Mi name is Jonathan and I write from Chile … I’m taking the course for coders v3, and I’ve heard once Jeremy saying tha’s is not a good model behavior having training losses higher than validations losses.
I’m playing with MNIST dataset, and these are my results:
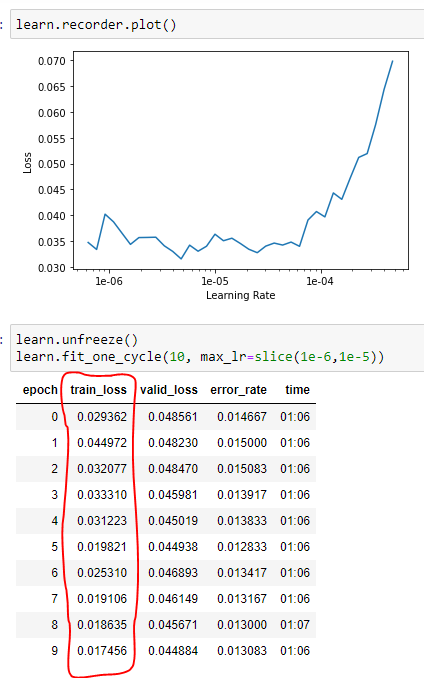
Training size: 40,8K | Validation size: 10,2K | Freezed model | Resnet34
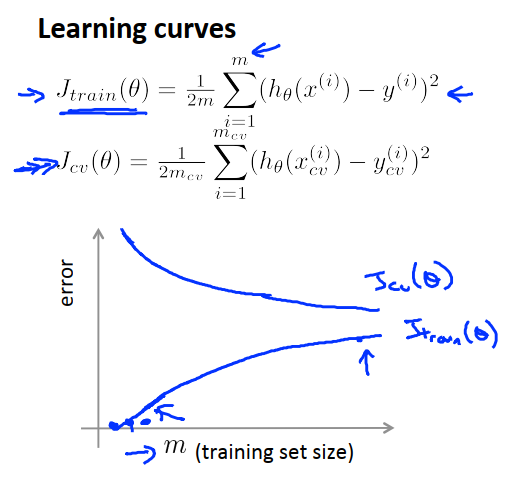
I just want to know if I’m doing it well. I just try to follow Jeremy’s advice, and also from what I learnt from Andrew Ng about learning curves in lesson 6 from his Coursera course “Machine Learning”, who also said that a well trained model tended to be something like this (I think the principle applies no matter Andrew Ng’s lesson was about Linear Regression):
So …
¿Did my first freezed model need to be fine tuned? I said it becase the training and validations losses curves (not always the training loss was lower than the validation’s)
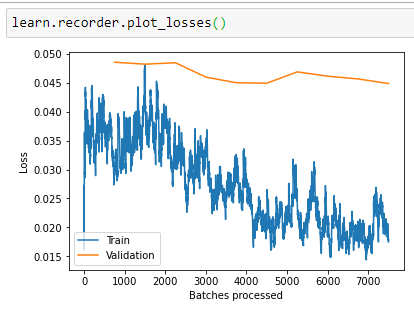
¿Did my second unfreezed model do well? I said it becase the training loss was always lower than the validation’s. However, the error_rate goes up a little in the last4 epochs …
I’ll wll apprecciate any feedback about my models.
Correct, a good model will always overfit … e.g., the training loss < validation loss. This makes sense as the validation set is comprised of examples the NN does not see during training, and therefore, cannot make any adjustment to the model’s parameters on account of them.
But, how good your model is, is determined on how well it does on the validation set. In particular, what you care about is/are your metric(s) … e.g., error rate. Remember that the loss is just an approximation of what you really care about (error rate) that provides a well behaved gradient that responds to very small changes in your parameters/weights.
Looks good with the exception that after calling learn.unfreeze(), your error rate doesn’t get much better after about the 5th epoch. Given the results of lr_find, I’d suggest something like max_lr=slice(1e-7, 5e-6) … the last number being the spot it starts getting worse … and/or just train for 5 epochs (so retrain the NN from scratch but only do 5 epochs after unfreeze).
 … I’m taking the course for coders v3, and I’ve heard once Jeremy saying tha’s is not a good model behavior having training losses higher than validations losses.
… I’m taking the course for coders v3, and I’ve heard once Jeremy saying tha’s is not a good model behavior having training losses higher than validations losses.