For weight initialization you can take a look at here http://pytorch.org/docs/master/_modules/torch/nn/init.html, for references and maybe further talk about which initialization is needed where, e.g. https://arxiv.org/abs/1504.00941.
1 Like
Thanks for sharing @neerjadoshi  In the augmentation article, note that training time augmentation only helps when you train multiple epochs. In your case you’re just training one epoch, so I’d guess the improvement is just random noise. Also you need to unfreeze the network, otherwise over-fitting is very unlikely (and therefore augmentation doesn’t help).
In the augmentation article, note that training time augmentation only helps when you train multiple epochs. In your case you’re just training one epoch, so I’d guess the improvement is just random noise. Also you need to unfreeze the network, otherwise over-fitting is very unlikely (and therefore augmentation doesn’t help).
I’d suggest trying a dataset that’s not quite as similar to imagenet, so needs more epochs to get good accuracy, and you should be able to show a more compelling difference then.
The initializations post is looking good. I think it would be helpful to show code examples of each concept you’re talking about; and where you do show code, put it in a code block, not a picture, so people can copy and paste it and try it out. Also, maybe show some experiments to show how it impacts training in practice?
A link to the papers that introduced each init method might be nice too.
I realise what can be corrected in the augmentation article. I’ll find a suitable dataset and train multiple epochs to capture the difference in performance.
Also, I’ll update the code snippets and references in the second article. In the material I’ve been reading, I’ve also been finding a lot of small nuances to add to that blog, so I’ll update accordingly.
Thank you for your feedback!
1 Like
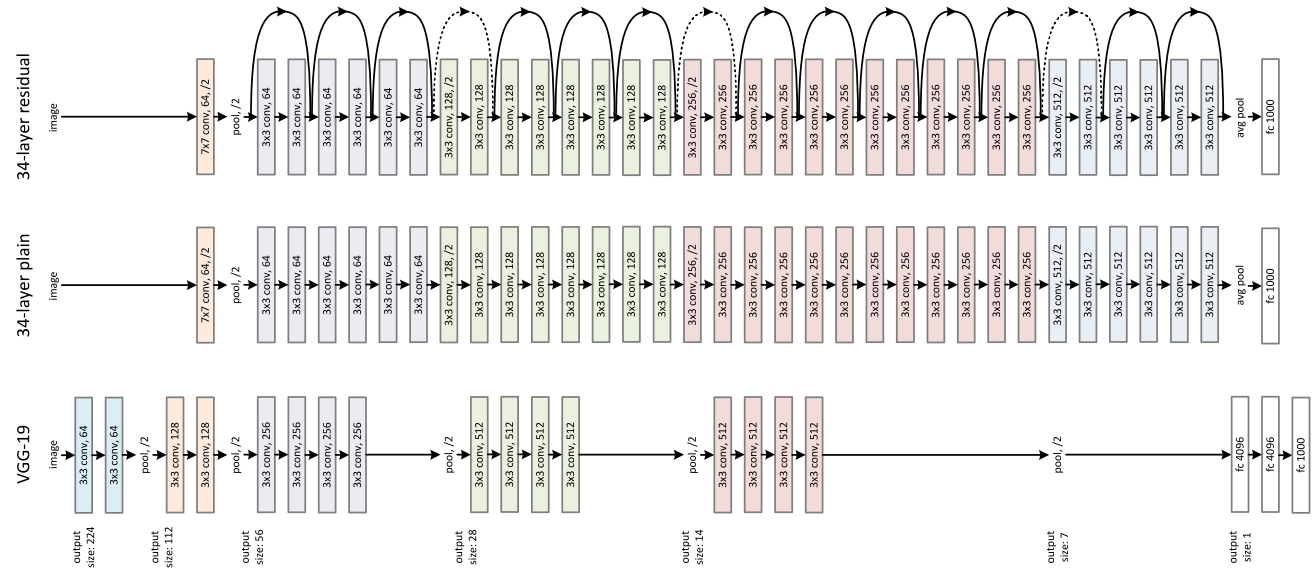
Understand how works Resnet… without talking about residual
I was 99% satisfied with all blog posts I found about Resnet (for example the great blog post “Decoding the ResNet architecture” from @anandsaha), but not at 100%.
Then, I searched in the Web and found, I thought, this 1% in the blog post “Understanding Advanced Convolutional Neural Networks”.
In the Resnet paragraphe, the autor (Mohit Deshpande) explains the beauty of Resnet in 3 points :
- More layers is better but because of the vanishing gradient problem, model weights of the first layers can not be updated correctly through the backpropagation of the error gradient (the chain rule multiplies error gradient values lower than one and then, when the gradient error comes to the first layers, its value goes to zero).
- That is the objective of Resnet : preserve the gradient.
- How ? Thanks to the idendity matrix because “what if we were to backpropagate through the identity function? Then the gradient would simply be multiplied by 1 and nothing would happen to it!”.
You can even forget the vanishing gradient problem and just look at an image of a Resnet network : the identity matrix transmits forward the input data that avoids the loose of information (the data vanishing problem).
That’s it 
Hi all, I just wrote a blog post for entering the StateFarm competition with fastai v2 (PyTorch) library.
As I am trying to be familiar with the library, I try the StateFarm dataset which is cover in v1 but not v2 and summarize my experience here.
1 Like
I got a little adventurous and set up Ubuntu 18.04
I have written a little guide on the tiny tweaks that make everything work.
Please let me know what do you think about it.
Sanyam.
Good article, maybe i am missing something, but perhaps you could add to your post the process in detail for getting a twitter follower assuming you have zero?
- create a post and just post it to the twitter ether, and keep doing repeatedly?
- message people with questions in hope thet 1/10 to 1/100 will respond, and maybe follow you,
- or is there another way?
I got 1700+ followers by just repeatedly posting and sharing posts on Twitter and some relevant Facebook groups.
Ok thanks, method 3) repeatedly share posts. This seems to be easiest of the 3, ill experiment
My first blog post about deep learning – feedback very much appreciated!
this is an awesome blog post!
Hey guys, I just wrote my first blog post which is an introductory post to Pytorch, In this post I talked about torch packages, tensors and how does automatic differentiation work, along with a hands-on Pytorch example.
I would love to hear your feedback. Thanks 
Manal elaidouni
Hello, I am currently interested in VQA so I wrote a summary of the paper, Kafle and Kanan (2016), on available VQA data sets and models: https://www.yjpark.me/blog/jekyll/update/2019/03/11/notes-on-vqa.html
More recent VQA models are also summarised here: https://www.yjpark.me/blog/jekyll/update/2019/06/10/recent-vqa-models.html
I would truly appreciate your feedback. Thank you in advance.