Hi,
I am trying to train a language model with the AWD-LSTM architecture were the inputs are actually tuples of words. The sentences have the exact same length and order but the vocabularies are different. Here are two images to show the idea. First, the architecture used in the course and second the architecture I intend to use.
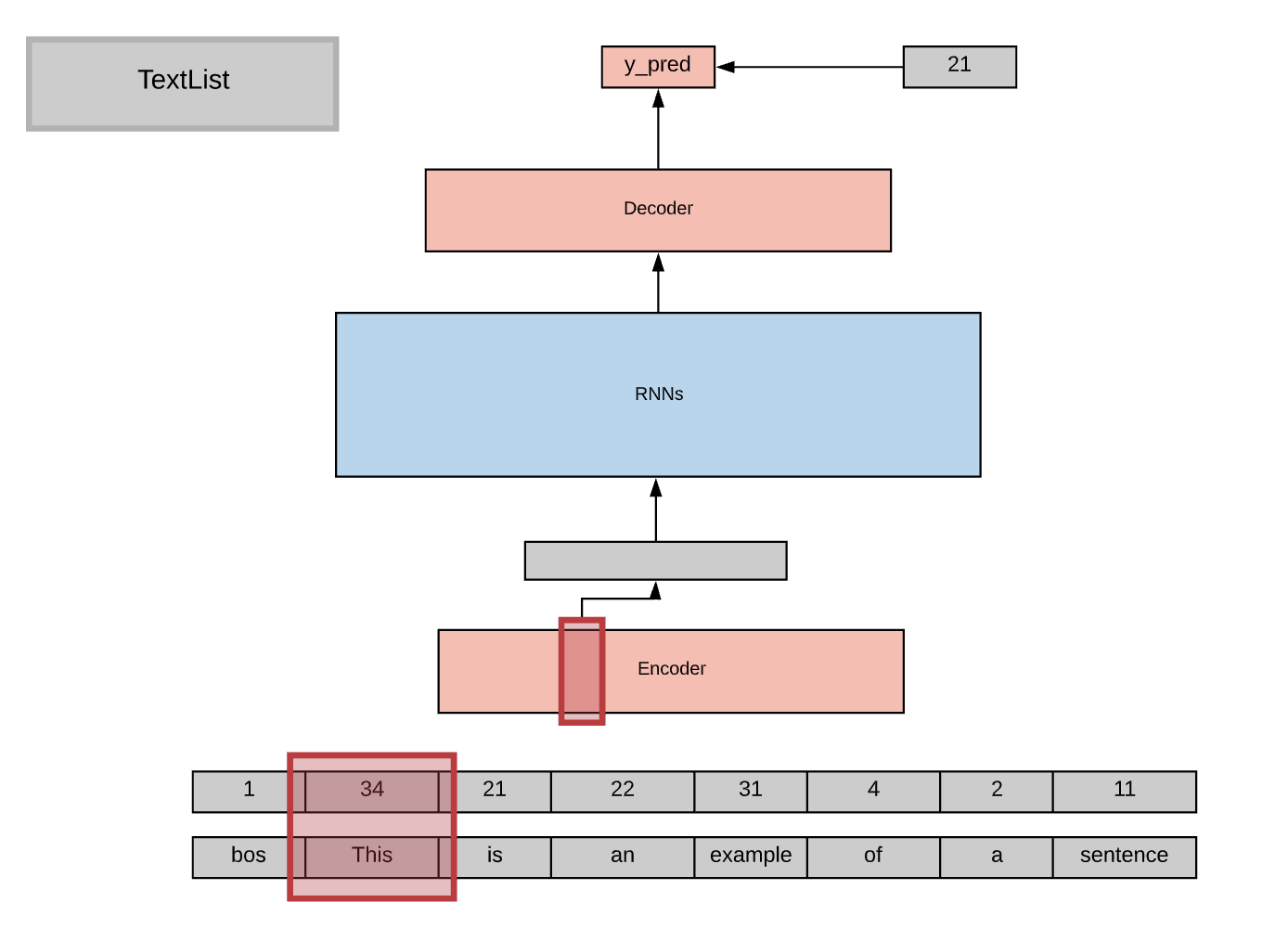
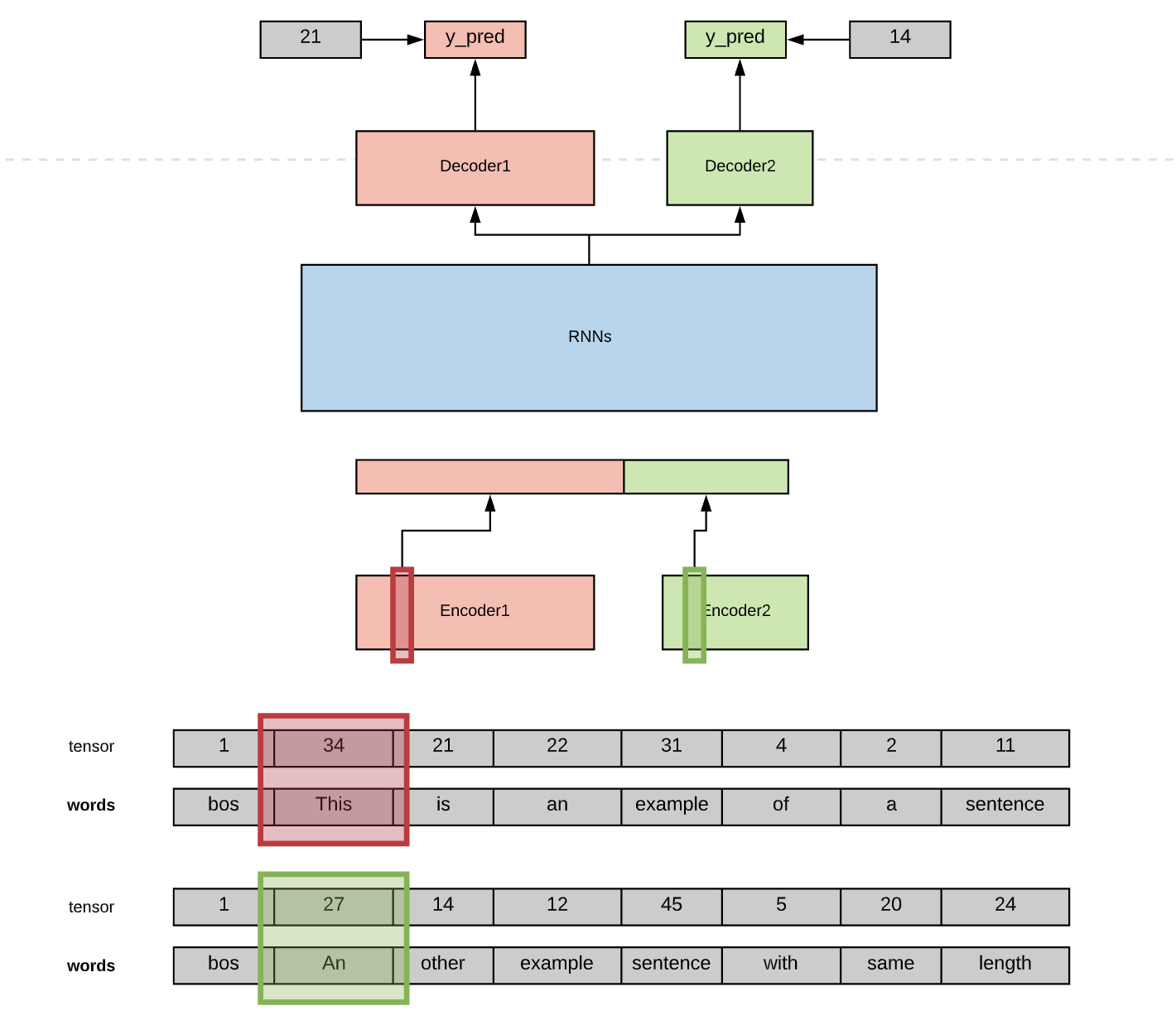
Here are a couple of related forum posts:
- Concatenating two textlists into databunches
- Productionizing Mixeditemlist alternatives for mixed-input-networks
- Tutorial on custom ItemLists
- FastAI Tabular-Text-Demo
Currently, I am struggling with creating the data in a suitable format. I started with a bottom-up approach where I created TextTuple and TextTupleList classes, but it seems that I would have to reimplement every method getting from a TextList a databunch for tuples.
