Understand how works Resnet… without talking about residual
I was 99% satisfied with all blog posts I found about Resnet (for example the great blog post “Decoding the ResNet architecture” from @anandsaha), but not at 100%.
Then, I searched in the Web and found, I thought, this 1% in the blog post “Understanding Advanced Convolutional Neural Networks”.
In the Resnet paragraphe, the autor (Mohit Deshpande) explains the beauty of Resnet in 3 points :
- More layers is better but because of the vanishing gradient problem, model weights of the first layers can not be updated correctly through the backpropagation of the error gradient (the chain rule multiplies error gradient values lower than one and then, when the gradient error comes to the first layers, its value goes to zero).
- That is the objective of Resnet : preserve the gradient.
- How ? Thanks to the idendity matrix because “what if we were to backpropagate through the identity function? Then the gradient would simply be multiplied by 1 and nothing would happen to it!”.
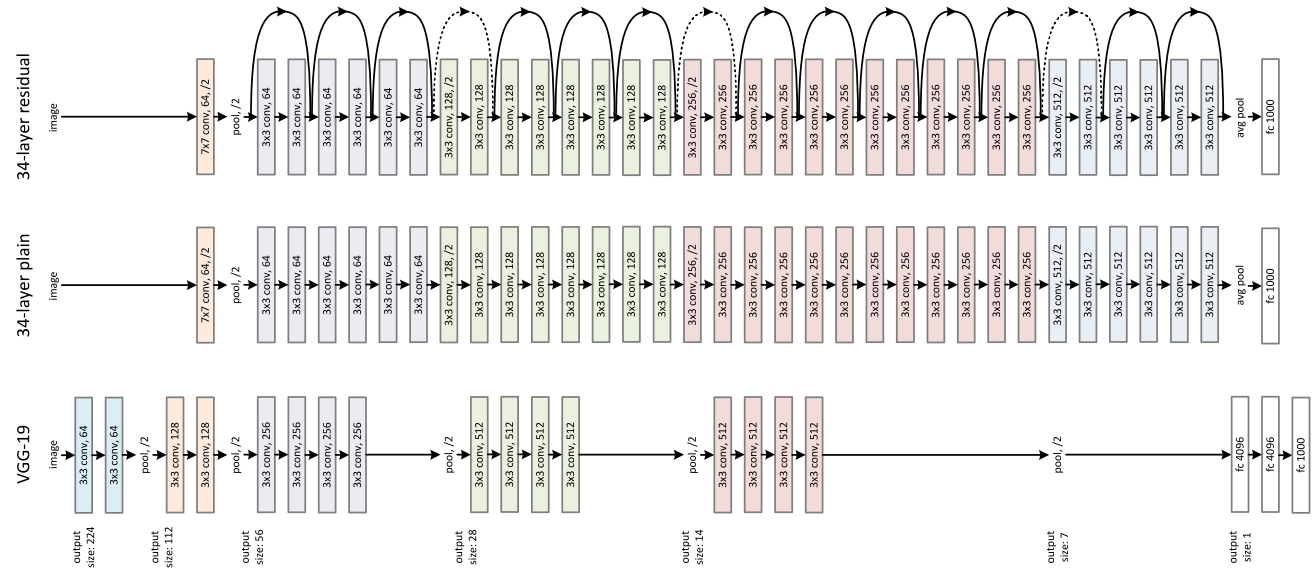
You can even forget the vanishing gradient problem and just look at an image of a Resnet network : the identity matrix transmits forward the input data that avoids the loose of information (the data vanishing problem).
That’s it