Given that it seems to be the foundation upon which all deep learning is based, I’d like to get a better understanding of the Universal Approximation Theorem.
There’s a super interesting resource offered by Michael Nielsen (author of Neural Networks and Deep Learning): Magic Paper. On that page is a video showing him using the tool to help understand the Universal Approximation Theorem. It actually approximates what he draws. But I still don’t understand it, not well enough.
If you run a deep learning network successfully and you get (say) 98% accuracy, can you figure out what function was actually created? Can you figure out what sub-functions went into making that function?
So it can shape itself to any line, curvy or not, that you can draw on a sheet of paper. But can you start by looking at that line and then figure out what functions drew it? Remember that you have the weights for the function that drew it, by definition. So the analogy is not "How did you get to 84? Was it 2 x 42, or 7 x 12, or 83 + 1, or…? Because you don’t just have two points. You have the entire line, no matter what its shape is.
We have the weights, bias the linear equation and activation functions to do as you said. We can try and find out the equation as you said. May be we will have some interesting findings
If you are creating a new architecture, (not transfer learning), the forward method that you write are the list of equations. If you create a new model with similar model and assign weights of old model it would work. I am not sure if there is a automated library that can generate a equations out of functions in the network though. It might need lot of manual effort
I’m wondering if it’s possible to describe (or even to show) a simple example. When you say ‘the forward method that you write are the list of equations,’ are they also just a line? Jeremy said in Lesson 6, “So ‘forward’ is a special PyTorch method name. It’s the most important PyTorch method