Using the notebook from the 2019 Part 2 course where Jeremy trained a retinanet object dector using the Pascal 2007 dataset, I tried to make an object detector of my own. I have changed a few things to make it work for my purposes. 1: I replaced the resnet model from the notebook with resnet18 (I haven’t changed the retinanet split, could this be a problem? Edit: resnet50 doesn’t make a difference). I have of course also changed the databunch to my own data.
After getting poor results where the bounding boxes are way too large, I tried normalizing using imagenet_stats as I thought this could differ from the Pascal dataset but this seemed to have little effect. My loss is steadily going down and with the loss function from the notebook and I achieve less than 1 (about 0.6).
Altogether I am training on about 150 images from my own hand-labelled dataset. Could the dataset size be the problem?
I have been trying to do the same thing as you. However, when I get to the actual training part with the bounding boxes, it requires an absurd amount of memory and I can’t run it, even on an AWS server. Do you have any idea how to combat this?
@tango Thanks, I’m an idiot and forgot to size down the images.
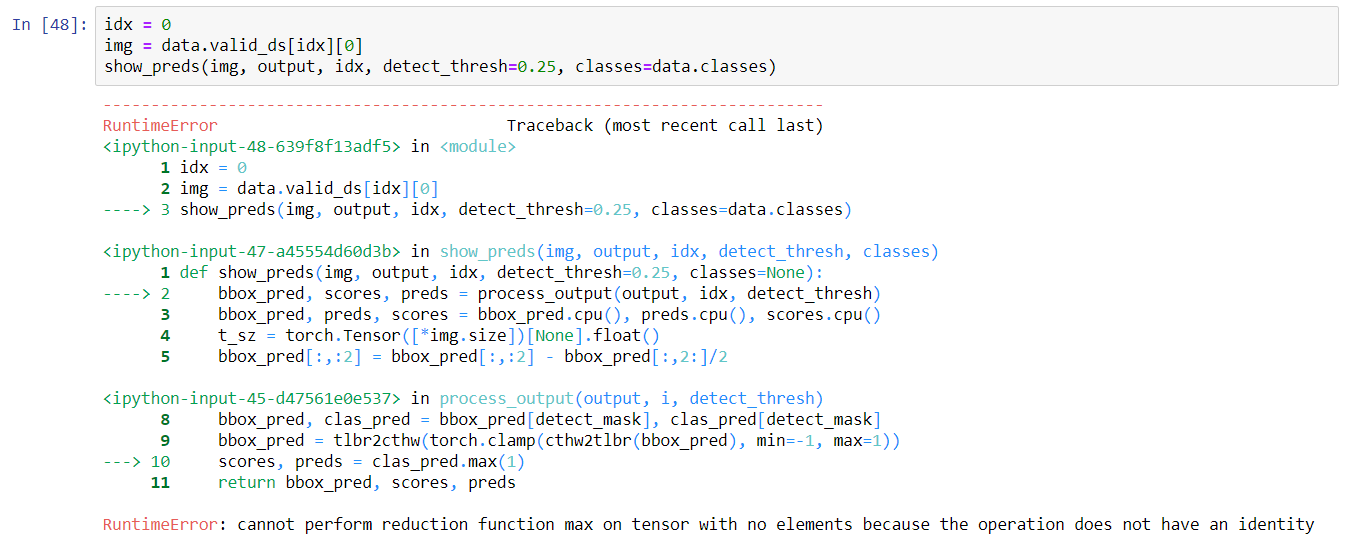
Which brings me to my next issue. I was able to train a model (still had high losses of about 3.5 each) but now I am unable to view any predictions.
When I run show_preds(img, output, idx, detect_threshold=0.25, classes=data.classes , I get the following error.
