Thanks for the complete answer!
I have already played with Rossman back in V2 of the course and used this kind of tabular/xgbosst techniques before, but for this particular problem, the other TS are not that correlated to the dep_var, so using a regressor is not good enough. That’s why I was trying to understand and implement a more “financial” + regressor approach.
I am particularly interested in the GAN techniques just for how fun they sound. I have already done the “random Walk” test, and the last three values are super important, checked with XGboost and the feature importance puts them higher than everything else.
- I can make a regression of P as function of T and TS with “descent accuracy”, but not good enough.
- I have and external model to forecast T and TS precisely for the next 24h
- I want to use all this to predict a better P for the next 24 hours
- I have 24 months of data, sampled every 5 min.
- I may get 2 other TS, (wind and irradiance)
Just to give more insight, P is the power of a central heating system, TS is the temperature of water exiting the system, T is the ambient external temp.
I made some progress today:
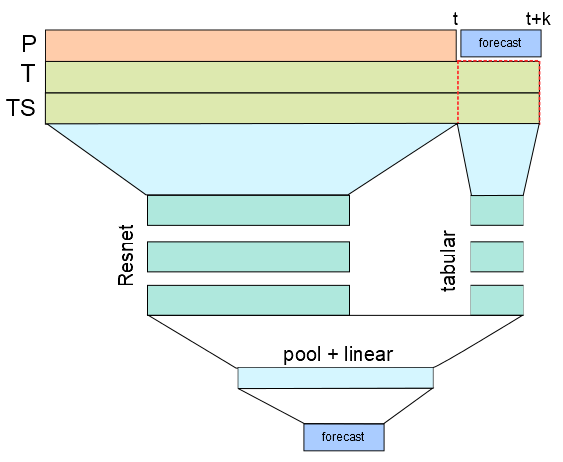
I built a model that takes as input the past (24 hours) plus the forecast of the Temperatures and predicts the Power P for the next 6 hours.
I treated the past 24 hours with a ConvNet and the forecast of the explicative variables with a Tabular model. Then I mixed the feature map of the ConvNet with the output of the tabular model appending a classic resnet head.
The output is pretty good, probably my architecture is kinda of noobish, so suggestions are welcome!
My Dataset is a Double input dataset, just to concatenate both different size arrays (TimeSeries):
class DoubleDataset(Dataset):
def __init__(self, X, X2, y):
self.X = X
self.X2 = X2
self.y = y
def __len__(self):
return self.X.size(0)
def __getitem__(self, idx):
return (self.X[idx], self.X2[idx]), self.y[idx],
and my model:
def basic_conv():
return nn.Sequential(nn.Conv1d(3, 64, kernel_size=3, stride=2, padding=1),
ResLayer(64),
ResLayer(64),
ResLayer(64),
AdaptiveConcatPool1d(),
Flatten(),
)
def tabular_model(inc:int, out_sz:int):
layers = [Flatten()]
layers += [nn.Linear(inc, 1000)]
layers += bn_drop_lin(1000, 500, p=0.01, actn=nn.ReLU(inplace=True))
layers += bn_drop_lin(500, out_sz, p=0.001, actn=None)
return nn.Sequential(*layers)
class mix_model(nn.Module):
def __init__(self, inc:int, out:int):
super().__init__()
self.cnn = basic_conv()
self.tabular = tabular_model(inc, out)
self.head = nn.Sequential(*bn_drop_lin(64*2+out,256, p=0.1, actn=nn.ReLU(inplace=True)),
*bn_drop_lin(256, 256, p=0.01, actn=nn.ReLU(inplace=True)),
nn.Linear(256,out)
)
def forward(self, x1, x2):
y = self.cnn(x1)
y2 = self.tabular(x2)
y3 = torch.cat([y,y2], dim=1)
return self.head(y3)