Therefore, I now try a more top-down approach and create two separate DataBunch objects and try to join them into a single DataBunch with a suitable collate function similar to how it was done in fastai-tabular-text-demo.
Has anyone done something similar? And what would be the easiest approach to get this working? Maybe @sgugger has an idea?
Thanks a lot.
Best,
Robert
Here is some code, if this clarifies my problem:
def get_text_databunch(train_df, bs=64, cols='players', val_idxs=None, flm_path='.', num_workers=1,):
return (TextList.from_df(train_df, cols=cols)
.split_by_idx(val_idxs)
.label_for_lm()
.databunch(bs=bs, num_workers=1, path=flm_path)
)
my_tokenizer = Tokenizer(pre_rules=[], post_rules=[])
my_tok_proc = partial(TokenizeProcessor, tokenizer=my_tokenizer)
TextList._processor = [my_tok_proc, NumericalizeProcessor]
LMTextList._bunch = TextLMDataBunchNotShuffled
seed = 42
valid_pct = 0.1
if seed is not None: np.random.seed(seed)
rand_idx = np.random.permutation(range_of(actions_list_df))
cut = int(valid_pct * len(actions_list_df))
val_idxs = rand_idx[:cut]
data_lm_txt1 = get_text_databunch(txt_list_df, bs, 'txt1', val_idxs, flm_path)
data_lm_txt2 = get_text_databunch(txt_list_df, bs, 'txt2', val_idxs, flm_path)
Then I try to concatenate the DataBunches into a single one similar as in
bptt=70
backwards=False
val_bs = bs
train_ds = ConcatDataset(data_lm_players.train_ds.x, data_lm_actions.train_ds.x,
data_lm_players.train_ds.y, data_lm_actions.train_ds.y)
valid_ds = ConcatDataset(data_lm_players.valid_ds.x, data_lm_actions.valid_ds.x,
data_lm_players.valid_ds.y, data_lm_actions.valid_ds.y)
datasets = [train_ds, valid_ds]
datasets = [LanguageModelPreLoader(ds, shuffle=False, bs=(bs if i==0 else val_bs), bptt=bptt,
backwards=backwards) for i,ds in enumerate(datasets)]
train_sampler = SortishSampler(data_lm_players.train_ds.x, key=lambda t: len(data_lm_players.train_ds[t][0].data), bs=bs//2)
valid_sampler = SortSampler(data_lm_players.valid_ds.x, key=lambda t: len(data_lm_players.valid_ds[t][0].data))
train_dl = DataLoader(datasets[0], bs//2, sampler=train_sampler)
valid_dl = DataLoader(datasets[1], bs, sampler=valid_sampler)
data_dummy = TextLMDataBunch(train_dl, valid_dl, device=defaults.device, collate_fn=texttuple_collate, path=flm_path)
where
class ConcatDataset(Dataset):
def __init__(self, x1, x2, y1, y2): self.x,self.y = (x1,x2),(y1,y2)
def __len__(self): return len(self.y)
def __getitem__(self, i): return (self.x[0][i], self.x[1][i]), (self.y[0][i], self.y[1][i])
def texttuple_collate(batch):
x,y = list(zip(*batch))
x1,x2 = list(zip(*x)) # x1 is player_id text, x2 is action_id text
y1,y2 = list(zip(*y)) # y1 is next player_id text, y2 is next action_id text
x1, y1 = pad_collate(list(zip(x1, y1)), pad_idx=1, pad_first=True)
x2, y2 = pad_collate(list(zip(x2, y2)), pad_idx=1, pad_first=True)
return (x1, x2), (y1, y2)