Hi,
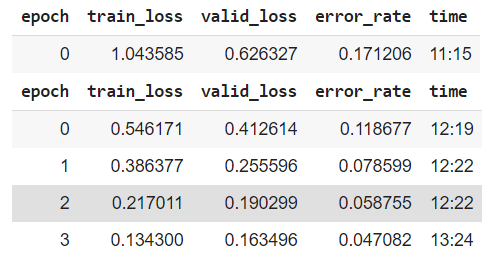
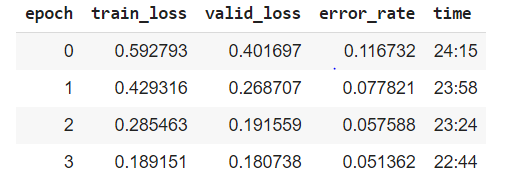
I am using colab-pro for creating models. After working with the Lesson_02, I just tried with my own dataset which contains 6-classes of objects. Total images I have is around 4000. I tried to run the same code on GPU and TPU separately and got the observation as attached.
Somebody in an older thread here, said that we need to use a certain code for running our code on TPU. If that is the case, can somebody please help me with that.
kinda like @Marceline said, fastai 1 and (more specifically) the version of pytorch it used did not “do” TPUs. I’m not aware of that being different now.
It would make sense to me that you were seeing that behaviour because TPU instances on Colab were coming with pytorch/xla installed, but looking at the github history on pytorch/xla, the last changes on the colab notebooks were 2 months ago to make sure everything worked with their new installation method, so it would appear not.
I’d expect TPU to be a fair bit better than 2x faster (although iirc you can actually go as far as getting worse performance of TPU if your batch size is too small).
not sure though. you still can’t get Colab Pro outside of USA so i can’t play with it. #sulking