Hello,
I want to compare the performance of an EfficientNet-B0 model trained on images with the performance of the same model trained on time series data. The problem is a multi-label classification of 9 classes.
For now I was able to create an appropriate TimeSeriesList using fastai_timeseries (timeseriesAI) :
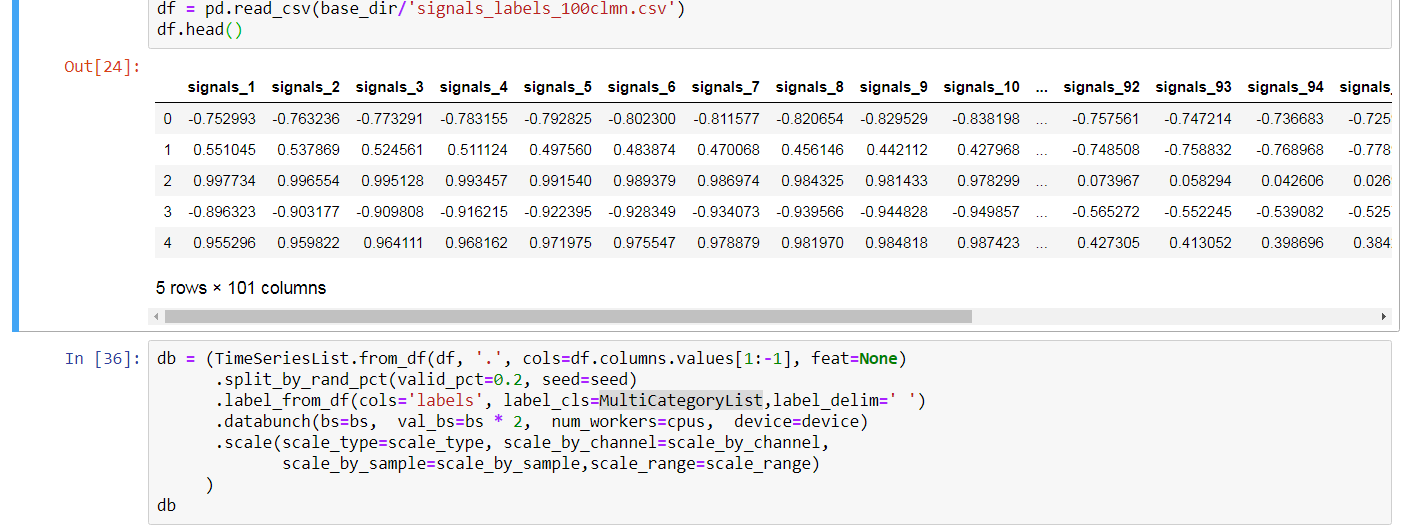
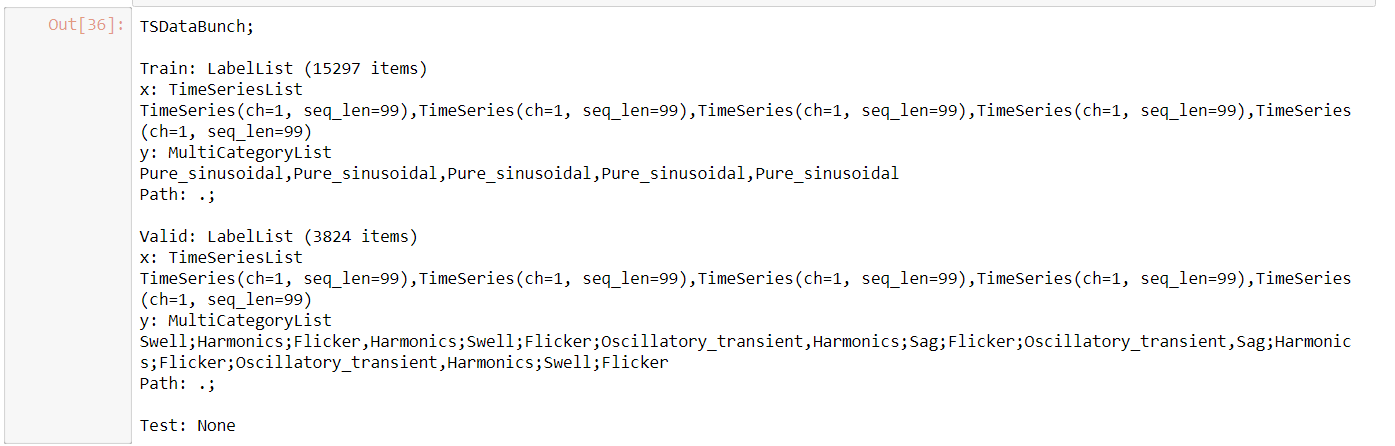
