I’m very excited to share with you a new feature for the timeseries package that enables displaying Class Activation Maps for time series. It offers both CAM and GRAD-CAM as well as user-defined CAM. The InceptionTime model is used as an illustration.
At the heart of this feature, there is one single method called show_cam() that you need to use . The latter accepts the following data:
- A Single dataset item
- A list of dataset items that a user select
- A batch of items returned by one_batch() method
I also exposed most of the methods used under the hood that might be useful for others.
@jeremy and @sgugger, I think you will be happy to know that implementing both and GRAD-CAM was the easiest part of the whole implementation thanks to the notebooks that you put out there and that you keep updating and adding new ones. Those notebooks are invaluable. Thank you for sharing them. Figuring out how to plot multi-colored curves using matplotlib was by far the toughest part.
As an illustration of the capabilities of this new feature, I choose one of the UCR univariate time series datasets called GunPoint. This is the dataset used in may articles for both CAM illustration like in the excellent review that @hfawaz wrote and Shapelet Transform. This dataset involves one female actor and one male actor making a motion with their hand. The two classes are: Gun-Draw and Point. I added another notebook to illustrate an example of ECG classification (Normal heartbeat and a Myocardial Infarction) using the ECG200 dataset.

Here below, an example on how to call show_cam() (if we want to use CAM, adding func_cam=cam_acts i unnecessary because it is the default function):
show_cam(batch, model, layer=5, i2o=i2o) or
show_cam(batch, model, layer=5, i2o=i2o, func_cam=cam_acts) # CAM is the default option
GRAD-CAM option:
show_cam(batch, model, layer=5, i2o=i2o, func_cam=grad_cam_acts) # GRAD-CAM
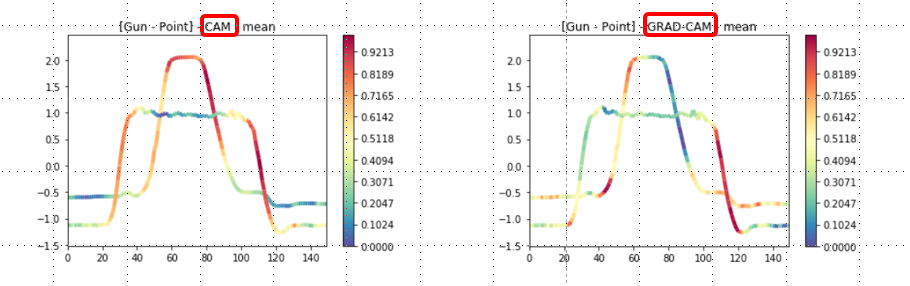
This illustrates the Gun vs Point activations. Activations curves are displayed for both CAM and GRAD-CAM.
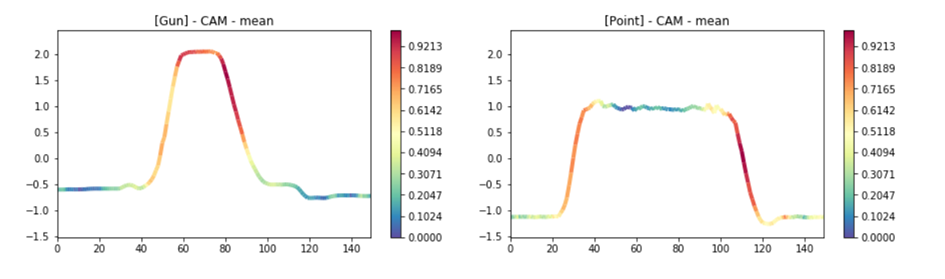
Activations curves can be also displayed separately. This illustrates the Gun vs Point using CAM function.
The show_cam() method is highly configurable with several default settings. Here below is the show_cam() full signature:
show_cam(batch, model, layer=5, func_cam='cam_acts', reduction='mean', force_scale=True, scale_range=(0, 1), cmap='Spectral_r', linewidth=4, linestyles='solid', alpha=1.0, scatter=False, i2o='noop', figsize=None, multi_fig=False, linewidths=None, colors=None, antialiaseds=None, offsets=None, transOffset=None, norm=None, pickradius=5, zorder=2, facecolors='none')
One of the options that I’m excited about is the possibility that the users have to plug-in their own custom CAM method. Check out both cam_acts and grad_cam_acts to see how easy you can create your own CAM function.
