Hi - I am trying to do basic training on relatively clean DF - but for some reason, the language_model gets trained normally - but the classifier doesn’t.
The error is saying there’s a label (ID) in your (I think) validation set not present in the training set, which is not surprising since IDs are usually unique to each row.
Are you sure you’re labelling your data properly? Maybe you meant some other column?
For some reason, it keeps telling me that one of the labels is not included in the training set - although I haven’t trained anything yet. I am just trying to create a data bunch before training the model.
I managed to bay-pass the error by including the valid_pct parameter. Thank you!
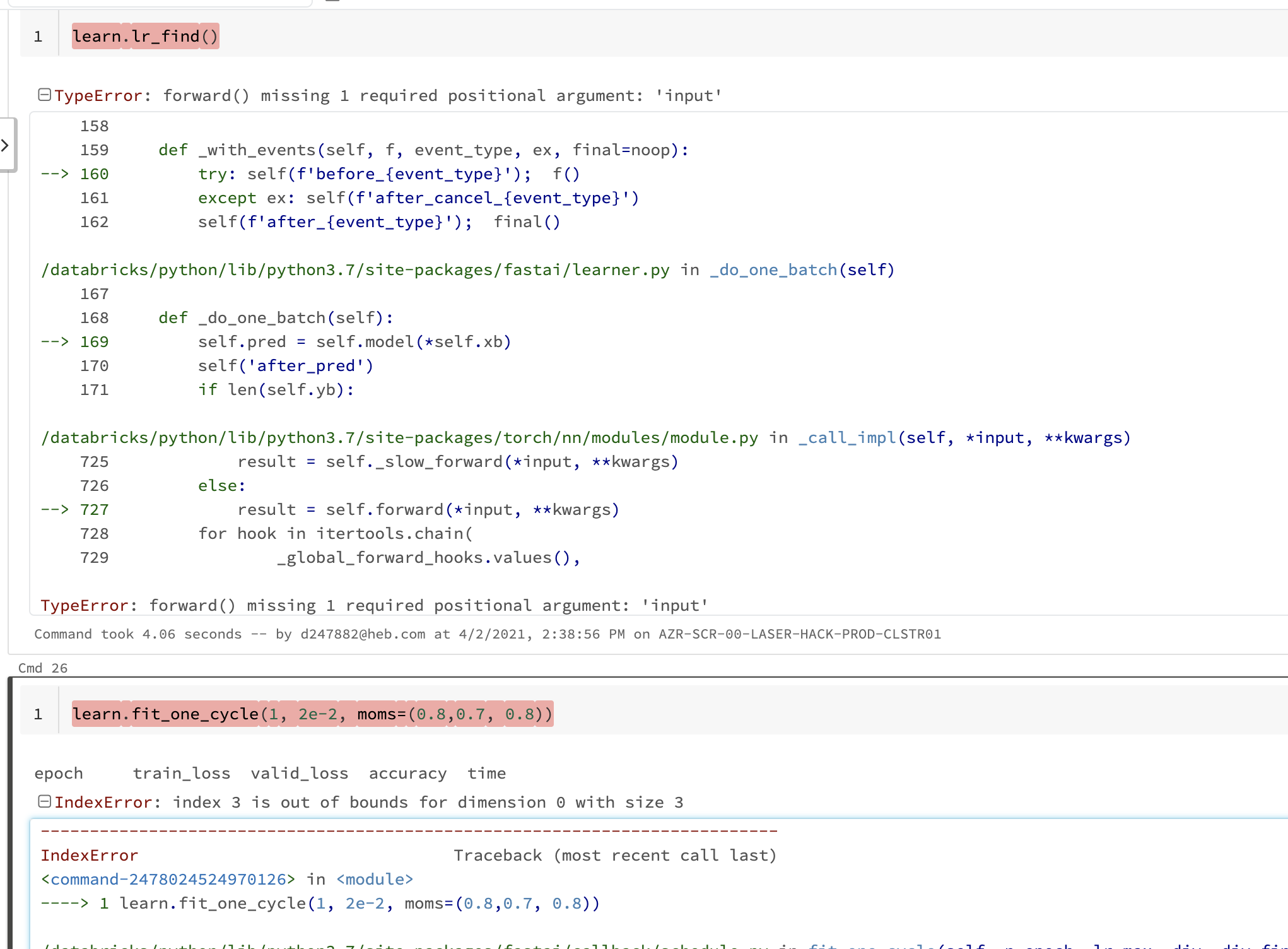
Now, for the classifier, when I run: learn.lr_find() after executing the two lines below:
Now, when I set the bs = 128 for both dbunch_lm and dbunch_cl, I am only getting the last error when I try to run learn.fit_one_cycle(1, 1e-2, moms=(0.8,0.7,0.8))
Error: IndexError: index 3 is out of bounds for dimension 0 with size 3
When I pass in the vocab, the error becomes: forward() missing 1 required positional argument: 'input'
My dataframe has a text column - a string, and a label, a number.