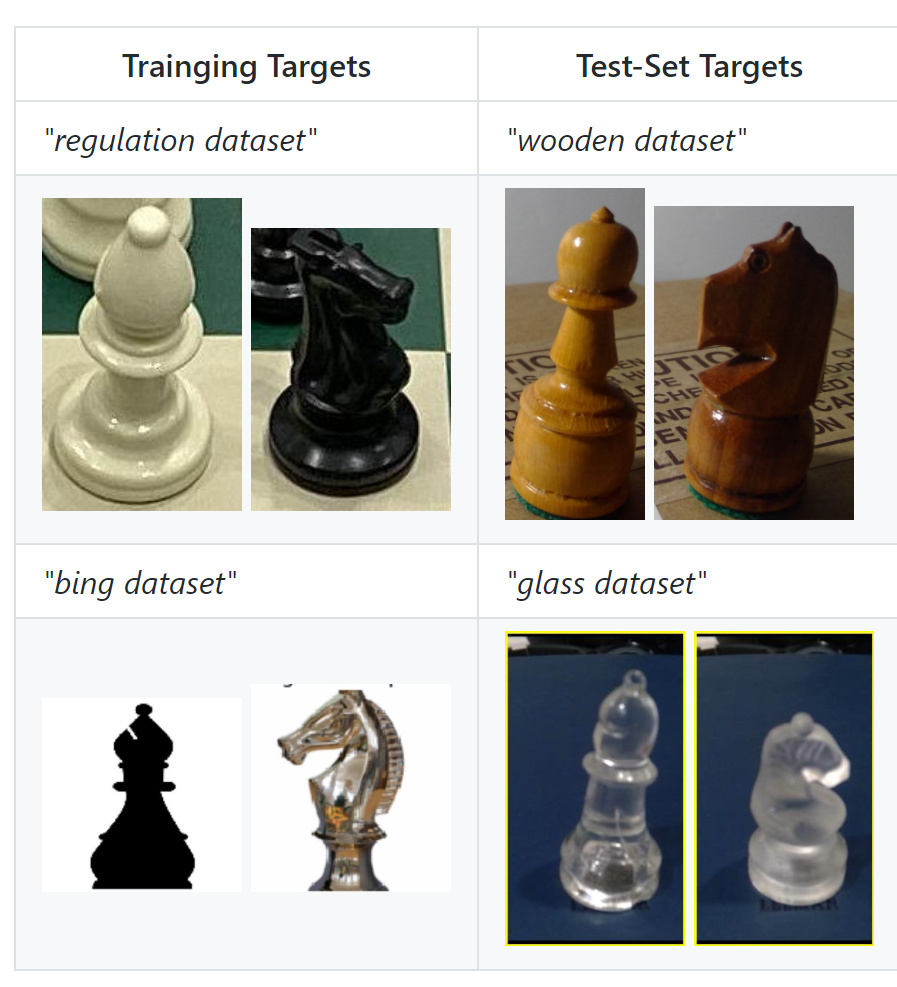
I am building a chess piece classifier on an existing regulation piece dataset* and want to apply this model to my own chess set which is non-regulation (see examples below). How would you go about doing it without having a dataset built for the non-regulation pieces?
So far, the regulation dataset trains with > 99% accuracy on validation through simple “lesson2 means”, but when applying it to my wooden pieces, the accuracy drops below baseline. How to make this image classifier more generalize-able? See my git repository for notebooks and details.
Speculations, Links, Hacks, Tips & Tricks, all welcome…
Training on the “Regulation Pieces” still isn’t working…however training on Bing Image Search datasets of e.g. “bishop chess piece” can help identify the Rook, Knight, and to some degree the Pawn class (the Bishop, Queen, and King remain unsolved).
The reason for this is there’s more variety built into the Bing Image dataset, which should let out model generalize better.
I’m beginning to think this task can’t be solved, except “relatively” (e.g. which of all the pieces is most “king-like”). For my wooden pieces, the King piece lacks a cross on the top, which appears to be the most universal way to designate a piece a king.
One other thought I’m having is to look at solutions to Quickdraw (“Doodle Recognition”) where we’re trying to match images which are meant to be “glyphs” or symbols, similar to the way chess pieces are.