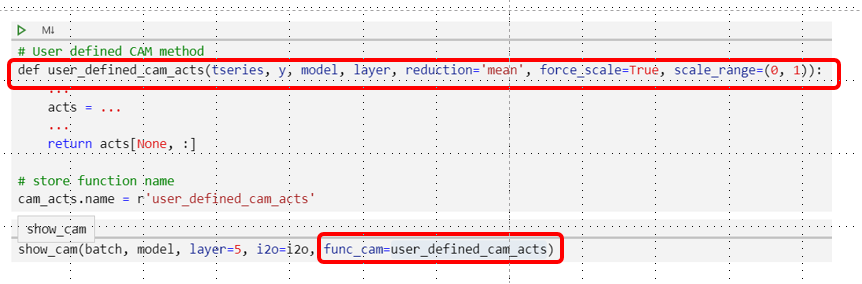
When CAM and GRAD-CAM are calculated, the resulting tensor has a shape of (n_channels, seq_length) and therefore has to be reduced to a tensor with (1, seq_length) shape in order to be superimposed on the original time series [the latter has a (1, seq_length) shape] .
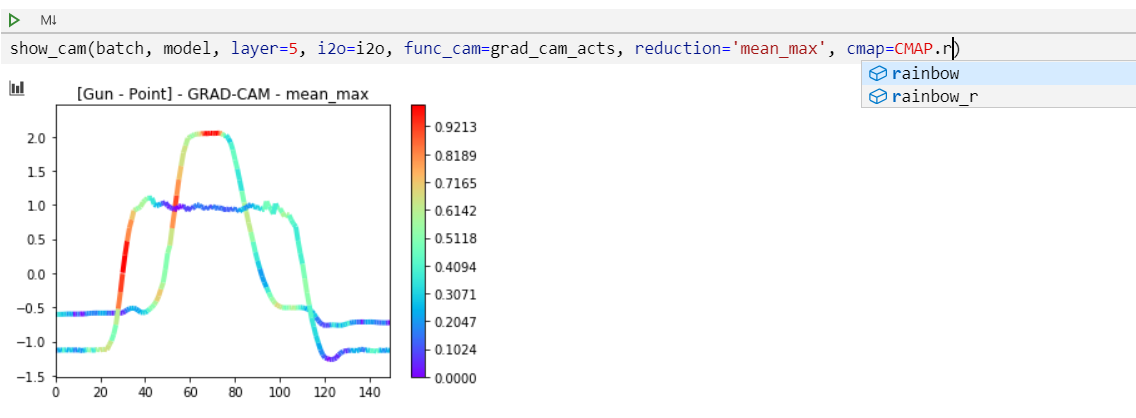
show_cam() offers 4 types of reductions: mean (default), median, max, mean_max. Here below, the max reduction is chosen.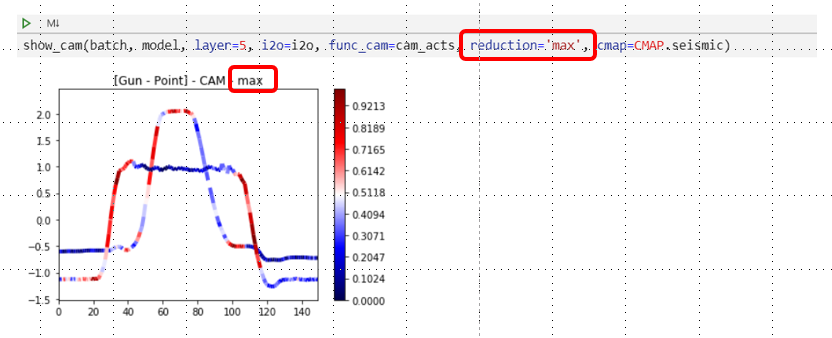
Scatter plots are also supported:
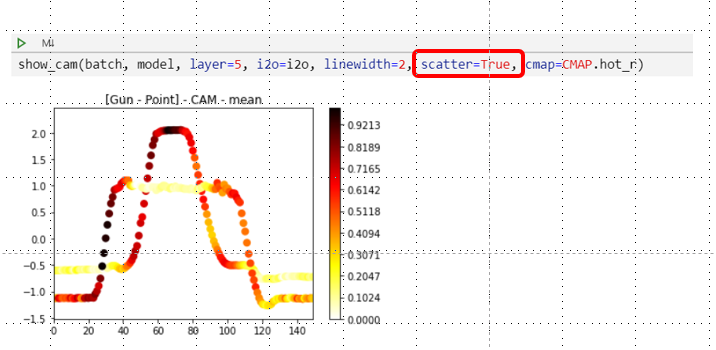
As illustrated here below, the user is able to choose one of the 164 cmap palettes offered by show_cam(). I added a class called CMAP that helps autocompletion as seen in the following figure (no need to remember cmap names):
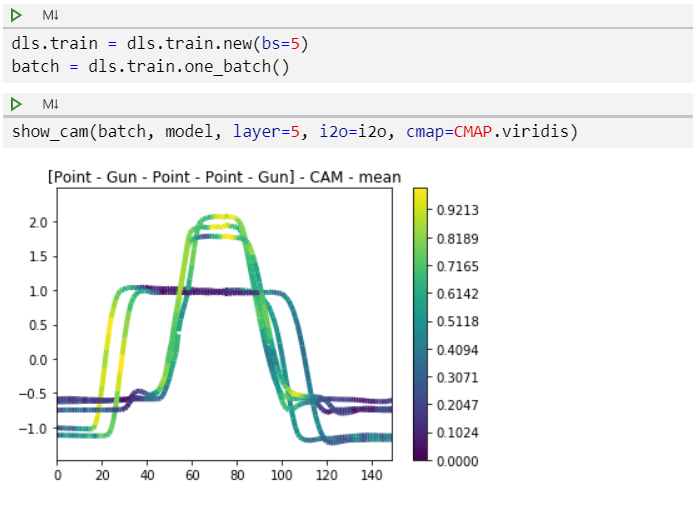
