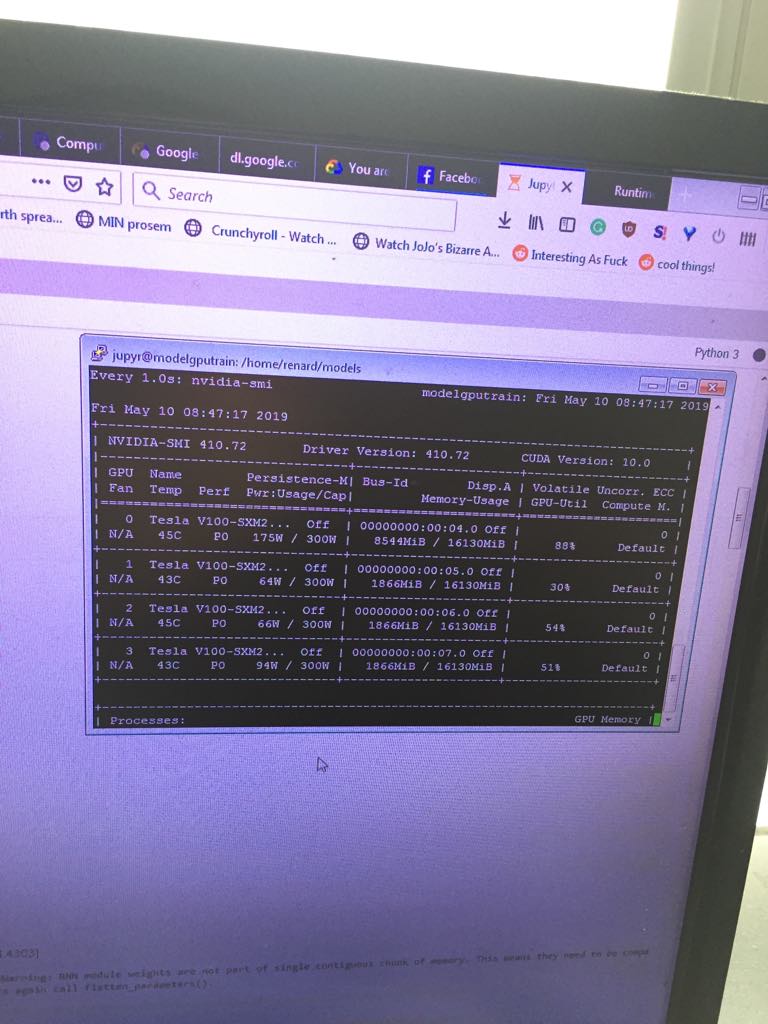
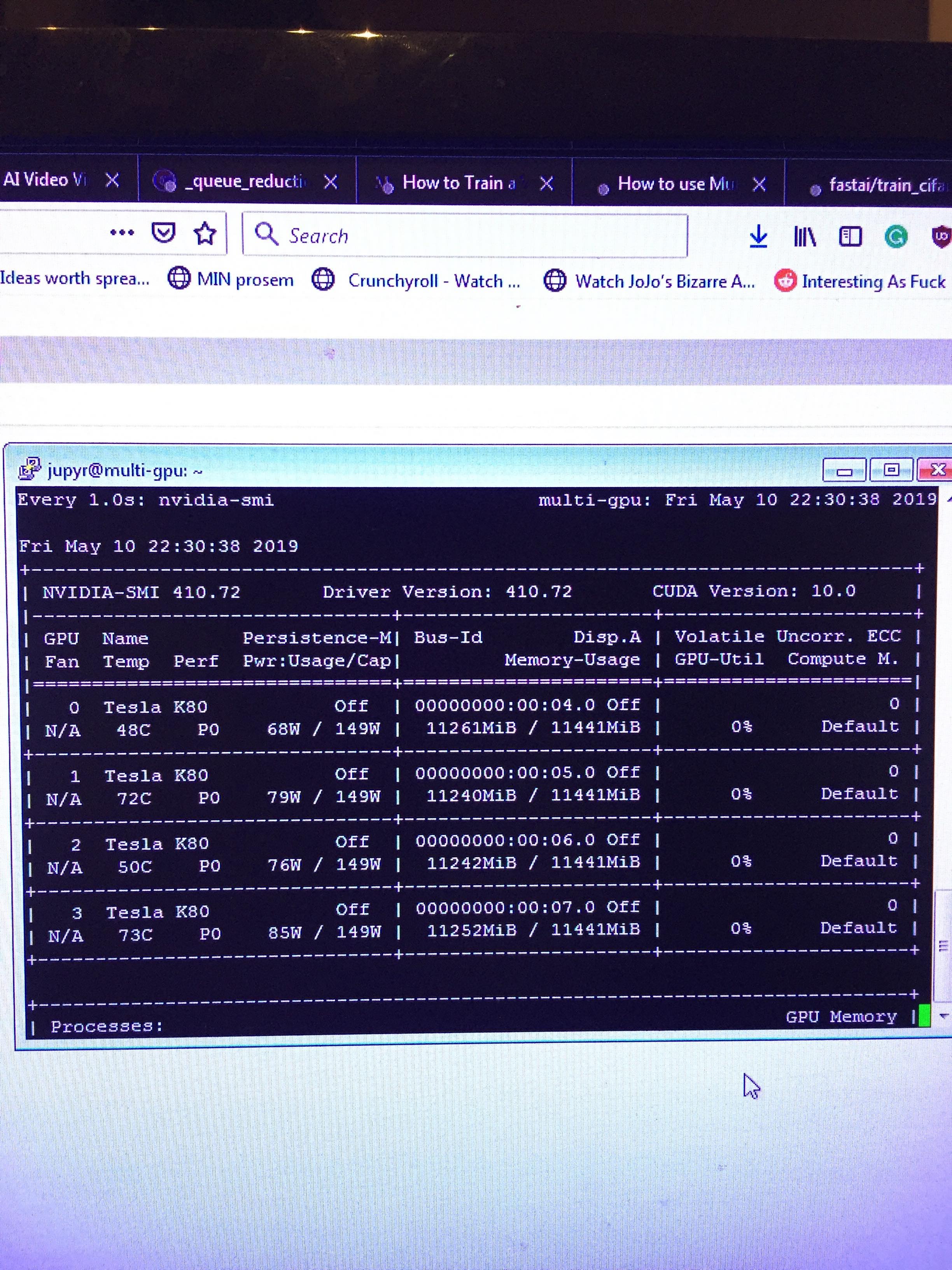
After following tutorial “How to launch a distributed training”, I applied it to language_model_learner() and it failed. I think I have apex installed by not pytorch_nightly. Here is the error (even with one GPU:)
Traceback (most recent call last):
File "distrib_lm_2019_04_29.py", line 149, in <module>
learn.fit_one_cycle(10, slice(1e-2), moms=moms)
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/fastai/train.py", line 22, in fit_one_cycle
learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/fastai/basic_train.py", line 199, in fit
fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/fastai/basic_train.py", line 101, in fit
loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/fastai/basic_train.py", line 34, in loss_batch
if not skip_bwd: loss.backward()
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/torch/tensor.py", line 102, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/torch/autograd/__init__.py", line 90, in backward
allow_unreachable=True) # allow_unreachable flag
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/torch/nn/parallel/distributed.py", line 445, in distributed_data_parallel_hook
self._queue_reduction(bucket_idx)
File "/home/dludwig1/anaconda3/envs/fastaiv1/lib/python3.6/site-packages/torch/nn/parallel/distributed.py", line 475, in _queue_reduction
self.device_ids)
TypeError: _queue_reduction(): incompatible function arguments. The following argument types are supported:
1. (process_group: torch.distributed.ProcessGroup, grads_batch: List[List[at::Tensor]], devices: List[int]) -> Tuple[torch.distributed.Work, at::Tensor]
Invoked with: <torch.distributed.ProcessGroupNCCL object at 0x7f87991040a0>, [[tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0', dtype=torch.float16), tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0', dtype=torch.float16), tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0', dtype=torch.float16), tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]], device='cuda:0', dtype=torch.float16), None, tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0', dtype=torch.float16), tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0', dtype=torch.float16), tensor([-2232.0000, 13.0703, -33.2812, ..., 14.1641, 13.2656,
13.6797], device='cuda:0', dtype=torch.float16)]], [0]
I may need to update versions of fastai and/or pytorch, but so far nothing on the install page has worked.