How many images of each class did you download from Bing? Did you use these + your regulation set? Or just the Bing images? The more data the better (as long as its relatively clean). Your King and Queen do look quite different to the usual ones I have seen though so it might be tricky to get those correct by the looks of it, but you never know, give it more training samples for those two classes especially and see if you get anywhere
I was using default 150 images / per class from Bing, but roughly half of those are wrong - either a picture of multiple pieces or a piece too custom (like a statue of a wizard instead of a bishop), that I’ve cleaned them up.
I think you have a fairly hard problem here. I am not someone who has played a lot of chess, but have definitely seen a few sets. I have a hard time identifying these, so I think it is a bit understandable that a neural net would have a hard time. To me every single one of your pieces could be a pawn or bishop, except for your knight which is fairly obvious.
I think you are simply missing the data needed for this problem. I don’t think it is possible for a neural net to generalize from regulation pieces to your wooden set. More bing images will probably help, but still may not get you to where you want to be, as this looks like a really hard problem(I am not confident I could do it).
An idea on how to set this up as a “comparison” problem, would be to splice together 5 images of random order into one image, with the neural net being responsible for predicting the class of the left most piece. It could then reference all 5 images in order to make a prediction on the left most one. I think this would allow it to have a fair shot, if it isn’t too difficult to implement. Whether this is acceptable to you is another problem of course, as it greatly limits the usefulness of the model.
Also, I have realized that you might have a training/validation split problem. If you want the model to be able to make predictions on chess sets that are in your test data, but not in your training data, then the chess sets in your validation data need to also not be part of your training data. It is just like when you split time based data into past and present, to see if your model can predict the future. If your model already knows what the far future looks like, then it doesn’t have to do much to predict the near future. This explains why your test accuracy is so much lower than your validation accuracy, which should never be the case unless you split your data incorrectly or something similar. (I am unsure of where you are doing training/valid split, so having trouble validation that statement)
I think a line similar to this is how you are splitting your train/valid data:
splitter = RandomSplitter(valid_pct=0.2, seed=42)
So yeah, I think the very first thing to do is to have a regulation chess training set, a glass chess validation set, and a wooden chess test set. This should get your validation and test error lining up correctly, so that you can stop training before you start over fitting. (also more data will help)
It might be useful to look into the literature on domain adaptation, since that’s essentially the problem you’re facing. If you’re not already, I’d suggest pushing the data augmentation to the max since you’re working with so few images. I’d even look into some methods of synthetic data creation (via GAN or otherwise) to add to your training data set.
I would start with analysing the predictions - plot a confusion matrix for the set and by class. Then look at the pictures it got right/wrong TP/TN/FP/FN.
Is it one class it isn’t predicting well? Is it overly confident on one class over other classes? Is one class under-represented?
Then look at the pictures it is sure about/isn’t sure about. This will give you intuition on what you need to do next, i.e. balance the # of images, focus on particular class, augment images in certain way - lighting, colour, etc, calibrate prediction threshold.
If you find the network is overconfident in certain cases or overall you can try label smoothing if you don’t have the option of manipulating your training set but I would recommend more diverse and balanced data over network and training hacks.
Easy way to fix this is to pull images off the internet of other chess datasets that are of different materials. I just don’t think there is much variation in the dataset.
Hey all, thanks for these great tips. Updates and responses below…
William - good pointing out the term of the art for what I’m doing, Also, I’m going to be be looking more at data augmentations, perhaps while concentrating on an easier question…using the white pieces to predict on the black pieces.