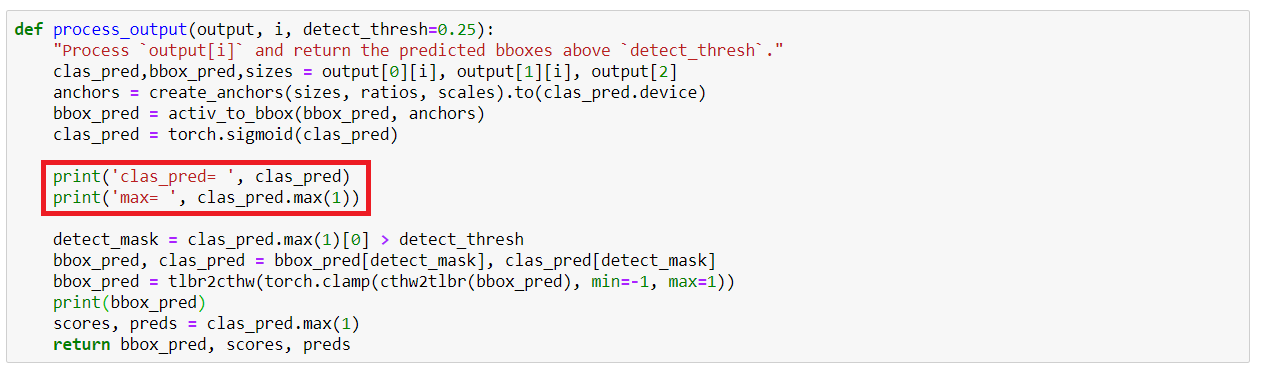
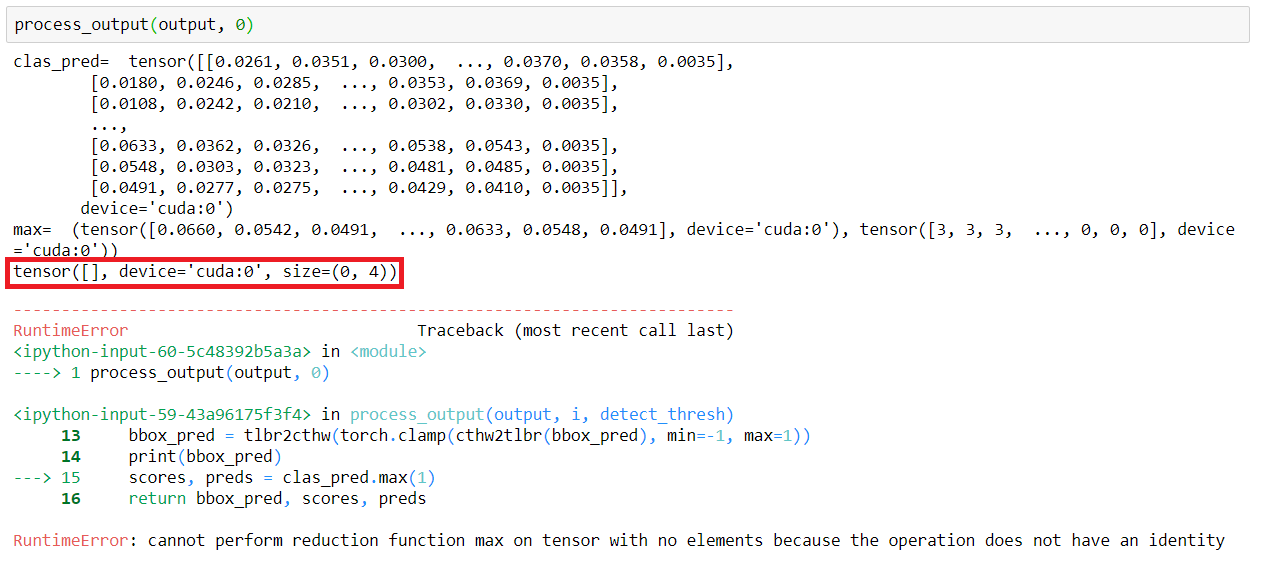
So I figured that changing the threshold to something lower would find these prediciton values as they are all under .25. Changing this to 0.07 was the highest I could go without throwing the RuntimeError. However, doing this makes the kernel run forever with no output as shown below. Interrupting it kills the kernel every time.