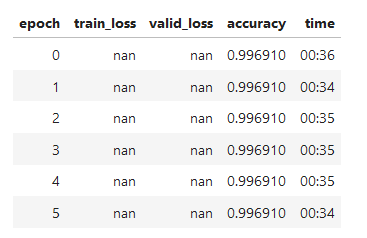
when creating the model. I do not know if the batch size is too small/large (I have a P100) but so far plenty of memory is left. However, the losses for each iteration of fit_on_cycle are always nan - unlike for the example data when using my own data set. What is wrong or needs to be changed? Notice: I am operating in a highly unbalanced binary classification setting (= anomaly detection) with weak (ie. sometimes missing and not always 100% correct) labels
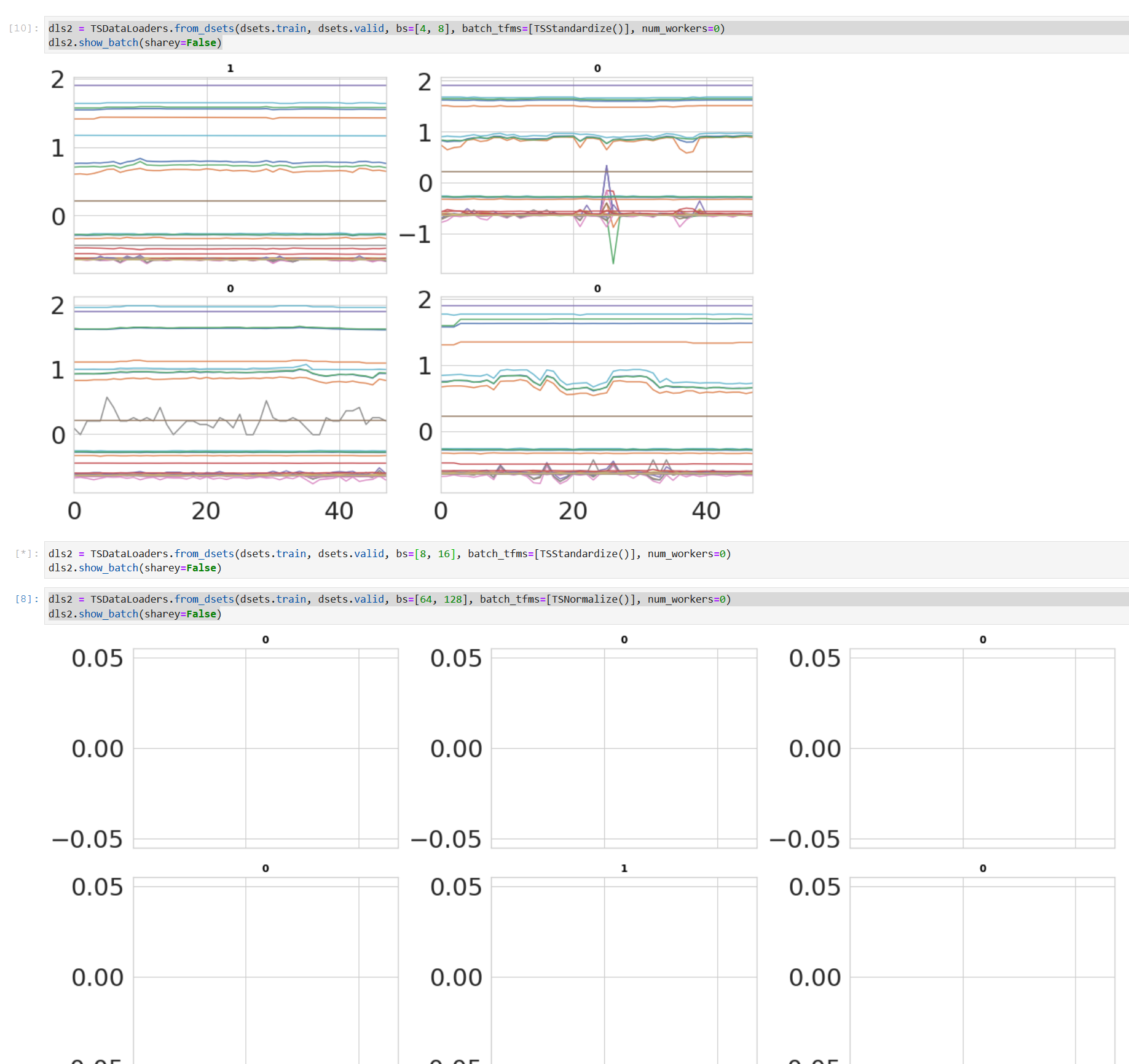
I think it has something to do with batch size and data loading - for a very small batch size (with very slow training) - the visualization at least shows some time series - whereas if the batch size gets larger it seems to be empty:
But even when changing the data loading code to: dls = TSDataLoaders.from_dsets(dsets.train, dsets.valid, bs=[2048, 4096], batch_tfms=[], num_workers=0) # images defined
which results in some time-series being displyed - the result is the same. It is all NaN for the losses.
Hi @geoHeil,
Thanks for your comments about the tsai library!
I’d say the issue you have is likely coming from having missing labels. In a supervised setting like the one you are using, you need to have a label (that may be weak, or noisy) for every sample. Otherwise there’s nothing to be learned, and the loss returns a nan.