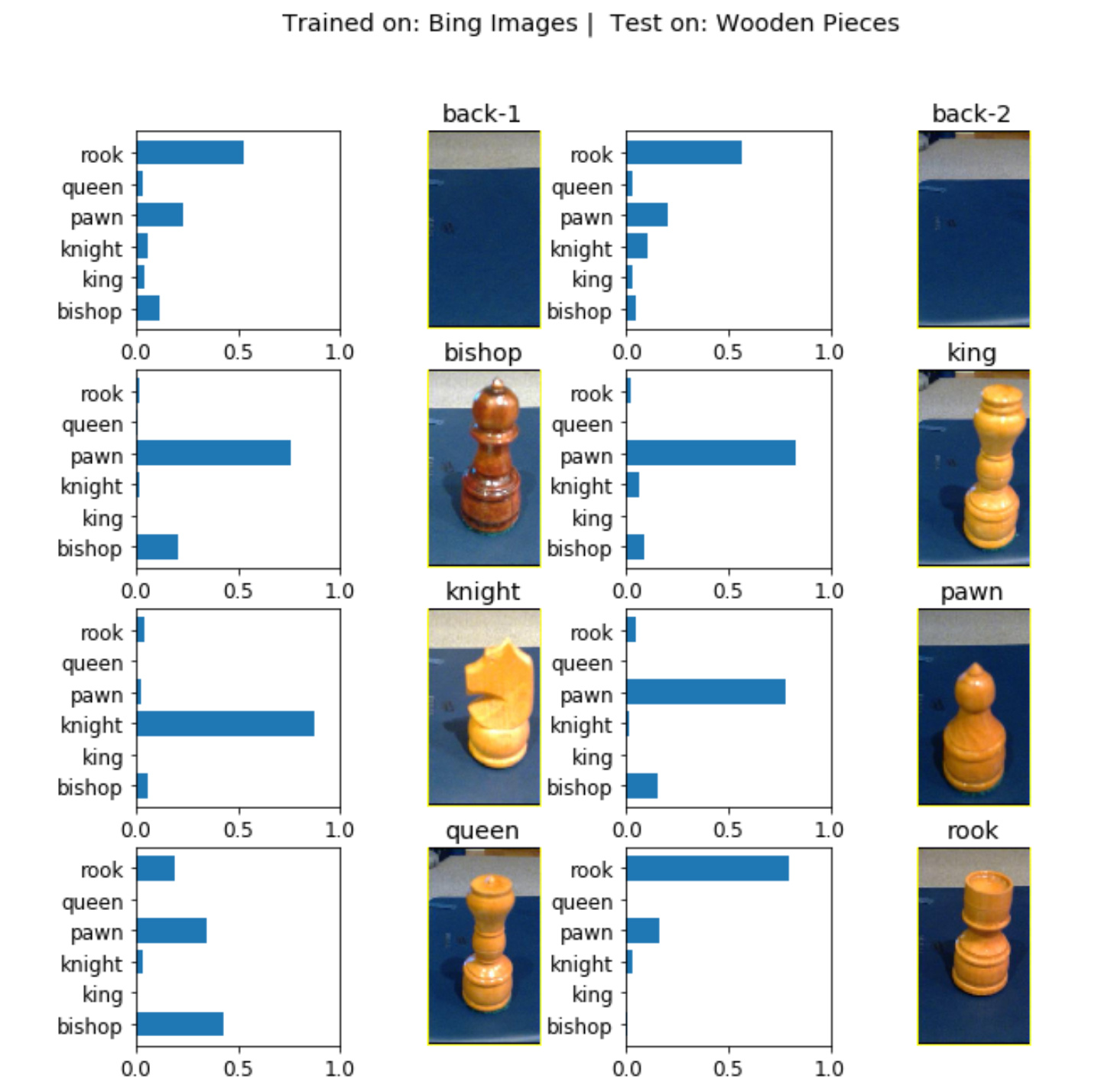
Maral - good points and the confusion matrix for the random images from internet is actually not bad, see (2).
Molly - I’ve got the Bing2 dataset (1) trained and it does pretty well (2). This is after a pretty heavy cleaning (~33%) eliminating all types of extra whacky* pieces and images that include multiple pieces. I think I just get somewhat unlucky with my own sets - a distinguishing mark of the bishop is the gash in his hat, and for the king is his cross, the queen her ringed crown, etc…my wooden one doesn’t have any of these while most random pieces on internet - while non-standard - do have these.
So you can see from the matrix there is a problem with king/queen followed by pawn/bishop. Double click into these to understand how far the probability was from the decision boundary (0.5) relative to the correctly classified in the same pair (plot the correctly classified probabilities versus the incorrectly classified probabilities on a histogram). This will give you some indication how far off the network was from getting it right. And if you were to alter the threshold what would it do to the overall results? You can also learn the thresholds using isotonic regression.
Also visualise the incorrectly classified set against the correctly classified set for the given class pairs to determine if there is a particular style of image the network is confused about and proceed from there. Keep in mind you will need a test set otherwise these post-processing methods will just fit to the validation set and won’t generalise in the real world.
This is a completely off of the cuff idea, so don’t beat me up over it. LOL Perhaps you could try a siamese network that outputs two classifications, and an output if they are the same pieces (traditional use of siamese network). The network would have to learn to classify each piece and also correctly identify if they are the same types.