I know that I have to define the number classes the EfficientNet-B0 model should have:
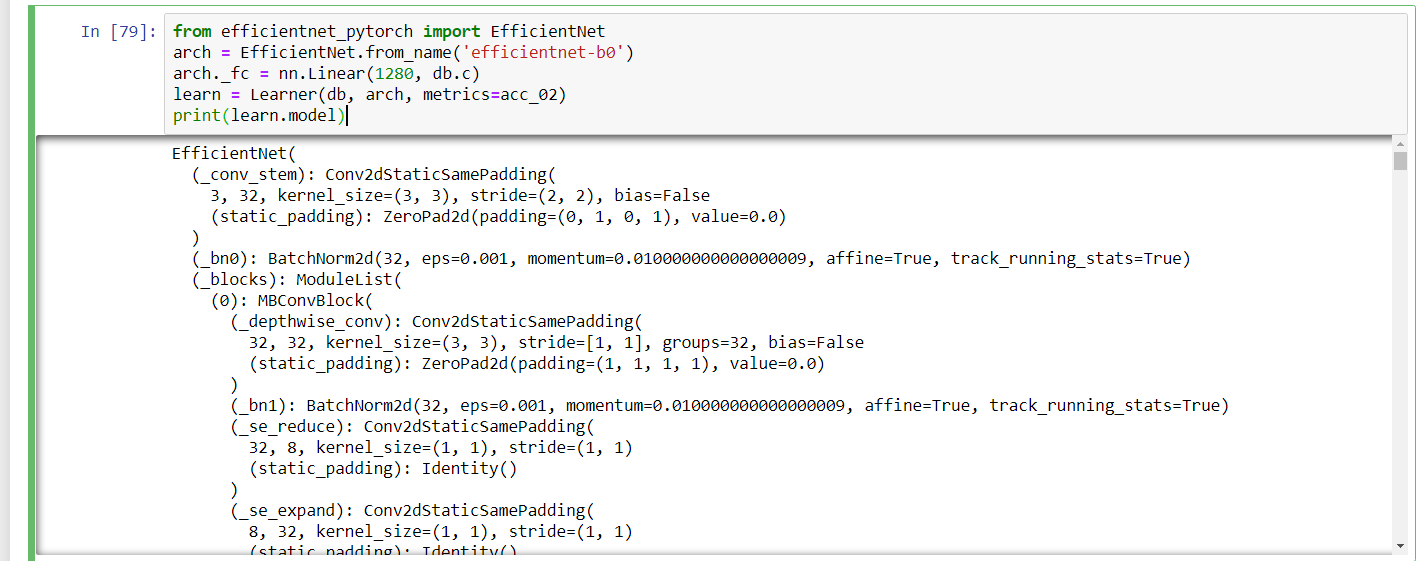
Yet it seems that I should also change the input size of the model to be appropriate with the data, because when trying:
print(learn.summary())
I get this error:
RuntimeError: Expected 4-dimensional input for 4-dimensional weight 32 3 3, but got 3-dimensional input of size [1, 2, 100] instead.
Can you help?