By doing so, I’m getting this error : “There are nan values in field ‘Fare’ but there were none in the training set. Please fix those manually.”. It makes sense but I thought using processors such as FillMissing should take care of this problem.
Can anyone clarify what processors do exactly and how they transform the training, validation and test set ?
Sorry I can’t help but I have a similar question to yours. I’m wondering how we set up our test set to have the same normalization and cat / cont variables. I tried to use tabular list and I tried to use .add_test() and neither worked.
When we run learn.predict(test_data), what are we putting in as the test_data parameter?
From what I understand, learn.predict takes a single item as a parameter, so test_data is a single fastai item ItemBase that can be one of the provided 3 basic types or your own custom type (https://docs.fast.ai/tutorial.itemlist.html#Creating-a-custom-ItemBase-subclass)
I think you can create this item manually by calling something like : test_data = Image(<Tensor>)
Still wondering how to add the test set so that it is processed just like the training set. I tried using add_test with a pandas DataFrame, but then I get an error when using learn.get_preds
The error message is actually very clear, but to make it a bit more precise maybe add : There are nan values[in your test set]in field ‘Fare’ but there were none in the training set. Please fix those manually.
Since the training set does not contain any NaN values, the processor is not doing anything. But, when it finds NaN values in the test set, it can’t process them because it didn’t find any before. It just doesn’t know what to do and how to deal with it
2 solutions then :
Replace manually every NaN values in the test set with a selected FillStrategy as the message suggests
Add a NaN value in the training set so that it knows how to deal with them
Then the processor will be applied the same way on both sets.
Hi Thomas,
Pls avoid putting procs=procs in data_test and try with this…
data_test = TabularList.from_df(test, path=path, cat_names=cat_names, cont_names=cont_names)
Im getting an error now ‘PassengerId’ TypeError: an integer is required
my cont list is [‘PassengerId’, ‘Age’, ‘Fare’]
and my cat_list is:
[‘Pclass’, ‘Name’, ‘Sex’, ‘SibSp’, ‘Parch’, ‘Ticket’, ‘Cabin’, ‘Embarked’, ‘Age_na’]
I ran the TabularList.from_df() as suggested by @sanjabh, but to no avail.
Any ideas. Its seems to be a problem with the continuous variables in the test data frame.
I think you can remove PassengerId from cont_names since it doesn’t have an impact in accuracy. Otherwise, when calling pd.read_csv, you can specify an attribute : dtype = {“PassengerId”: np.int32} because if you don’t I think it autoconverts it to a float
Hey thanks Bernd that was a great example of putting the test set into the databunch, that really helped.
I gues my question is:
If we somehow dug up a new titanic persons data and we wanted to run a prediction against them, what would we need to do to get the learn.predict() to work.
I ran the model with the test set and I kept 1 row of the test set saved as prediction_df. Once I run the model I want to run the learn.predict against prediction_df but it isn’t letting me. What do I have to do to it so that I can predict against it?
So I have gotten the test set to work fine and that is all peachy.
My problem is that in real life we would then take this model and we would have it run against a completely new row of data and produce a prediction against that data. Imagine we found new data on titanic passengers and we wanted to predict whether they survived or not.
What I want to work out is how to run learn.predict() on a new row and produce a result.
I have taken 1 row of the test set and held it aside in predict_df and then after I have run the full training I want to run the model against predict_df. This is where I am stuck.
I tried to vary the layers in learner model and lr , but it doesn’t really help. I just wonder if you guys have any better method to handle this as the leaderboard has score 1. Do you know if they use stacked ML models as suggested in one of the kernels (https://www.kaggle.com/arthurtok/introduction-to-ensembling-stacking-in-python)
are there any ways we can do better with fastai model?
Hi! I also want to improve my score. With a basic fast.ai tabular model I get a public score about 0.77***
Changing the number of training epochs and the layers sizes doesn’t really improve.
I added three boolean feature on the price-category of the fare.
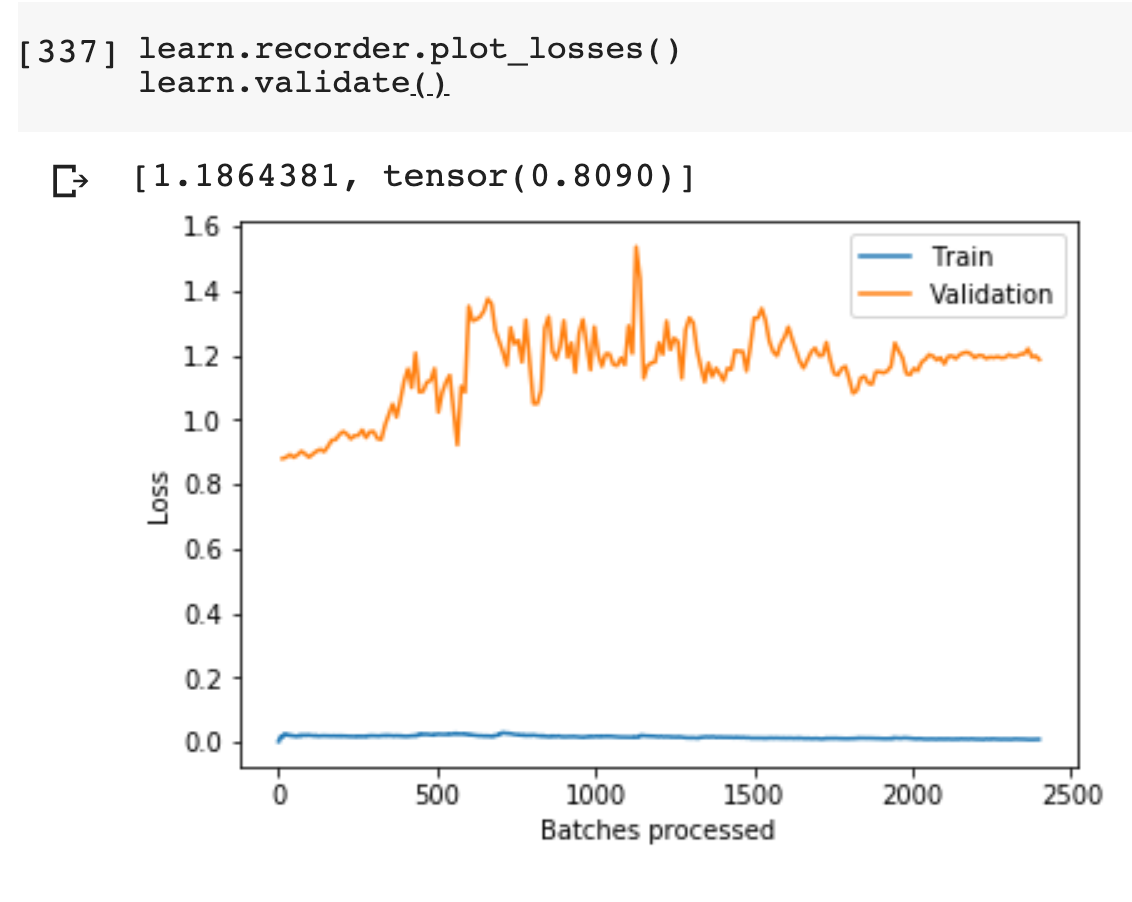
I think the validation curve is really bad, isn’t it? Validation error only oscillates but doesn’t really go down while doing 200 epochs. (Similar curve with 100 or 20 epochs)