I’m very excited to share with you a new module called timeseries for fastai v2. It’s a work in progress. This timeseries project is inspired by the fantastic work of @oguiza. It supports the InceptionTime model (from @hfawaz). I combined @tcapelle (thank you for sharing) and Ignacio InceptionTime implementations. I will gradually add other NN architectures.
To build timeseries, I chose another approach by creating an API that is similar to fastai2.vision. In a way, a timeserie is similar to a 1D image. I also created a new class TSData to download and store timeseries datasets. This class avoid both handling individual files (files per channel) and creating intermediary files (csv files). I will create another post where I will explain in more detail what I did (like why I abandoned the idea of using Tabular data, and created TensorTS (similar to TensorImage))
I would like to thank @jeremy and @sgugger for creating such a powerful and concise library. Thanks to fastai v2, timeseries package is really both compact and fast.
This extension mimics the unified fastai v2 APIs used for vision, text, and tabular. For those familiar with fastai2.vision, they will feel at home using timeseries. It uses Datasets, DataBlock, and a newly introduced TSDataLoaders and TensorTS.
timeseries presently reads arff files (See TSData class), and soon ts files will also be supported. Each timeseries notebook also includes a set of tests (more will be added in the future). Here below is an example of an end-to-end training using TSDataLoaders.
from timeseries.all import *
path = unzip_data(URLs_TS.NATOPS)
fnames = [path/"NATOPS_TRAIN.arff", path/"NATOPS_TEST.arff"]
# Normalize at batch time
batch_tfms = [Normalize(scale_subtype='per_sample_per_channel', scale_range=(0, 1))]
dls = TSDataLoaders.from_files(fnames=fnames, batch_tfms=batch_tfms)
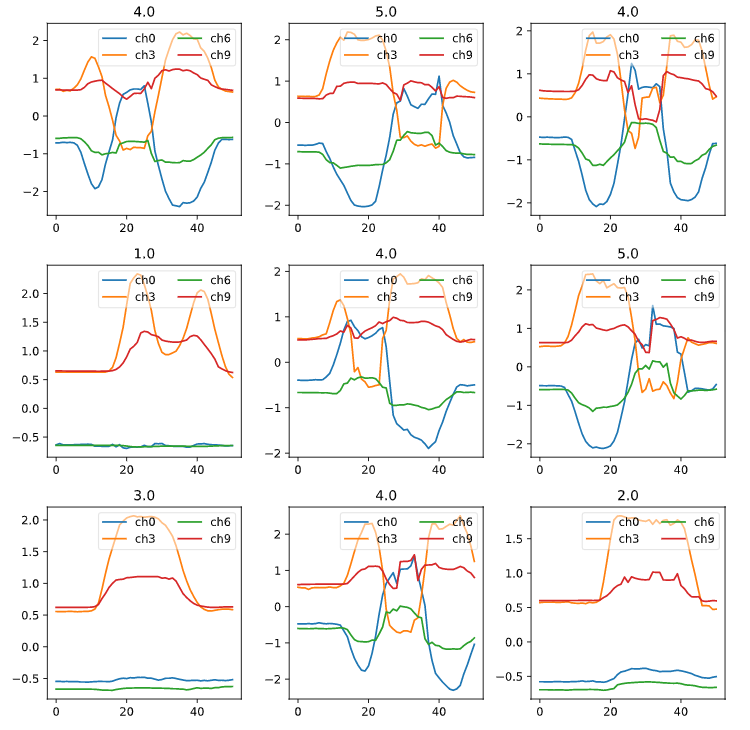
dls.show_batch(max_n=9, chs=range(0,12,3)) # chs : list of chosen channels to display
c_in = get_n_channels(dls.train); c_out = dls.c
model = inception_time(c_in, c_out).to(device=default_device())
opt_func = partial(Adam, lr=3e-3, wd=0.01); loss_func = LabelSmoothingCrossEntropy()
learn = Learner(dls, model, opt_func=opt_func, loss_func=loss_func, metrics=accuracy)
epochs=30; lr_max=1e-3; pct_start=.7; moms=(0.95,0.85,0.95); wd=1e-2
learn.fit_one_cycle(epochs, lr_max=lr_max, pct_start=pct_start, moms=moms, wd=wd)
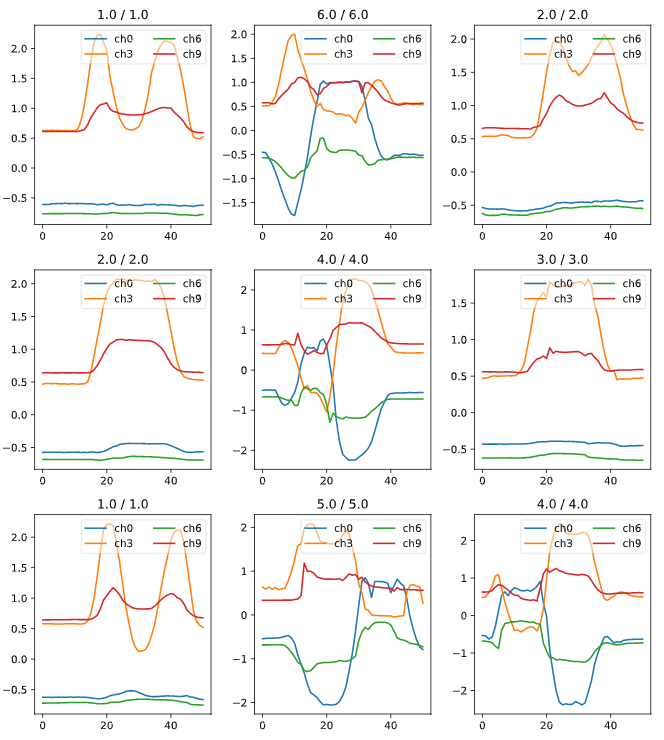
learn.show_results(max_n=9, chs=range(0,12,3))
In the index.ipynb notebook, I show 4 differents methods to create dataloaders (using Datasets, DataBlock, and TSDataLoaders: that’s just 3! => the guy doesn’t know how to count, be aware  ). I think the best way to quickly explore this extension is to run it, in Google Colab, either the full detailed index.ipynb notebook or the Colab_timeseries_Tutorial. The latter shows a minimal example using
). I think the best way to quickly explore this extension is to run it, in Google Colab, either the full detailed index.ipynb notebook or the Colab_timeseries_Tutorial. The latter shows a minimal example using TSDataloaders (similar to the code snippet here above). It’s better to turn on GPU on Colab. In Windows, it’s automatically detected. It’s pretty fast even with CPU on.
I tested timeseries in Windows, Linux (WSL), and Google Colab using fastai2 0.0.11 and 0.0.12 and fastcore 0.1.13 and 0.1.14.
Please feel free to reach out, and to contribute. Hopefully, we will build the best deep learning module for timeseries classification and regression for fastai v2.
Looking forward for your feedback