I’m new to deep learning and right now I’m stuck in a project I’m doing alone where I want to predict in an EEG pattern if the eyes are open or closed. The problem is that the accuracy is the same from start to end at 64.5%. I’ve tried to change the loss and the bs number but nothing changed. I have no idea what to do. Please help me thanks.
I think you have time-series here, but us a tabular learner. This one is, if I understood that correctly, mainly learning embeddings but not the dependencies between the timesteps. If you look carefully your training loss goes down but valid goes up quite a bit. I think you use the wrong model, so it does not work.
The classic thing to try first here is an LSTM model I guess. I did not find a good fast.ai resource, only pure PyTorch, for doing that with sensor data (I have some PyTorch code here: https://github.com/joergsimon/xai-tutorial-april-2020 ). So maybe some more fast.ai experts might help you here.
As a side note: You did put a learning rate more or less at the end of the plot, where we also have a valley. For this tabular learner, you might also try with lr of f.e. 1e-4. But again, I think this is not the right model for the task anyway.
If I interpret your data correctly, you have an EEG with 14 channels and around 15k long. There’s a column for the output. I guess the data is equally spaced and index in time.
If that is the case, the choice you made is not very helpful.
It would be better to use a time series model that takes subsequences of the entire sequence.
But the first thing you need to do is to convert the data you have into samples that can be processed by a time series model.
You may want to take a look at data preparation in the tsai library. You would need to create an array with shape: [n samples x channels x timesteps] using the SlidingWindow function. There are examples that show how to use this function.
That output is something you can then use to create a TSDataLoaders and a model like InceptionTime. These approach tends to work much better. Please, let me know if that works.
This tsai preparation library is amazing. This type of library has noodled in my head for over a year. I can’t believe you have done this. Really amazing.
Yeah, I am interested. I have seen similar competitions on Kaggle before, but I feel the Deep Learning community was never in a better position to solve sequential data.
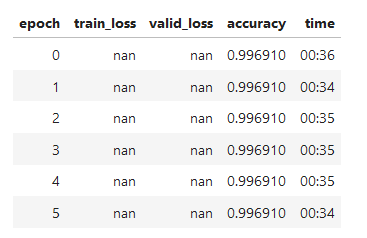
when creating the model. I do not know if the batch size is too small/large (I have a P100) but so far plenty of memory is left. However, the losses for each iteration of fit_on_cycle are always nan - unlike for the example data when using my own data set. What is wrong or needs to be changed? Notice: I am operating in a highly unbalanced binary classification setting (= anomaly detection) with weak (ie. sometimes missing and not always 100% correct) labels
