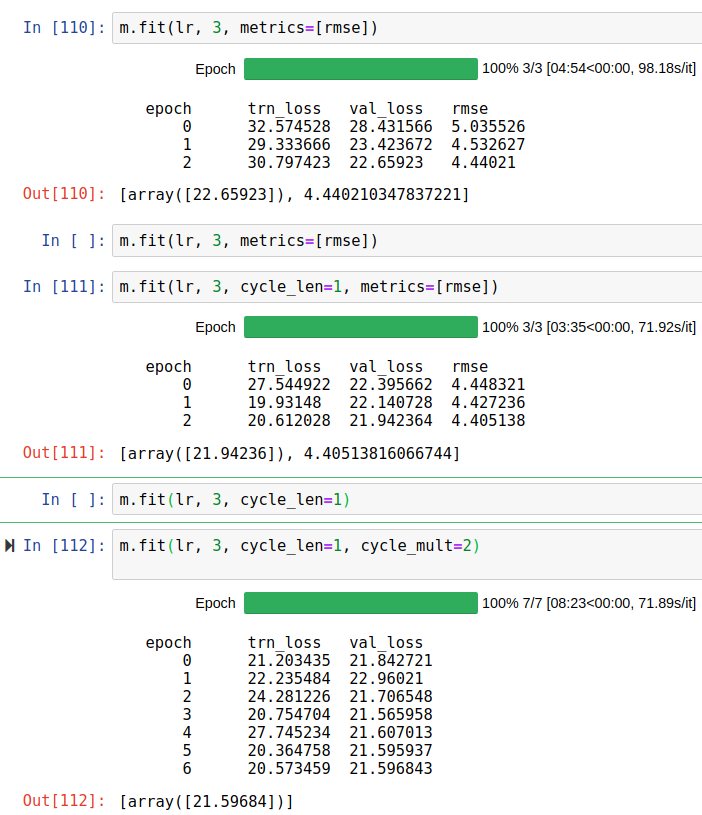
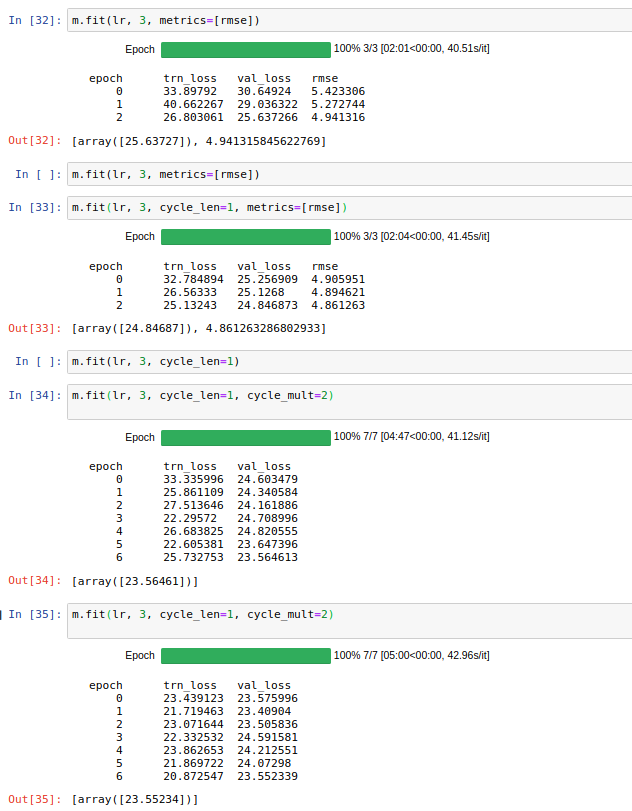
I am working on the NYC Taxi Fare challenge on Kaggle and accidentally find out that small batch size can give us a better result. Because I think it is quite new and haven’t discussed in the forum yet then I let myself create a topic on it. (Most of topic about reducing batch size is because it is not fit in the memory)
I found the information here. It says that when we use Large-Batch, we go straight to the Sharp-Minimum then lead to poorer generalization. In contrast with Small-Batch, the direction is quite oscillating, then the final point used to stay in a flat-minimum, and it is good to the generalization (the explanation is similar to why we use SGDR).
But we have an inconvenience with small batch-size that it is so slow for trainning. So i’m thinking on a method that we train the first epoch with a large batch size to quickly get to a ‘quite ok’ model. Then we continue with smaller batch size (I think it is similar to Jeremy approach for computer vision: we train firstly with low resolution image). Unfortunately, I have no idea how to do that, I can’t find the attribute batch_size in the learner.
Hope someone can give me comment about this idea and how to realize that.
I think the learning rate should be increased in proportion to the batch size. Basically when you have a larger batch size you are more confident of the direction to go. In your experiments the lr is kept constant across the batch sizes. Might be a good idea to see what happens if you have larger lr in 512 batch size cases.
Also neither model has been trained to convergence and could be trained longer to be able to comment on it.
I stop training at that stage because the model is overfit already. In the picture above you can see that when I continue to train, the val_loss doesn’t reduce anymore.
There’s a performance tradeoff inherent in batch size selection–a larger batch size is often more efficient computationally (up to a point) but while that might increase the number of samples/s you process, it also can mean that the number of SGD iterations you take /s decreases. It currently seems that with deep networks it’s preferable to take many small steps than to take fewer larger ones (again, this is a design tradeoff that requires experimentation to nail down optimally for any given dataset/net)
He explains that small batch-size can also lead to converge rapidly because it has more iterations
spacy (the lib behind torchtext + lots of other nice stuff) based their model training along the idea of compounding batch sizes too https://spacy.io/usage/training#section-textcat , so I guess it does work reasonably well
What you are referring is called the generalization gap in deep learning:
Some interesting info also between Sgd and Adam :
But, Batch Normalization is introducing an opposite effect. Very small batches with Batch Norm layers frequently enlarge the generalization gap. That is why Kaiming He recently introduced Group Normalization as an efficient alternative to Batch Norm: https://arxiv.org/abs/1803.08494
Overall, that is a very interesting subject. But as it is frequently the case in machine/deep learning, these hyper parameters observations are problem-dependent.
Wow thank you so much for the very interesting information ! I feel so motivated on this new subject. It still has a lot of things that I can discover. Will try to read these papers soon.