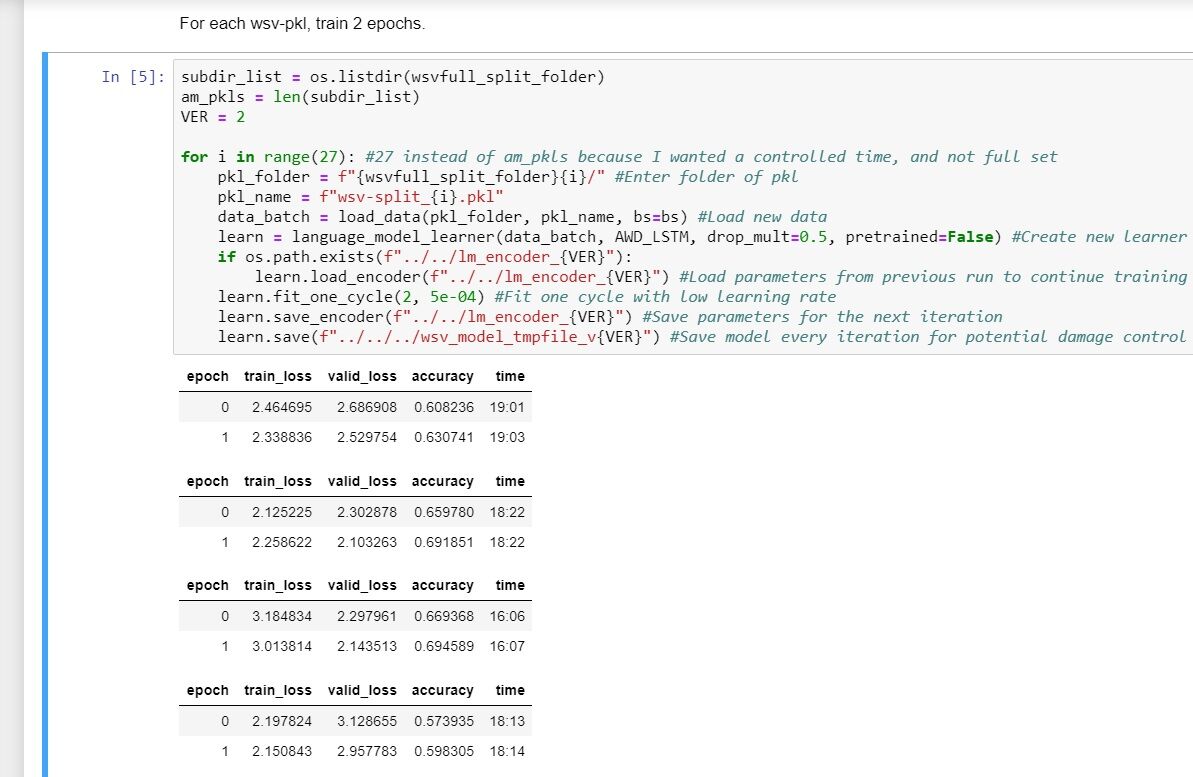
So I just came back after about 17 hours of training, and something is obviously amiss, see picture below. I notice that I achieve a perplexity of about exp(~2.5) ~= 13 after only one epoch, “world record”, yes! …sort of, something is obviously not working, and it’s time to get some help.
Long thread, I’m sorry, thank you for given time.
Lorentz
EDIT: Typos