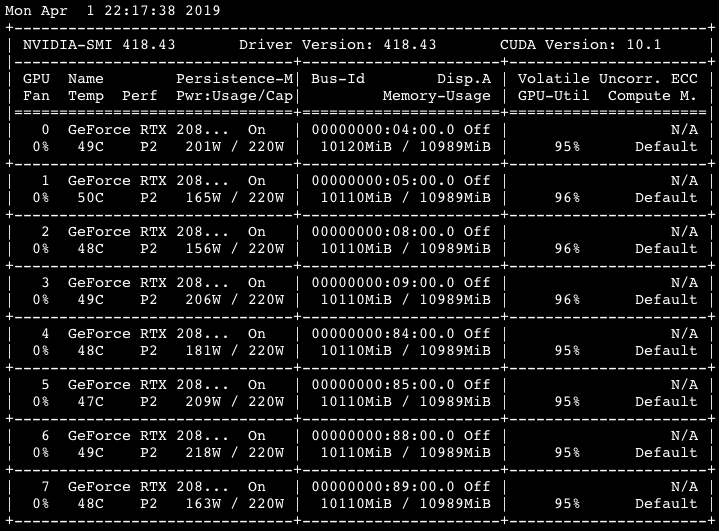
I’m using learn.model=nn.DataParallel(learn.model) as I’ve seen in the forums to try to scale up a model to train on multiple GPUs.
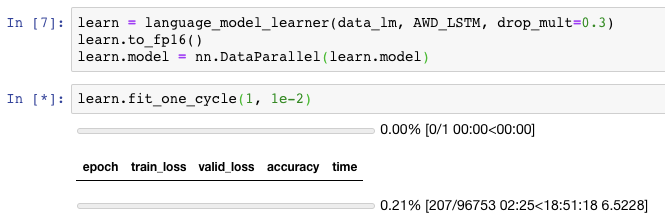
It seems to be working with multiple GPUs but training 1 epoch on 8x 2080ti is actually looking to be much slower than on 1x 2080ti.
I think this is because I haven’t been able to increase my batch size. If I try to increase the batch size I get a CUDA out of memory error because GPU 0 is disproportionately using more memory than the others. nvidia-smi output looks like this:
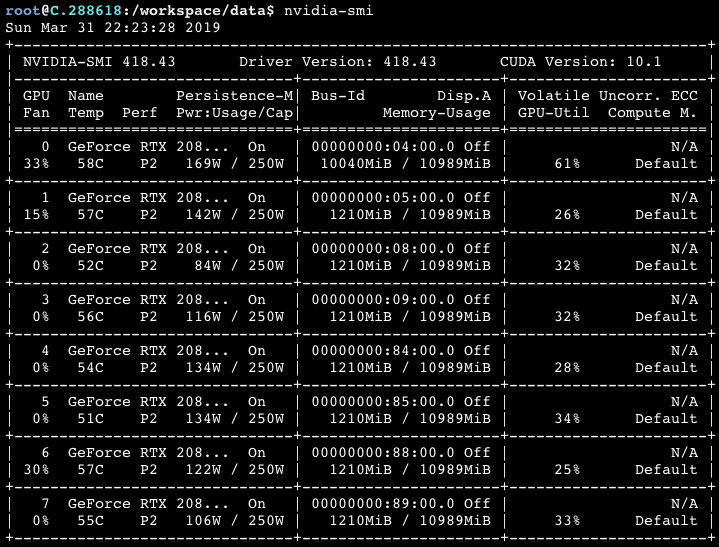
I’ve been doing some research and it looks like this is because nn.DataParallel accumulates the gradients onto a single GPU. There is some code in the last post there that purports to spread this out across all of the GPUs but I haven’t been able to get good results.
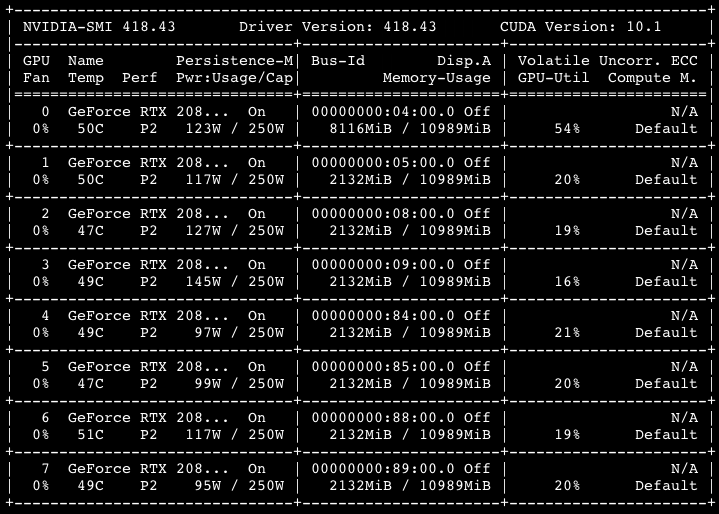
If I do learn.loss_func=CriterionParallel(learn.loss_func) as that post suggests (where CriterionParallel is lifted from the forum post) it does balance out the memory usage slightly but not much (and the estimated time for 1 epoch nearly doubles compared to not using it):
I also found a link to this project which also tries to solve the problem. But when I try to use encoding.parallel.DataParallelModel and encoding.parallel.DataParallelCriterion like this:
import encoding
learn.model = encoding.parallel.DataParallelModel(learn.model)
learn.loss_func = encoding.parallel.DataParallelCriterion(learn.loss_func)
I get an error: AttributeError: 'FlattenedLoss' object has no attribute 'parameters'. Pretty sure this is because normal Pytorch loss functions are subclasses of nn.Module whereas fastai’s FlattenedLoss doesn’t inherit from anything.

To get around this, I tried to make FlattenedLoss subclass nn.Module… but it was a dead end for me. It needed me to call super().__init__() before setting self.func but complained when I did that as well.
Anyone have a solution for balancing out memory usage so I can increase batch size to take advantage of multiple GPUs while training a language model?
Edit: found this thread that summarizes the problem and at the end someone suggests using Distributed instead of Parallel which I may try later.