Hey, you are also very quick!! 
I’m impressed!!
Yes, I think so. I’ve run many tests on the ChlorineConcentration dataset (i just picked it randomly), including some ensembles (that improved the result), but not so much as Mish!
So it looks pretty good to me!
I think it’s someting really worth exploring in more depth with other datasets.
My impression is that we may be able to come up with a few ideas that jointly used could significantly improve the outcome as it happened with Imagennette.
Well done Zachary!!
PS: I had the feeling that you would not wait until “later in the week”… 
1 Like
I agree. I’ve seen my own interesting behavior with Mish with tabular data, time series specifically, and so it doesn’t surprise me that this is the result.
General T/S question, if I have an input with 12 variables over a small time window of 5ms, with 1ms intervals, so I have an input of 60 variables, for my dataframe is it as simple as putting those 60 variables on one row, and then I can use your API? And could you explain the difference between feat and target? Or what feat is?
Thanks! 
(By the way, reran it and got 90%, definitely worth running ~5 times and reporting a CI, I’ll edit this back with it ) </s)
5 Runs:
mean: 0.9002084
std: 0.0024
1 Like
So is this a time series with just 5 time steps? If so, you won’t be able to use InceptionTime as it has large kernels. I’ve never used a model with such short time series.
But to answer your question in general, in the end you need to need a 3D tensor with shape = batch size, features, time steps.
In your example, it’d be bs, 12 features, 5 time steps.
Target is used to identify column in the pd df with the dependent variable. Since pandas dataframe are 2D and we need to create a 3D tensor, we need to indicate which column will be used to identify all samples for each feature, so that we can then concatenate the 3D array. If you only have 1 feature, you can leave it as None, as there’s nothing to concatenate. Not sure if this is clear. If not, pls, let me know
1 Like
Wow, Mish works really well on this dataset! I’ve quickly tested lr 4e-3 without Mish, and I get 86.4%! Above 90% is the best that I’ve seen so far. But I don’t know what Fawaz would think, since this is just 1 dataset out of 128 univariate and 30 multivariate.
I can try to do a few more (mabye 5?) this week (and I mean this week, I have a night class ![]() ) and bare minimum provides good practice for me
) and bare minimum provides good practice for me ![]() If you two have any particular recommendations for which datasets to try let me know, otherwise I’ll pick a few at random to explore! (on the 4e-3, this was a learning rate that I’ve seen generally do quite well with Mish + cosine annealing, compared to faster learning rates and was a bit more stable here too)
If you two have any particular recommendations for which datasets to try let me know, otherwise I’ll pick a few at random to explore! (on the 4e-3, this was a learning rate that I’ve seen generally do quite well with Mish + cosine annealing, compared to faster learning rates and was a bit more stable here too)
Ok, let’s see what he thinks tomorrow.
1 Like
There’s something very wierd in the notebook you’ve sent to me @muellerzr . There are 2 runs, but if you look at the initial train loss, they look very different. Not sure why that occurs. Have you seen this same behavior in other runs?
1 Like
@oguiza I reran it five times and uploaded the new notebook here (same place). I got roughly the same results with a tighter standard deviation (0.0015).
In regards to your initialization, yes there was quite a variety. Thank you for pointing this out! I hadn’t noticed it before.
Initial Train Loss:
[1.012777, 0.891233, 0.874231, 0.873835, 0.848346]
Everything was setup the same from the same initial learner weights, which I find interesting. Also the loss curves all look very different too.
Very exciting! ![]()
FYI, this stuff is much easier in fastai v2, so you may want to check that out. We’re really keen to have advanced users like you folks putting it thru it’s paces, and get your feedback.
If you decide to give it a go, please create a thread on #fastai-users:fastai-v2 so that we can answer any questions you have, help review your code, and learn about what you find!
5 Likes
Let’s go full fastai V2! That’s one of the reasons I didn’t wanted to create the full fastai ItemList.
@hfawaz I am rerunning MLP cause I had a bug, but the results from inception are up.
@oguiza I also think that one_cycle may not be the best approach for this small dataset. That’s why I was playing with LBFGS but I am not getting good results, it appears that the pytroch implementation is missing linear search. I may give a try to this implementation from one of pytorch devs.
Thanks for your repo, I am learning so much from your implementations =)
Okay great @tcapelle , I guess the results are for one iteration of Inception ? Because InceptionTime’s results consist of an ensemble of five iterations - the ensemble is simply the average probability distribution over the classes.