This matches your comment on the batch size, as large ones increase the chance of having an unlabeled sample in the batch.
Try removing the missing labels before creating the dataset, and it should work. Or you may fill the missing values with a new label (like ‘na’ for categories or 0, the mean, median, etc for regression). But do this before creating the dataset.
Unfortunately, I hadalready filled NaN/ any non labelled values with 0! It is highly unbalanced though for class 1 - in fact I only have some weak labels for class 1. So this did not solve it.
However, I have observed that there are some X values with Nulls.
I can confirm that NaN in X were the problem! There should not have been any. I need to double check the pre-processing. But it looks like from here on TsAI does a great job!
I wonder if the existing pre-processing functions (normalization) can simply be used when using the panel data @oguiza ?
To answer your question on preprocessing it depends. tsai provides multiple ways to standardize data. Yo can normalize or standardize, and do it using the entire training set (default), or by_sample, by_var (that is for all channels in training), or by_sample and by_var (for each channel in each sample). What it doesn’t provide is a way to standardize data by group (based on an id, like you may have in panel data). If that is the case, you will need to standardize data before creating the TSDatasets.
The preprocessing provided will probably cover most cases.
What I’ve seen in my experiments, is that the choice of preprocessing is very data dependent, so you may need to experiment with different preprocessing approaches.
It works great so far! I’ve just run the example code from your repo on some of my data, both minirocket and mini_dv.
I’m still absorbing the paper and code and plan to add multivariate support. Is there anything in minirocket that would prevent using ideas/code from the excellent multivariate extensions of rocket here?
Dear Experts,
I have downloaded @hfawaz InceptionTime model from github and I can see that @oguiza has modified it to run with pytorch, but I have a problem.
For about 3 weeks, I’ve been trying to tweak the model to suit my FOREX data in order to predict its price movement, but to no avail. I am familiar with LSTM but I want something better, and I know anything related to CNN will give me a better result.
I have used Transfer learning in MATLAB before but that was for images, and as you all know, MATLAB’s license is quite expensive, which is my major drive for switching to Python. Finding InceptionTime that builds on AlexNet warms my heart.
I’d like InceptionTime model that can just work on my FOREX data instead of “UCR_TS_Archive_2015”.
The short answer is sort of. Minirocket is a bit different under the hood, but you can take a very similar approach to multivariate.
The ‘official’ multivariate implementation of minirocket, to the extent there is such a thing, uses essentially the same approach as the ‘official’ multivariate implementation of rocket (see sktime/rocket), i.e., channels are assigned randomly to each kernel. (For minirocket, channels are assigned randomly to each kernel/dilation combination.) Note that this is very much a ‘naive’ approach to multivariate input. It seems to work ok, but it hasn’t really been tuned, and in the case of minirocket I actually don’t know a lot about how it stacks up against other potential approaches, except that superficially it seems to be close to multivariate rocket in accuracy.
The multivariate implementation of minirocket is currently in progress as a pull request here. You should be able to just copy/paste the functions in minirocket_multivariate.py. Note that sktime uses black, so the code formatting can look pretty crazy, and some of the variable names have been changed a little to conform to sktime style.
If it’s helpful, I can make a ‘clean’ multivariate version available on the github repo.
I forgot to add: the multivariate version of minirocket has not (yet) been optimised properly, so it’s not as fast as it could be, but it should still be a lot faster than multivariate rocket.
Hi @angus,
It’s great to have you back in the forum, and especially after another great contribution like MINI-ROCKET!!
I must confess I’ve just scanned through the paper, and it looks very interesting, but haven’t really delved into it. I’ll do that in the next few days, and will probably have questions, comments, feedback.
First of all, the problem you are trying to tackle is really hard, as FOREX quotes don’t move just based on previous prices. In addition to that, the signal to noise ration is very low, so I’m not sure how successful you or anybody else may be with this approach.
If you want to use the tsai library, I’d recommend you to take a look at the documentation. In particular at the data preparation section and the tutorial notebooks.
To use any of the models in tsai you will need to create an array of shape [samples x variables x timesteps]. To do this you can use the SlidingWindow function provided with the library. I don’t know if you are planning to use Close prices only, or OHLC, or what. Those would be your variables. As to the timesteps that will be determined by your window_len parameter. You will need to decide if you want to run a classification or regression task.
Once you have the data ready you can create a TSDataLoaders object. And then use ts_learner and an architecture of your choice to test it. And you can start to run it.
There are MANY decision you need to make:
which input data to use? All currencies? Just one? A few?
How many variables? Close? OHLC?
Window length? Stride? Overlapping windows?
Classification or regression?
Architecture?
etc.
As I said this will be an extremely difficult task, and don’t know how much success you will have, but you can certainly use tsai to test your ideas.
PS. There’s a very interesting book called " Advances in Financial Machine Learning" by Marcos Lopez de Prado that might give you some ideas on how you can approach this task.
Hello @mrfabulous1,
I can say zero success as I’m greeted with error each time I try to run it.
It seems InceptionTime model was built with a particular time series in mind, so it’s not for all time series.
Yes @oguiza, it is difficult, and that is why I came here for help. Maybe someone has done it and would want to share.
I plan to use OHLC.
I’ll take a look at the book you recommended.
Thank you.