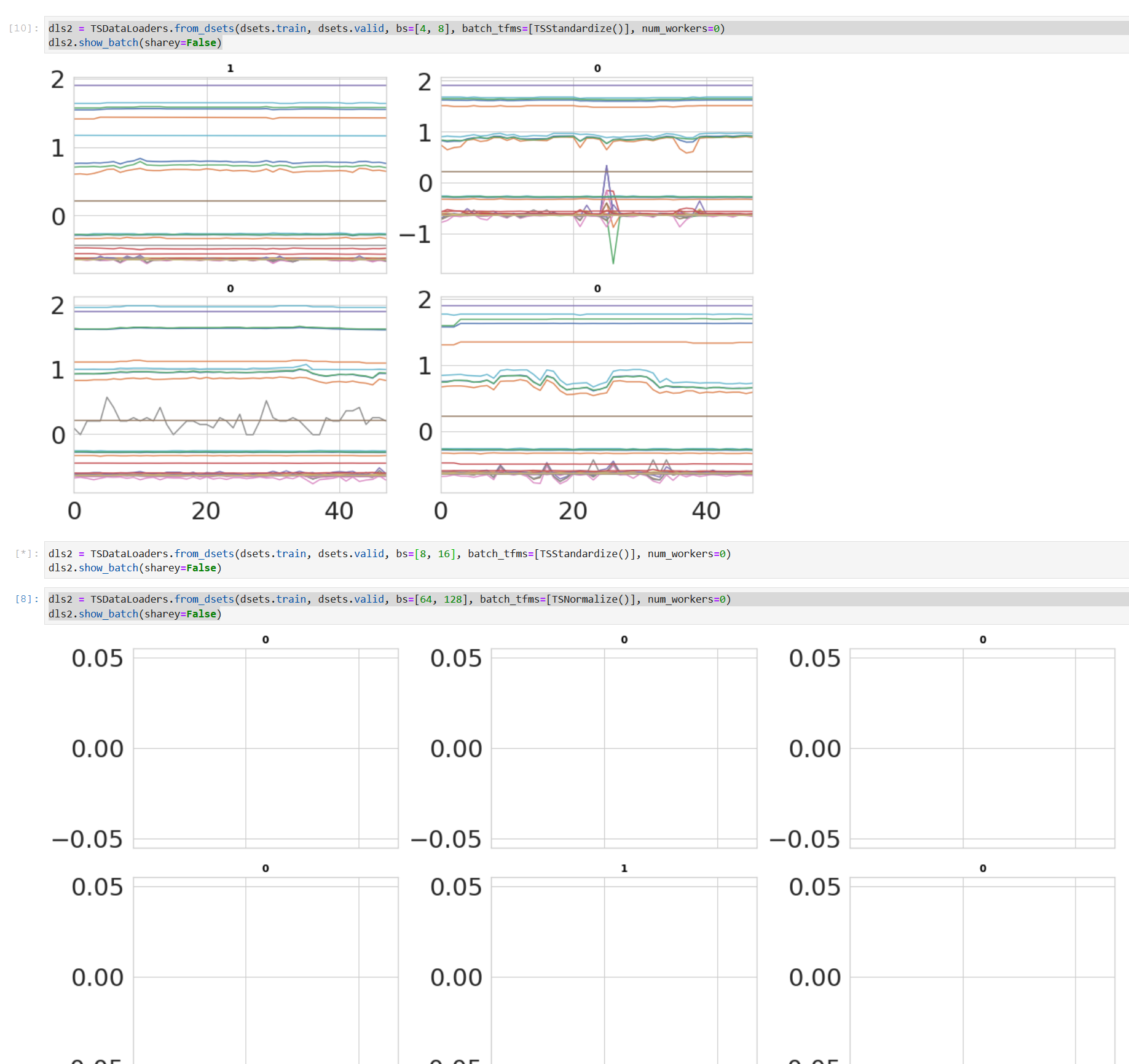
I think it has something to do with batch size and data loading - for a very small batch size (with very slow training) - the visualization at least shows some time series - whereas if the batch size gets larger it seems to be empty:
But even when changing the data loading code to: dls = TSDataLoaders.from_dsets(dsets.train, dsets.valid, bs=[2048, 4096], batch_tfms=[], num_workers=0) # images defined
which results in some time-series being displyed - the result is the same. It is all NaN for the losses.
Hi @geoHeil,
Thanks for your comments about the tsai library!
I’d say the issue you have is likely coming from having missing labels. In a supervised setting like the one you are using, you need to have a label (that may be weak, or noisy) for every sample. Otherwise there’s nothing to be learned, and the loss returns a nan.
This matches your comment on the batch size, as large ones increase the chance of having an unlabeled sample in the batch.
Try removing the missing labels before creating the dataset, and it should work. Or you may fill the missing values with a new label (like ‘na’ for categories or 0, the mean, median, etc for regression). But do this before creating the dataset.
Unfortunately, I hadalready filled NaN/ any non labelled values with 0! It is highly unbalanced though for class 1 - in fact I only have some weak labels for class 1. So this did not solve it.
However, I have observed that there are some X values with Nulls.
I can confirm that NaN in X were the problem! There should not have been any. I need to double check the pre-processing. But it looks like from here on TsAI does a great job!
I wonder if the existing pre-processing functions (normalization) can simply be used when using the panel data @oguiza ?
To answer your question on preprocessing it depends. tsai provides multiple ways to standardize data. Yo can normalize or standardize, and do it using the entire training set (default), or by_sample, by_var (that is for all channels in training), or by_sample and by_var (for each channel in each sample). What it doesn’t provide is a way to standardize data by group (based on an id, like you may have in panel data). If that is the case, you will need to standardize data before creating the TSDatasets.
The preprocessing provided will probably cover most cases.
What I’ve seen in my experiments, is that the choice of preprocessing is very data dependent, so you may need to experiment with different preprocessing approaches.