I don’t know. That’s what I’m trying to figure out.
If this works out. CAM will show me the variables that I will need to observe and maybe the ranges of values for the operator to correct the problem and prevent an outage

I don’t know. That’s what I’m trying to figure out.
If this works out. CAM will show me the variables that I will need to observe and maybe the ranges of values for the operator to correct the problem and prevent an outage
How does everyone in the group keep up to date with latest research/work (particularly with time series, but may be interested with other work too)? What do you guys follow besides this group?
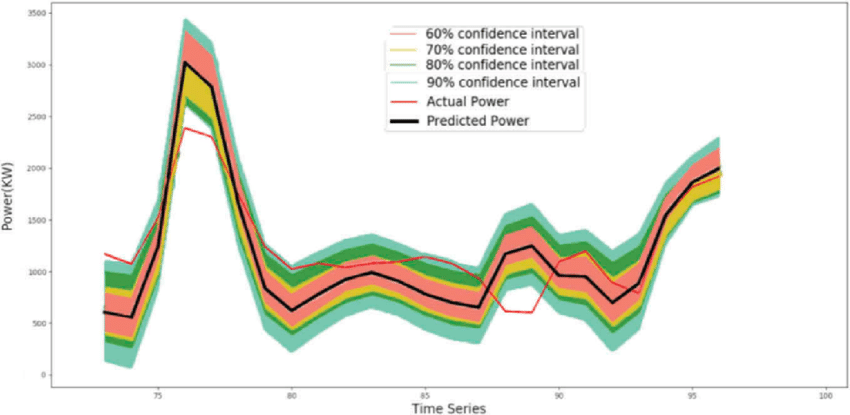
@gerardo, IMHO your use-case falls more in the probabilistic forecasting. It’s a savant word to say that instead of predicting one value per time step, you predict a range of values inside a certain percentile : Image please:
As you can see our predictions fall in different percentile intervals. You can then decide that if a prediction falls outside the 90% percentile (for example), it will be considered as an anomaly and you trigger an alert for example. Bear in mind, this a simplified explanation, and one way to do anomaly detection  . Another way would be using time series classification. However, in your case you are also forecasting your time series
. Another way would be using time series classification. However, in your case you are also forecasting your time series
You may check @takotab time series forecasting module fastseq (see here above) that he implemented in fastai v2 (it’s for univariate time series (one variable)) or Amazon Labs’ GluonTS Tutorial. I talked about it here
You can also search on Google for time series forecasting anomaly. Be prepared, there is a lot of information.
I have a question regadring sequence data. I have some input data for example.
[[2,4,5],[4,6,8],[4,9,4],[categorical_var]] and out would be another sequence like [8,5,9]. Do you guys any suggesstion how to approach to this problem or any notebook available where such types of problems are found. Any type of help is highly appreciated
@ourownstory, welcome to the fastai community.
I will try to answer your question. There are different approaches that have been used to process time series data using deep learning. Time series can be divided in 3 categories:
Time series Classification/Regression : These categories can be put under the same umbrella as they share some common background. For these 2 categories, time series can be treated either as a tabular data or 2D tensors similar to 3D tensors used in images (as expressed in `fastai v2’ module ).
For the tabular approach, you can check both @oguiza TimeseriesAI repo (using fastai v1) and @tcapelle timeseries_fastai (using fastai v2).
For the 2D tensor approach, you may check timeseries (using fastai v2). In this approach, I draw a similarity between TensorImage (fastai v2 native class) and Tensor2D (that I introduced in the timeseries module). In fact, we have the following mapping:
TensorImage <---> TensorTS
Conv2D <---> Conv1D
Time series Forecasting is like a separate category. Lately, there is a lot of research that has been published in this domain. It seems that LSTM is one the popular approach that showed some strong results. Time series forecasting benefits from the LSTM architecture as it inherently takes into the sequentiality of data in a similar way found while training a language model (predicting the next word or the next sequence of words).
You may also check @takotab time series forecasting module fastseq that he implemented in fastai v2.
I hope this information will give you a kind of summary of the different modules (that I’m aware of) developed using fastai v1 and v2 for time-series processing using deep learning.
Thanks a lot for organizing this thread. Are there any resources either here or in other threads that you are aware of, where fastai is used for time series anomaly detection
I have used the old fastai course v3 version to use deep learning on a data set with a time component. I am wondering what methods exist to apply this to a big data set when you have limited memory.
My understanding of the method is you create the databunch, you need the categorical variables to be all present to make the embedding. Is it possible using pytorch to read new files from a csv and train on data too big to fit in memory? Say I had a 50gb tabular file and I had 8gb of computer memory. In the existing framework, would it be possible to chunk the training data into small pieces and keep learn.one_cycle() on new pieces of data? I can see issues with IDs that occur that weren’t in the first chunk. Or say your categorical variables change like month, so when you use entity embeddings it will likely mess things up. How can these methods be applied without increasing your computer specs? Is it just impossible?
Hi @tabularguy,
I was having the same issue with some of my datasets, that are larger than RAM. I investigated the issue and found np.memmap. This allows you to use larger than RAM numpy arrays on disk almost as if they were in memory.