@oguiza I know that not everyone has access to enough computing power to run over the 128 datasets. The problem is even when running on 45 datasets, the original paper of FCN and ResNet claimed that FCN is the best architecture while for the 85 datasets ResNet showed the best performance. Nevertheless, I think testing on easy datasets would be a waste of resources - but at the same time testing on very hard datasets would also be a waste of resources as we saw in your Earthquakes competition. This is why I suggest starting out by testing on datasets where TS-Chief was able to achieve very good results compared to InceptionTime.
2 Likes
As a rule of thumb, would you recommend TS-CHIEF over InceptionTime for small datasets? (around 150 multivariate sequences)
BTW, thank you so much @hfawaz for your reproducible research. Really appreciated, it’s absolutely the way to go!
1 Like
Yes, it is one run of the one_cycle policy with epochs=40.
I would say that TS-CHIEF would work better for smaller datasets compared to a deep learning approach - however this claim should be supported by extensive experiments.
I am very glad to be here discussing with everyone. Indeed reproducible research is the way to go forward advancing the sciences!
Thank you for your answer @hfawaz!
I guess that, in general, when you talk in this forum about size of the dataset, you refer to the numebr of sequences, and not to the number of points per sequence right? I am wondering what is the relation in the performance of DL-methods with respect to the length of the time series.
Another question that I have: Reading the paper Deep learning for time series classification: a review, more specifically, Section 6, I see that you apply Class Activation Maps (CAMs) to interpret the result of the classifier. Do you know if that is also applicable to multivarite time series data?
Okay great, I have added the results of five different initialization of Inception over the 128 datasets, you can choose one iteration in order to compare the results with your implementation.
Indeed when talking about the size of the dataset we refer to the number of sequences.
As for the length, we studied this in our recent paper, let me know if you have more questions.
It is straightforward to apply it on multivariate time series, but you will only be able to provide “interpretations” in the time domain.
Thanks @hfawaz! As far as I can see in Figure 14 of your recent paper, long time series do not get good results.
Just for curiosity, why did you change the name of the model from DreamTime to InceptionTime?
Yeah Fig 14 is for changing the depth, however by increasing the Receptive Field using the kernel size, you will achieve good results. Check fig. 16
Yes for political reasons ![]() DreamTime
DreamTime
Great @hfawaz!
I’ve created a table comparing HIVE-COTE, TS-CHIEF and InceptionTime. And the datasets where InceptionTime underperforms TS-CHIEF are:
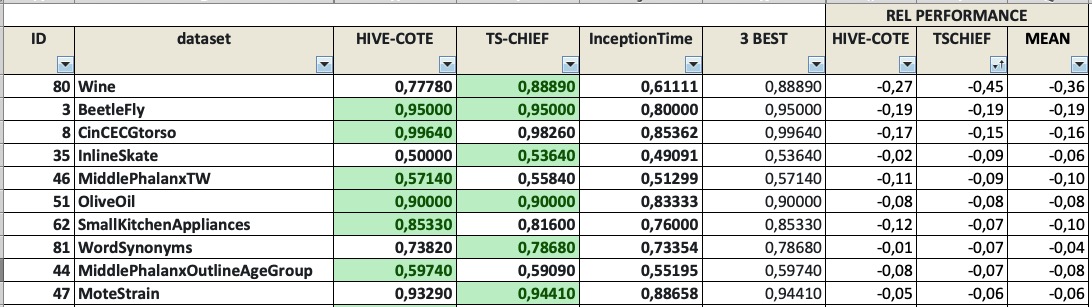
(*) Negative relative performance indicates that InceptionTime underperforms
So I guess that if we can show that an improvement in a few of these datasets, it’s something that could be potentially useful, correct?
EDIT: for some reason CinCECGtorso is not currently available for individual download from the http://timeseriesclassification.com web page. You can download the full 128 univariate and/or 30 multivariate datasets (2.5GB in total). So if you want to test bottom and top performers you should select:
bottom10 = ['Wine', 'BeetleFly', 'InlineSkate', 'MiddlePhalanxTW', 'OliveOil', 'SmallKitchenAppliances', 'WordSynonyms', 'MiddlePhalanxOutlineAgeGroup', 'MoteStrain', 'Phoneme']
top3 = ['Herring', 'ScreenType', 'ChlorineConcentration’]
datasets = bottom10 + top3