I am collecting data by scrapping the Dell community support forum website, as I plan to use questions and answer pairs to fine-tune a LLM. However, a lot of the forum posts use “< tables >” within the answers (i.e., table containing list of supported software). I will be exporting these as CSV later to train. So I am thinking to:
Skip posts that contain tables, but worried many posts may use tables
Use a placeholder like [TABLE] , but will lose info and not sure how LLM fine-tuning would handle it such as spitting out [TABLE] as an answer when prompted
Sanitize, extract the contents of the table as a text, but this adds complexity
At least some LM’s can read data from tables if table formatted data was included in the training set. Here is an example of me pasting in a table from wikipedia and it correctly answering questions about it. https://chat.openai.com/share/1f559d8f-2070-4f61-a0c8-007598daedb9
As you can see there is a pretty bad lack of formatting for the table I pasted but it still worked. A csv, markdown or html table would probably be even better.
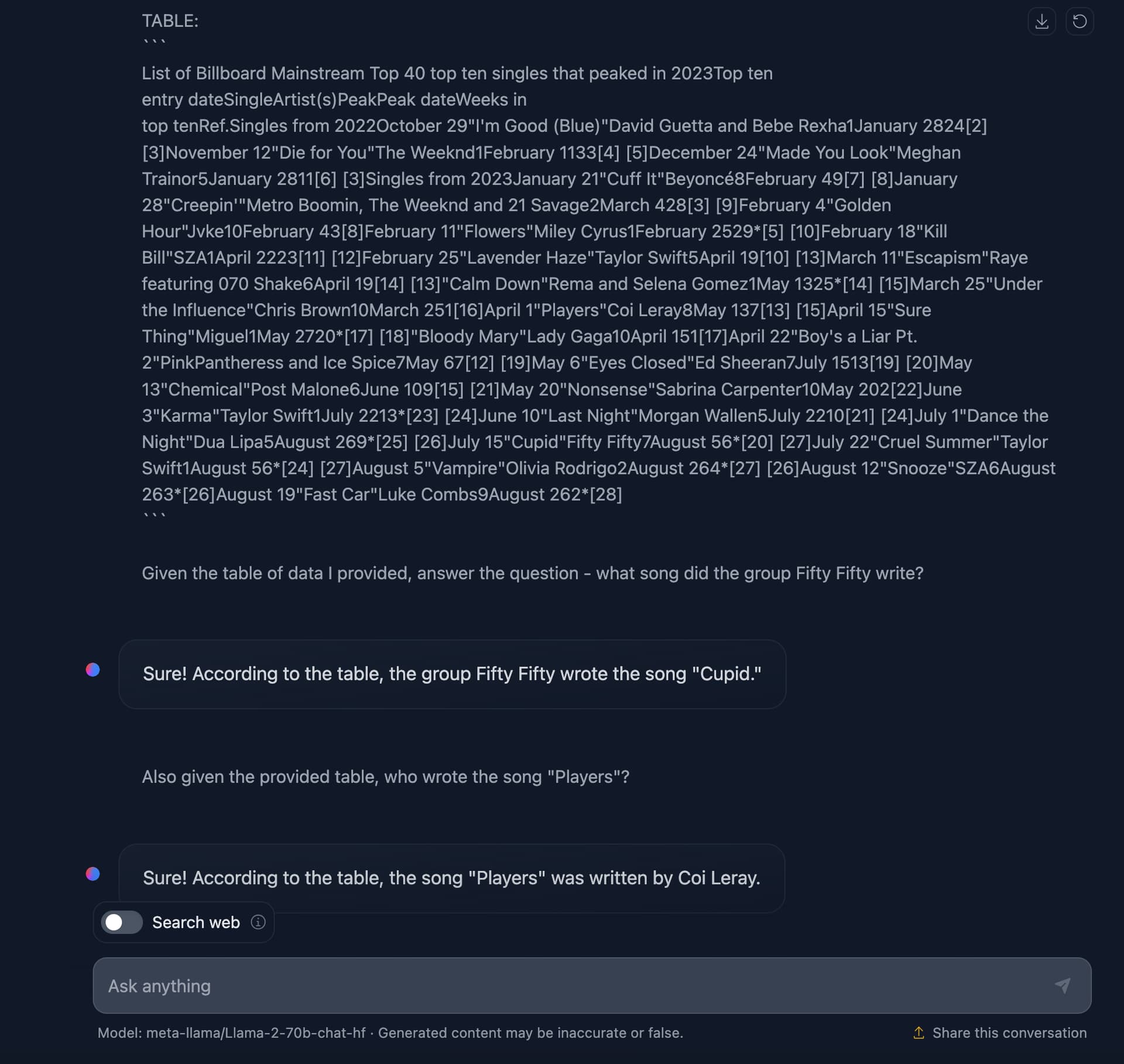
Here is an example from Huggingface chat using the Llama model:
Thanks for the response, yep I have decided to go for the third option and use the table info, even if its not formatted as a table. Also a lot of posts used images (ie., screenshot of an error), so using [IMAGE] as a placeholder for that!
Depending on how many have images it might be worth OCRing them and adding that text too. If it’s unreasonable (for a person) to answer the question without having the text from the image then you should probably either remove all items with images or ocr all of them. Training it to guess based on a lack of information is probably not what you’ll ultimately want it to be doing.