I wondered what is your experience about training a model with steps defined in first Lesson:
Enable data augmentation, and precompute=True
Use lr_find() to find highest learning rate where loss is still clearly improving
Train last layer from precomputed activations for 1-2 epochs
Train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with cycle_len=1
Unfreeze all layers
Set earlier layers to 3x-10x lower learning rate than next higher layer
Use lr_find() again
Train full network with cycle_mult=2 until over-fitting
In Lesson 2 Jeremy showed how each of these steps improved the score of a model on a Dog Breeds Kaggle competition. I am trying to achieve similar results like to make every step work. So far not so good. Model accuracy on precompute = True is almost the same as after steps 4-8. I tried two models (inception_v4 and inceptionresnet), different variations of image size, batch size, dropout.
Did you find a key how to apply these scheme? What am I missing?
@sermakarevich I am sure Jeremy can answer much better than me, but just wanted to share with you my own experience thus far.
After following these steps on a couple of different datasets/problems I have found that the most crucial thing to get right is the learning rate. lr.find() helps to get the top layer learning rate fairly easily but it can take quite a bit of trial & error to get the other two learning rates right for the earlier layers when unfreezing i.e. [lr/?, lr/?, lr].
One other parameter that isn’t really emphasized here is you can also play around with cycle_len setting that at diff values besides 1. (2, 3, 4 etc.)
Using different image sizes should improve accuracy. If you are having trouble seeing results with doing this in-between training epochs, another method you can try is to average the predictions that were generated from training runs with different image sizes as it can sometimes achieve the same/similar results. For example, I have personally used this technique before with good results (Invasive Species).
You mentioned model accuracy on precompute = True being the same after steps 4 to 8. I’m not sure I understand you correctly, but you shouldn’t be going back to precompute = True after steps 4 to 8. Also, imo I don’t think you should be spending too much time training with precompute = True nor even use it as a reliable benchmark for accuracy between models because in most cases you will need to do most of your training with precompute = False.
Thanks @jamesrequa. I was looking for an advice like yours.
I meant that accuracy of a model tuned with precompute = True (like 10 epochs with stepwise lr reduction and thats it) is ± the same as accuracy of a model trained with all these 8 steps. lr.find() and image size work well for me - I see their influence.
unfreeze did not work for me. I thought maybe thats because we are tuning models on a subset of images these models were completely trained on.
Indeed i did not play much with this multi - lr param, thanks will check it. Did it work for you in Dog Breeds?
I will agree with you that for this specific dataset for Dog Breeds since it is literally a subset of images from ImageNet so in this case unfreeze() won’t really help, in fact you may just end up hurting the Imagenet weights. However, I think this is a pretty rare case because in most challenges you face you will not be working with a dataset that was taken exactly the same from Imagenet. As long as there is any variation from Imagenet, then I think it probably helps to unfreeze and finetune layers. So basically to put it simply, its really just a matter of aligning these steps properly to the dataset you are dealing with.
To clarify in my first response I was really just speaking generally and not specifically about the Dog Breed challenge. I have used these steps on some other datasets already that I’m working with and so those were my main takeaways from that experience. For this challenge specifically, I personally think the key thing is to try to accumulate the most diverse range of “perspectives” of the data if that makes sense
Anyway, I tend to take an empirical approach to each problem, rather than going in with any pre-conceived assumptions I basically try everything possible which can sometimes result in some “surprises”.
My understanding: "Precompute = true doesn’t add or take accuracy. Its only about efficiency What happens is that in the lessons it was used before doing data augmentation and unfreezing, it “happened to cross by” to say it so…I find a bit confusing to talk about “results with precompute= true”, I think it would be clearer to say before data augmentation, or before unfreezing and retraining weights of the model
And yes, I completely agree that the dataset being a subset of imagenet is a strong condition for good performance almost “out of the box” of the model.
One last hint, about cycle length. ¿Have you noticed that you can try non integer numbers? (Like 1.5) Ive just been playing a bit with it but adds -even- more flexibility. (edit: not cycle length but cycle mult)
Sorry if I confused you. For me it is clear if you train your model with precompute parameter = true thats mean training only fc layers and no additional options affect your training process: neither data augmentation, nor unfreeze.
No I have not. What is your overall recommendation about cycle length and training a model in general?
Oh, cant really say much about training, almost all I thought I knew Im seeing that is outdated.
(This cycle splitting thing I was playing with it today and found it good looking)
I just tried this with cycle_len but got the below error…did you mean cycle_mult cause that does work! TypeError: 'float' object cannot be interpreted as an integer
@jeremy what would it even mean to do something like cycle_len=1 with cycle_mult=0.5 for example? I can’t quite wrap my head around it…hmmm I guess it would be halving the length of each cycle which is the equivalent of doing cycle_len = 0.5?
Oh, yes, my bad, I meant cycle_mult! Specifically the case when you just train cycle length = 2 and cycle mult =1.5 I found sometimes was ok when overfits fast.
I know some people are working on iceberg and cdiscount. I am personally working on passenger screening competition. Its been difficult because the data is not that easy to work with (3d body scans - although its possible to use 2d images taken from multiple angles) and while it is binary classification but it also requires localization/segmentation - predicting from 17 possible “zones” of the body where the threat(s) are located. While I did manage to rank in approx top 20 so far, but the rock stars at the top clearly know something I don’t as a few of them have near perfect scores with only a handful of submissions. (excluding the cheaters who hand-labeled)
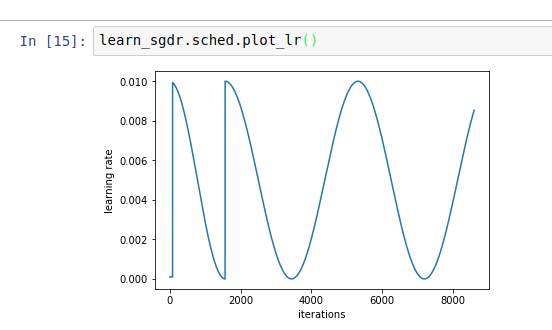
Something I discovered and just wanted to point out that if you are using a non-integer cycle_mult, do check the schedule plot. The math can actually give you an unexpected lr update schedule and the model might not be restarting at all. For e.g.,this is what I got with cycle_mult of 1.2:
I actually got adventurous and used 1.2. 1.5 might have been fine. But better to be careful with noninteger ones


 (I had already added an “edit” comment, in bold to the end of the comment, I think it’s all clear now…)
(I had already added an “edit” comment, in bold to the end of the comment, I think it’s all clear now…)