Great article @apil.tamang !
Just one comment : in my understanding, you must use cycle_save_name in learn.fit() if you want to save weights after each cycle_len and get at the end the average of weights.
Great article @apil.tamang !
Just one comment : in my understanding, you must use cycle_save_name in learn.fit() if you want to save weights after each cycle_len and get at the end the average of weights.
Is that the way it works tho, does cycle_save_name give you the average of the weights? Or does it save the one that has the minimum validation loss (i.e. like the Keras model checkpoint callback)? cc @jeremy
It saves after every cycle. It’s up to you to load them up and average them. See planet_cv.ipynb for an example.
So is this similar to the effect of snapshot ensembling then if you were to use cycle_save_name and then took the average of the preds generated from each of those saved weights from each cycle with the idea that perhaps each of these found some unique local minima and thus extracted some unique information? So it would follow that this would possibly give you a better result than just choosing one of those saved weights because it had the minimum validation loss?
Yes it’s exactly that ![]()
Beg to differ, and even sorrier I haven’t actually tried this out, but wanted to chime in…
I wonder if taking the average of the weights would be a good idea in an ensemble predictions. It makes sense to take the final predictions, and average them. However, taking the average of the weights… umm… that’s a little counter intuitive at least to me.
I feel like for any model trained to a point, the weights are optimized in relation to neurons within the neural network. I strongly feel like taking the averages of these weights wouldn’t necessarily translate in a linear way. I.e. the final performance of the network with the average weights wouldn’t be the final performance of the averaged predictions (that is: using ensemble in the traditional way).
But I could be wrong. I didn’t even know this wasn’t used by default. Just my 2 cents 
I think by “average of weights” in this case means loading the weights and predicting with each individually then taking the average of those predictions, not taking an average of the actual weights themselves. Yea I agree that would be kinda strange lol
Btw here is a paper about snapshot ensembling which explains this concept in a lot more detail. Basically the point is that we can implement this technique with fastai by using cycle_save_name ![]() That was the real “aha” moment for me and I’m excited to test it out.
That was the real “aha” moment for me and I’m excited to test it out.
“We show in a series of experiments that our approach is compatible with diverse network architectures and learning tasks. It consistently yields lower error rates than state-of-the-art single models at no additional training cost, and compares favorably with traditional network ensembles”
I think that taking an average of weights is also a valid approach, even though we have nonlinearities. Think about dropout for example - it is exactly what it relies on. Yeah, it gives you lesser dependency between activations (one nice effect) while it also effectively trains exponentially many models averaged at runtime
Definitely looking to further voices in this discussion and will gladly stand corrected if wrong Interesting conversation
I’d be very surprised if that worked, but I can’t say I’ve tried it.
I know I’m kinda late to the party but I also wrote a post about cyclic learning rates
That’s an awesome blog post with tons of references. Thanks for sharing.
I also just wrote my first deep learning blog post. I’d appreciate any feedback and improvements people may have as I hope to start making this a regular habit!
Wow that was absolutely worth the wait! ![]()
I hope you do too ![]()
That was a great post! Keep them coming
Hi all,
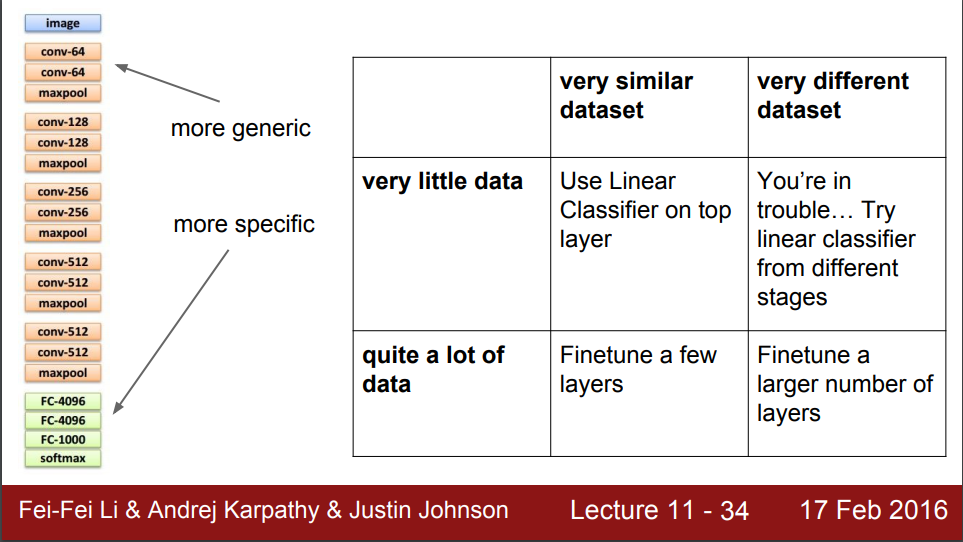
I wanted to break my initial inertia in writing blogs. So, I came up with my first simple blog post. I am attaching the draft here. Please review and let me know. And my fellow bloggers please let me know the tools you use for technical blogs(to draw diagrams etc).
Very clear, nice to read, informative post!
Only thing I that maybe, only maybe, could be a bit more precise; When explaining the criteria to decide if to “unfreeze” only last layers, medium or all layers the weight is put equally on “size of dataset” and “how similar this dataset is to originally trained one”. I’ve thought a bit about this… and I think its more important this second, similarity aspect. (Even if you have a very small dataset if this dataset is completely different to the original one you will need to unfreeze). But maybe this precission is unnecesary when first explaining concept.
Anyway, congrats for very good post post! 
Thanks a lot for the review, @miguel_perez.
I think if we have a small dataset which is not in correlation with the original dataset, training all the layers may not yield a good result. Because the data will not be sufficient for the whole architecture to learn the ideal weights. This is my current understanding, please correct me if I am wrong.
Well, I am quite noob so don’t trust my opinion 100%… 
About cuestion of unfreezing, the way I see it, it makes the model more powerful ==>more overfitter what is bad if you have a small dataset. So it is true that small dataset it is a reason not to unfreeze.
But my point is, well imagine you have a very small dataset that is so different to the one used for the pretrained model that the pretrained weights are worthless. You will have to unfreeze that dataset, no matter if it is very small