I’ve created a notebook to practice with np.memmap a bit. I don’t know if it may useful to you.
@oguiza Thank you for the reply. Do you think with this, say I had 4 years of data and I wanted to predict the next half year. Within the epoch training and for minibatch can you use this with the data bunch to train as well? Even if I can perform computations on this, can it be piped into the learner without causing memory issues? My understanding of the memory usage in an epoch is that the dataset is stored in memory, and the current minibatch is then tossed to the GPU to update weights.
If I only had 8gb of computer memory and I wanted to train on say a 50gb file, can this method be used with epochs and minibatches to train the tabular learner? I am really still kind of new to this.
I’ve used np.memmap as a replacement for numpy arrays. In my case I also have an 8GB RAM, and a 20GB dataset. Data is stored on disk, and the dataloader creates a batch on the fly.
A limitation to this approach is that np.memmap can only store data with the same dtype. So it’d be more complex if you want to use multiple dtypes in your tabular data.
So for example, if I wanted to do rossman type data that is 50gb that has several different types of columns, come numerical and some categorical, the np.memmap could only hold one column of data or it could hold all of the character columns? I am wondering how things like entity embeddings would work in this case too. Sorry, I am trying to avoid having to update my hardware and train on bigger data.
The datasets I use only contain 1 dtype. For example all your continuous data could be in a single array. If you have multiple dtypes, you would need to have multiple np.memmap arrays (one for continuous, and one for categorical, for example). This would require you to create a custom dataset where you can pass those datasets, so it could probably be done, but it’s more complex. As I said, I have not investigated this approach.
Fastseq is now added to the unofficial fastai extension repository 
(I have also put links to the two time serie V2 implementation while waiting for convergence to a single official repository)
The use-case you described here above falls under the time series (multipoint) forecasting. The case treated in Rossmann is a regression: It is a kind of a single point forecasting. There are many deep learning model used in time series forecasting: some are listed here.
You don’t need to load all your data in the RAM at once, and you can mix continuous data with categorical data (also called covariate variables such as day-of-the-day, hour-of-day, promo-dates, etc.)
You can use some lazy loading techniques to only load the chunks that you need to build your batch, and train and update your model per batch. As it is illustrated, here below, the model only need to have access to 2 small windows: 1) context window also called lookback window (green rectangle), and 2) prediction window also called forecast window (cyan color)
**zi,t **: is the curve that we would like to forecast (i.e. energy demand, sales, etc). The forecast starts at the end of the time serie.
xi,1,t and ui,2,t: feature time series or co-variate variables (respectively categorical and continuous data)
ui,2,t: is represent the day of the week in this example. It is a categorical data in this case, an embedding is used when we train a given model.
When asked to plot a CUDA Tensor, matplotlib.pyplot complains
TypeError: can't convert CUDA tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
But after
from fastai_timeseries import *
matplotlib and scikit can handle CUDA Tensors directly.
What kind of magic is this?
Hi there,
I work with a time-stamped log data and I want to make a model that could generalize user “habits”. For example, I have a huge dataset which made during an edX MOOC course (Online Video-Based Education - 6 weeks). Every user has log history and based on this I want to predict the user outcome after the first, second, etc. week. Another example is I have a customer purchase history, and I want to predict the amount of the next purchase.
In the first example, I have only categorical data (play, stop, pause, site viewing, etc.), while in the second I have continual and discrete variables.
As an initial project I used GRU and LSTM, but I want to use a more sophisticated model.
My goal is to make a regression (prediction) on time-series data.
My first idea to use BERT for the first and InceptionTime or TCNN for the second.
Do you have any suggestions?
InceptionTime is made for Time-series classification. It can use for regression?
Yes you can use InceptionTime for regression. Just adapt the last layer and the loss function. I think there are some examples in the timeseries_fastai repo.
I came here to find what I can use to solve https://www.kaggle.com/c/liverpool-ion-switching and all these repos made me a bit confused.
Here https://github.com/tcapelle/timeseries_fastai the data format in examples is different. As I see it, in the competition we have different batches, and we aim to predict x for each time step and y.
Is there anything handy I could use?
Hi all
Iam a medical student and new to DL, trying to make my way through part 2 course.
I find that much of the medical data that i want to use is irregular sampled.
How do you guys deal with irregular sampled data?
I found this paper which deals with irregular sampled data: https://arxiv.org/abs/1909.12064
Have any of you guys implemented something like this?
As far as I know there is nothing implemented yet for irregular time series in fastai. What I normally do is to make the data regular by splitting it into evenly spaced intervals, and filling missing values properly.
![[Figure 3: Sampled time series]](https://lh3.googleusercontent.com/PBOwVoKh7PrxM5HhECihkJmT2okWI1uzGb7pRXPbJZh608Ta2y2Xe6fICWo6uCeEkzV2SM5f_0SnSGIi-5HmWiqJkzzhBOEzcCv08WNJhCUBUeI3aP4cWEbvSaSQGF_wSJ3UQn5-)