show_cam() can also plot activations of a whole batch of time series (example with batch size of 5 here below)
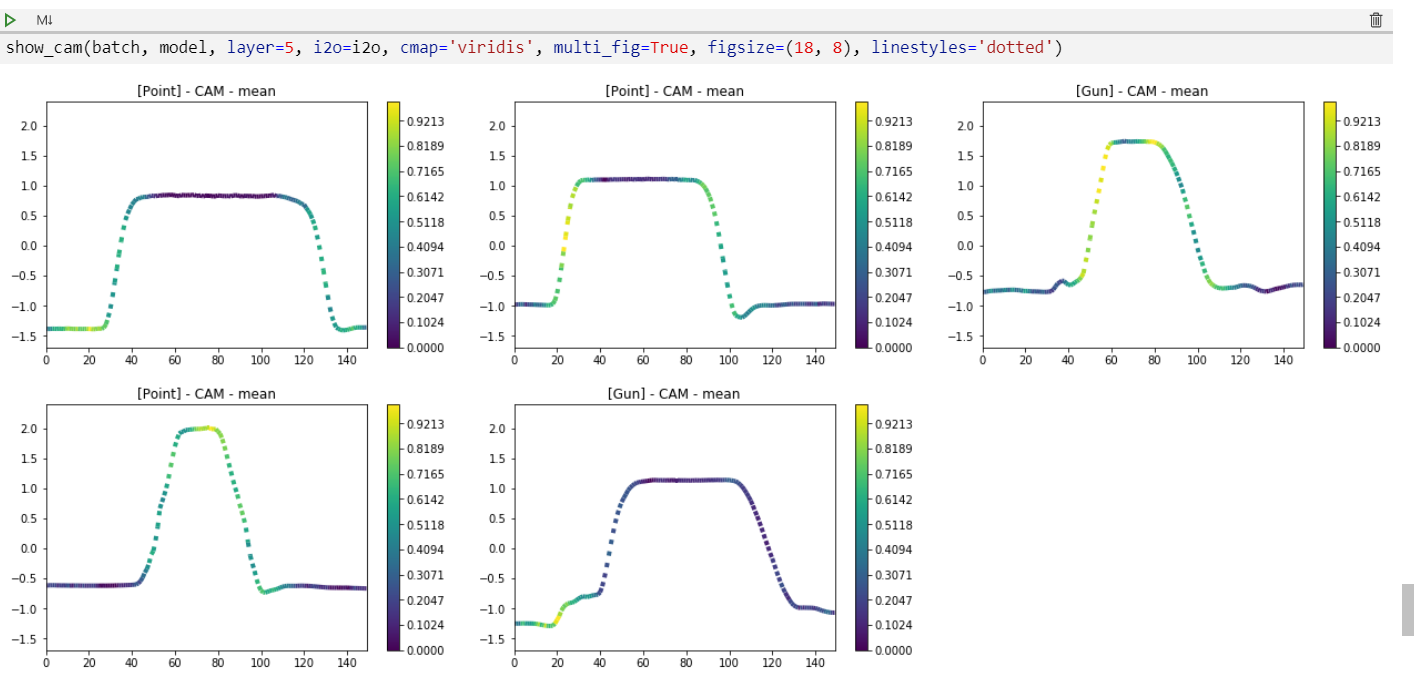
We can also display the same curves in separate figures in order to ease their interpretation:
This is just a glimpse of the different capabilities found in this CAM feature. For those interested in this stuff, I invite them to check out the detailed documentation as well as checking out these notebooks: 82_univariate_timeseries_CAM.ipynb, cam_tutorial_GunPoint.ipynb, and cam_tutorial_ECG200.ipynb
If you have access to some interesting time series datasets and/or any implementation of other CAM methods (other than CAM and GRAD-CAM), please consider sharing them in this thread.
Please give this feature a try and share your feedback. If you find it interesting, please share it and/or like it on GitHub.