While training on some dataset for image classification, I noticed that the train_loss while training is more than the actual train_loss.
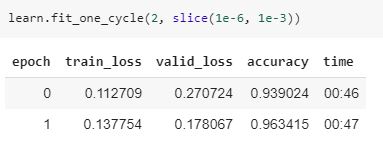
This is the train_loss and validation_loss at training -
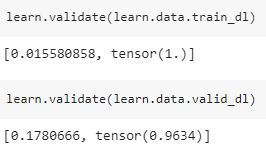
Here the train_loss is 0.137 and validation loss is 0.178, but when I validate the model on the train set and the validation set I get a different loss for training set -
When I validated I got the train_loss as 0.0155 as opposed to 0.137 when training, on the other hand, validation_loss in same as that at the time of training.
What happens is that for the start of training, the model gets better at predicting, and more confident (correctly) of those predictions, so accuracy and loss both improve.
But eventually, additional batches only make it slightly more accurate, but much more confident, such that that over-confidence causes loss to get worse, even as accuracy improves.
Since what we actually care about is accuracy, not loss, you should train until accuracy starts getting worse, not until loss starts getting worse.
There are two modes a pytorch model can operate in train() and eval(). And it affects how some of the modules behave (most common affected by this are Dropout and BatchNorm).
In the train mode dropout makes things harder for your network so it can learn to generalize better, but when you call validate() it runs in the eval mode that’s why your loss is smaller then. The validation set is always checked in eval mode so you get the same value.
You can see for yourself in the fastai code that setting the mode is the first thing validate does
Here’s yet another theory. Training loss is computed during the training of that epoch. Validation loss is computed at the end of the epoch after updating weights.
When you later compute training loss, that calculation is done with the updated weights. So validation loss will be the same, and training loss is going to be different, usually lower.
That has been my “mental model” of this observation, though to be honest I have never tested it. I would really appreciate if you would test these various theories by tracing and experiment, and report back what is actually true. Maybe it’s a combination of effects.
I don’t think that would be the case. If that were the case, then the difference between the losses while training and while validating wouldn’t have been this much.
What I think is that the train_loss while training is the loss of the particular batch of images that were passed in the model at that time, whereas when we calculate the train_loss at the time of validation, then the loss is on the whole training dataset.
The training loss displayed during training is a moving average of the collected losses during training, so it has some traces of the beginning of training when the model was bad. Also it’s computed in training mode, which means dropout for instance, that will hurt it.
The training loss computed in validate is computed in eval mode (so no dropout) and is the average of the losses over all the batches. So it’s lower for those two reasons: no trace of bad weights at the beginning of training and no dropout and the like.
After Sylvain’s reply, I see that my theory is off the mark. It would apply only for one batch per epoch training, in which case the later training loss is computed on updated weights vs. on pre-update weights. That’s the situation I had been working with directly in PyTorch.
With multiple mini-batches (your example), you would have this discrepancy only for the last mini-batch.
On another note, I notice that your training loss is lower than your validation loss on the very first epoch, and by a large margin. I think this would be an indication that you may have a bug in your code as well. Since the training set has only been shown to the model during training, it has not had a chance to become even close to overfitting, and should be substantially worse than the validation loss because of the moving average.
Some things that can cause this:
Bad train/valid split.
Normalizing data incorrectly by the wrong stats.
Maybe, you are just loading weights from a previous training, and this is completely irrelevant.
Yes, the training loss in much lower than the validation loss, but that is probably because its not the first epoch. I ran some epochs before that. It might be overfitting here.