Thanks for your help. Yes, with larger lr in 512 batch size cases, the loss reduces more rapidly. I change from 2e-5 to 1e-4.
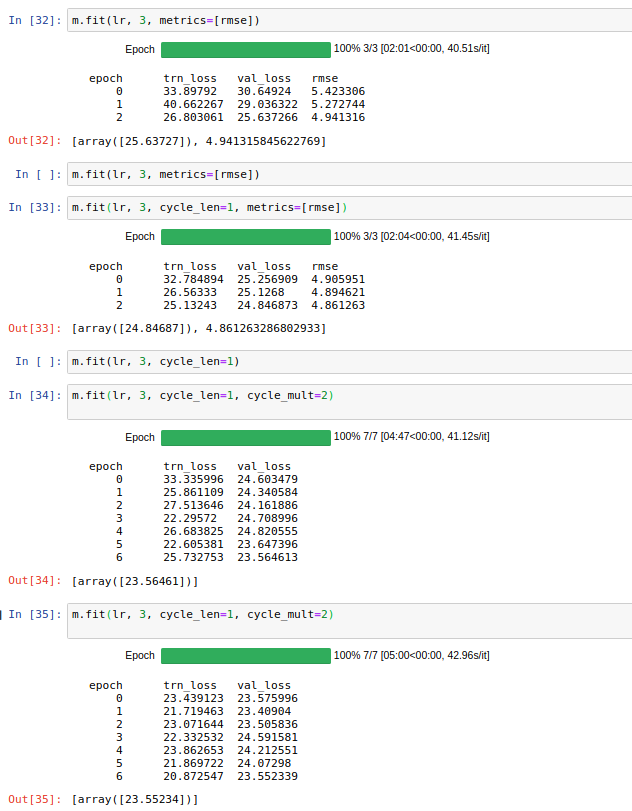
I stop training at that stage because the model is overfit already. In the picture above you can see that when I continue to train, the val_loss doesn’t reduce anymore.
I also find discussion about this topic here: relation_between_learning_rate_batch_size. One says that:
There’s a performance tradeoff inherent in batch size selection–a larger batch size is often more efficient computationally (up to a point) but while that might increase the number of samples/s you process, it also can mean that the number of SGD iterations you take /s decreases. It currently seems that with deep networks it’s preferable to take many small steps than to take fewer larger ones (again, this is a design tradeoff that requires experimentation to nail down optimally for any given dataset/net)
He explains that small batch-size can also lead to converge rapidly because it has more iterations