name. This is where you put the actual computation.” Without even thinking about what the function is, what would you do to display that line or figure out what that computation is? What displays that line? Is it a series of points in space that are arrived at as the dot product of matrices, or the values in those matrices before they’re multiplied together, or the calculated result of these calculations which somehow ends up as a point? In other words, what does the manual effort involve?
@quantum this is hard to visualize in general case since often you are dealing with a very high input dimensionality for example if you are classifying a 224x224 image the function your model realizes has the domain of over 50 thousand dimensions.
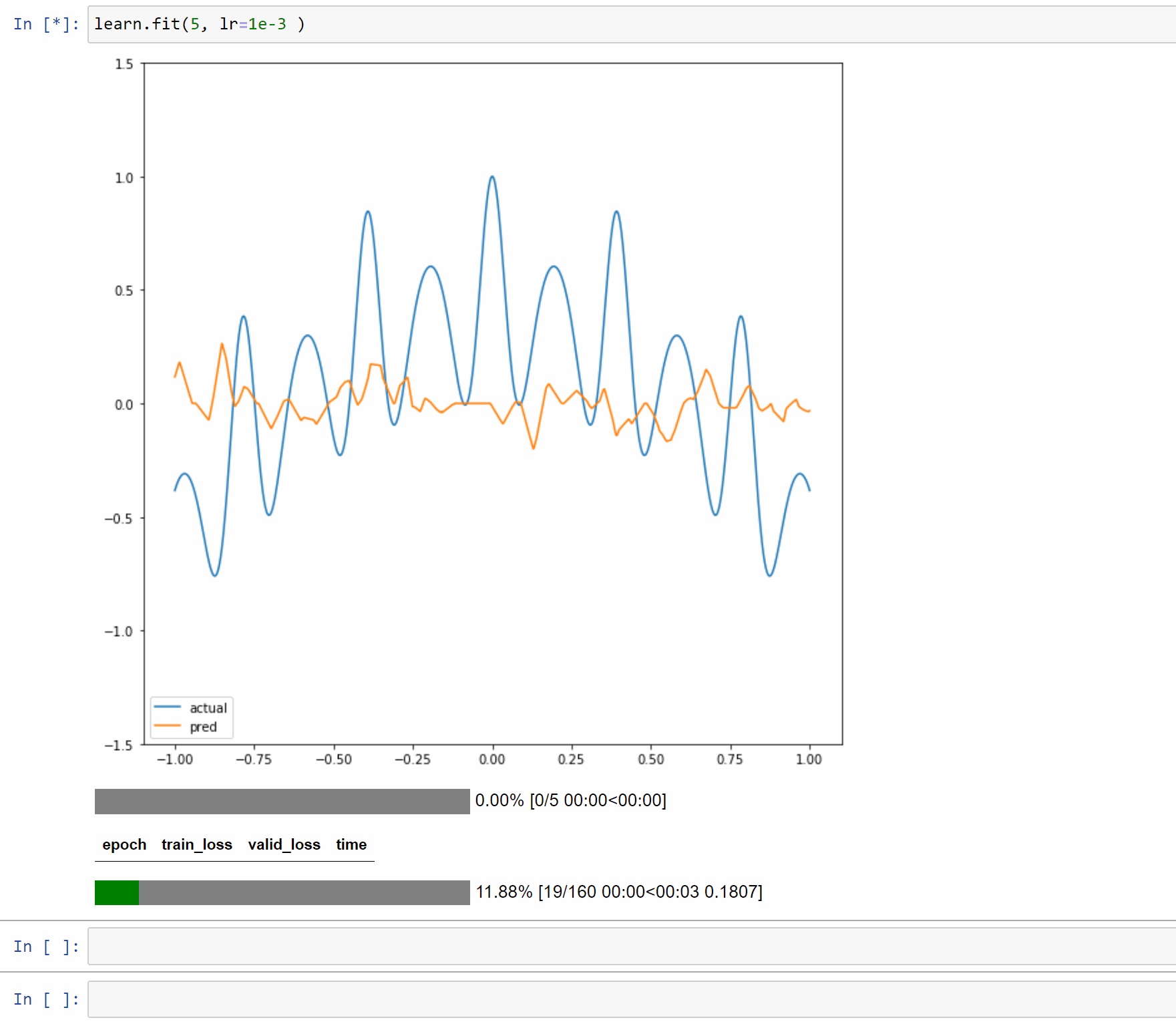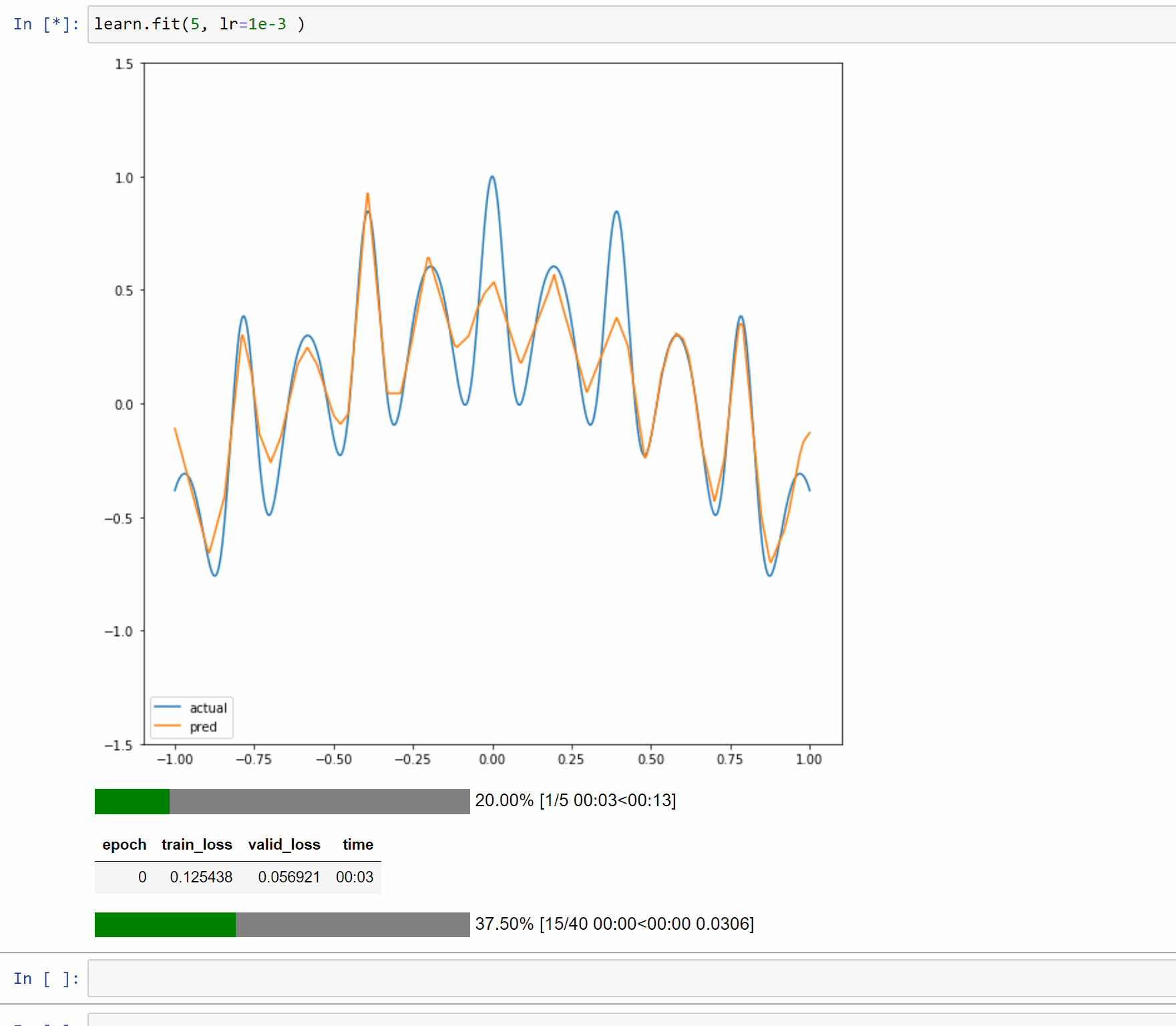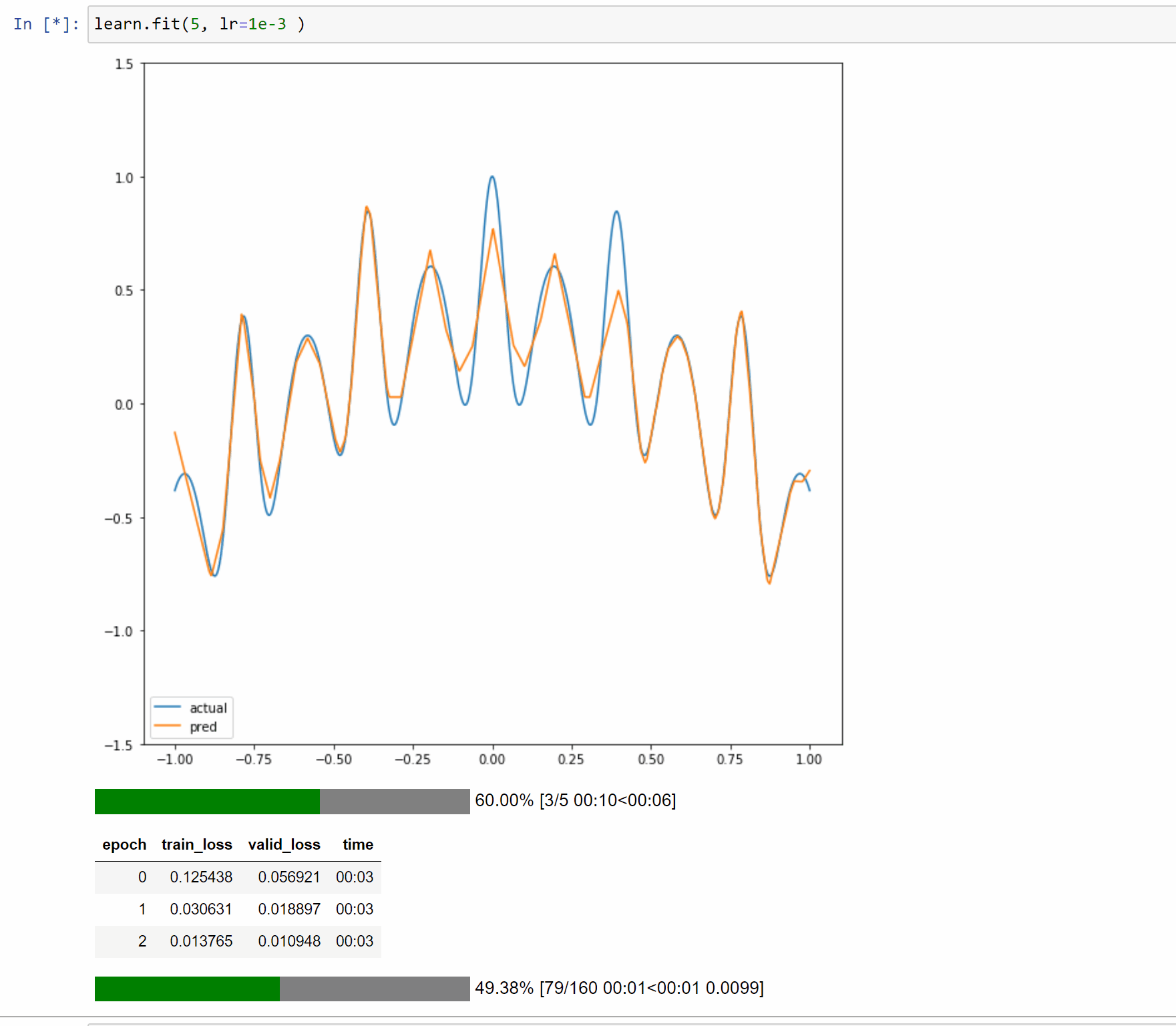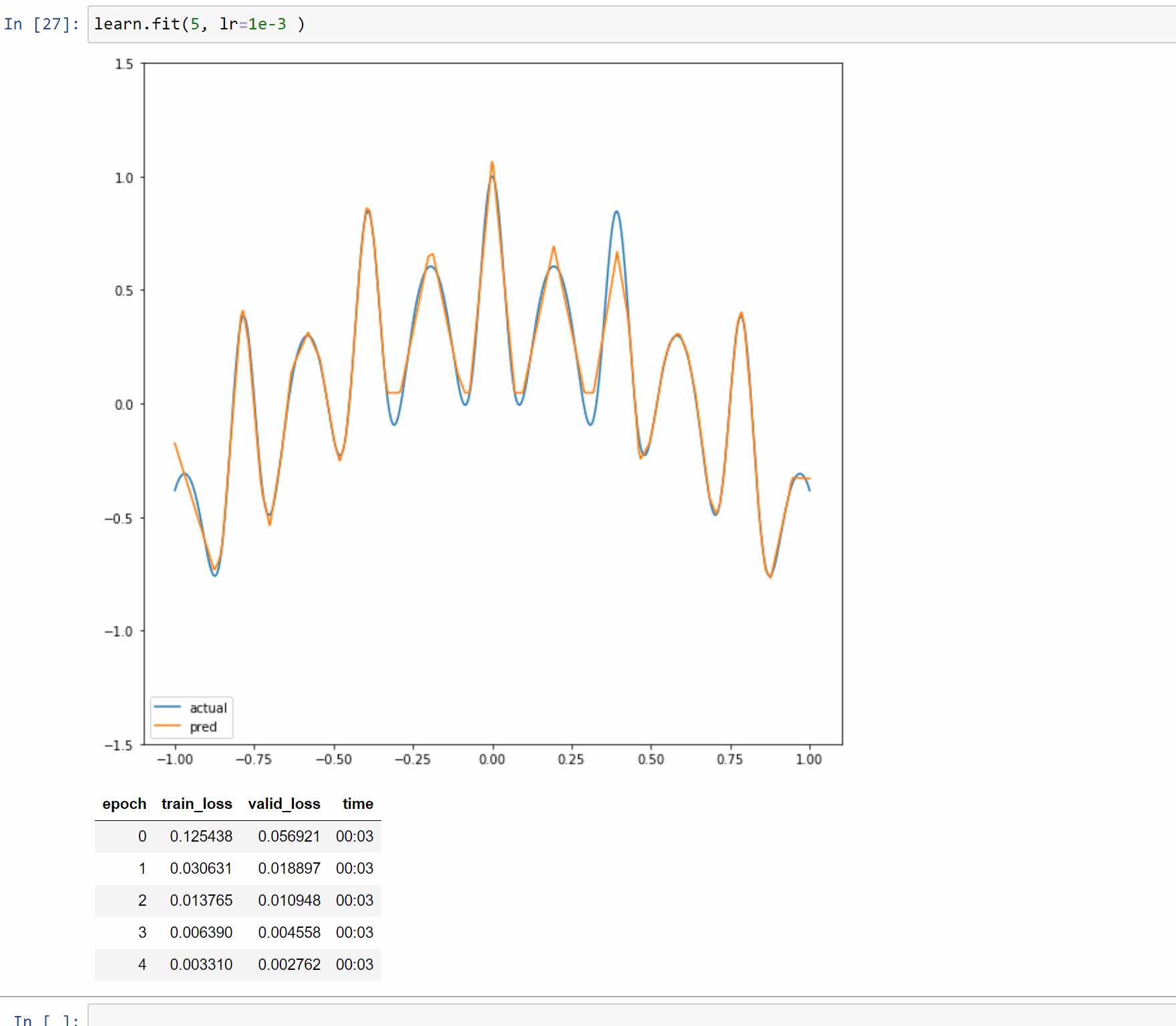
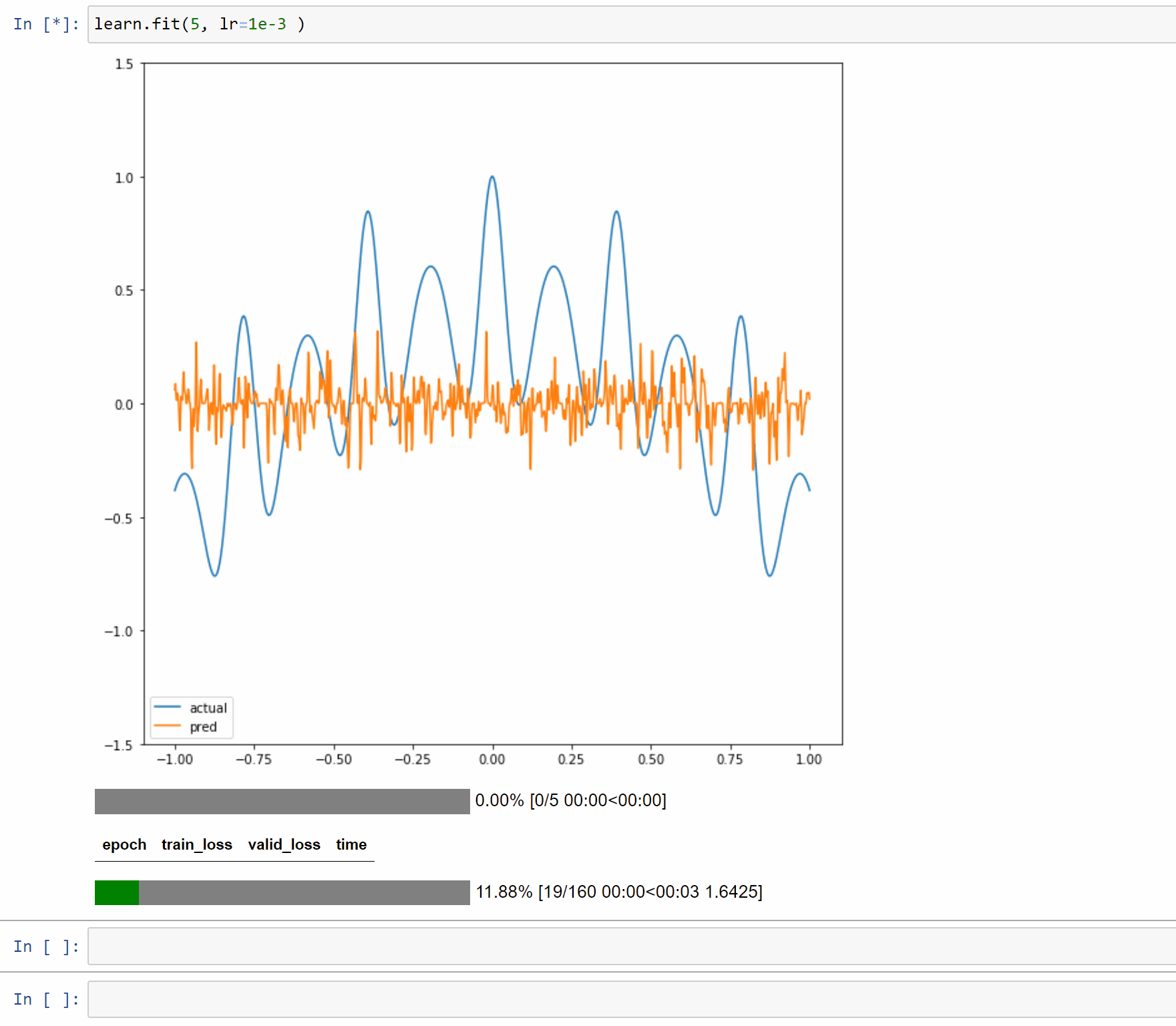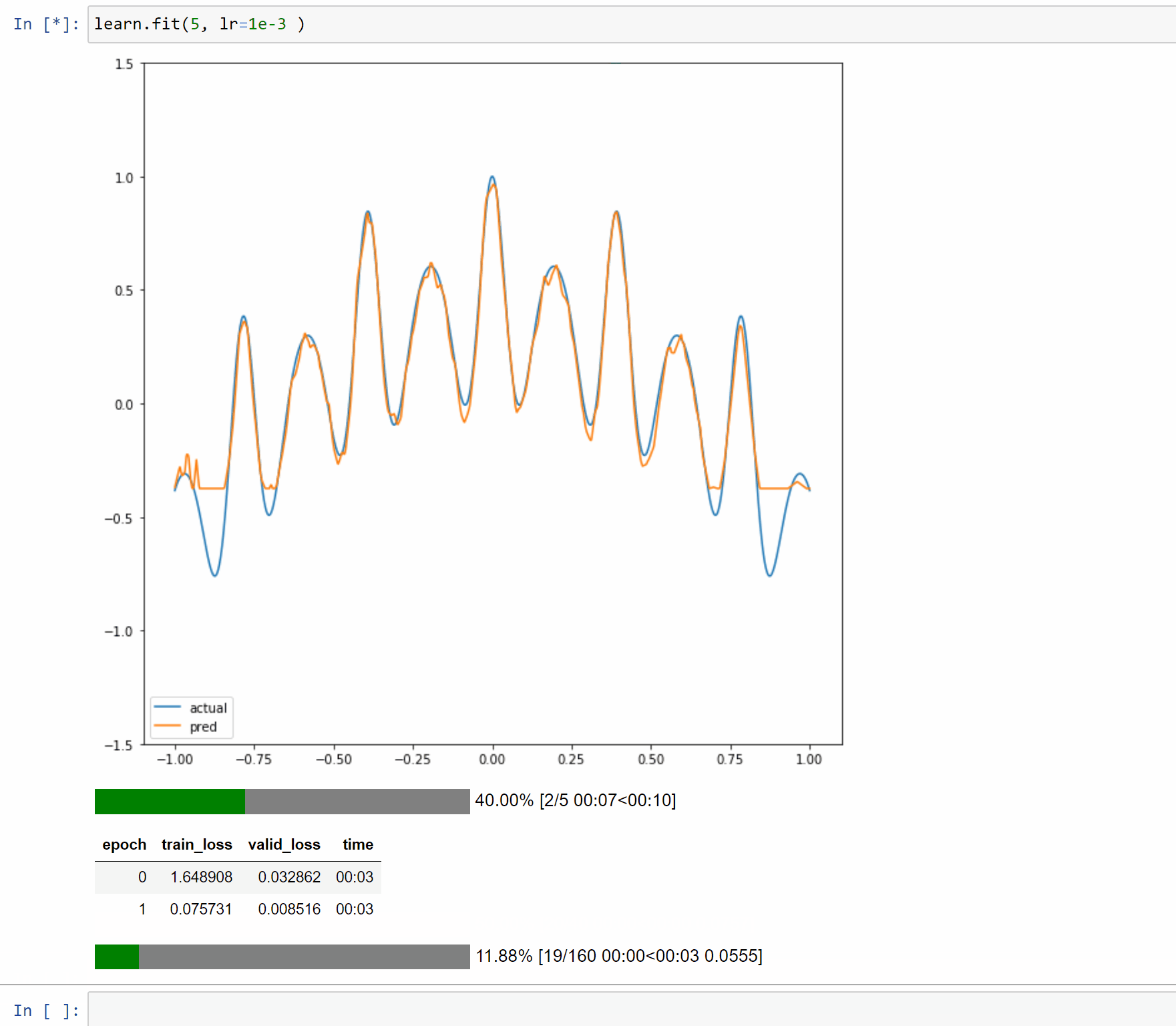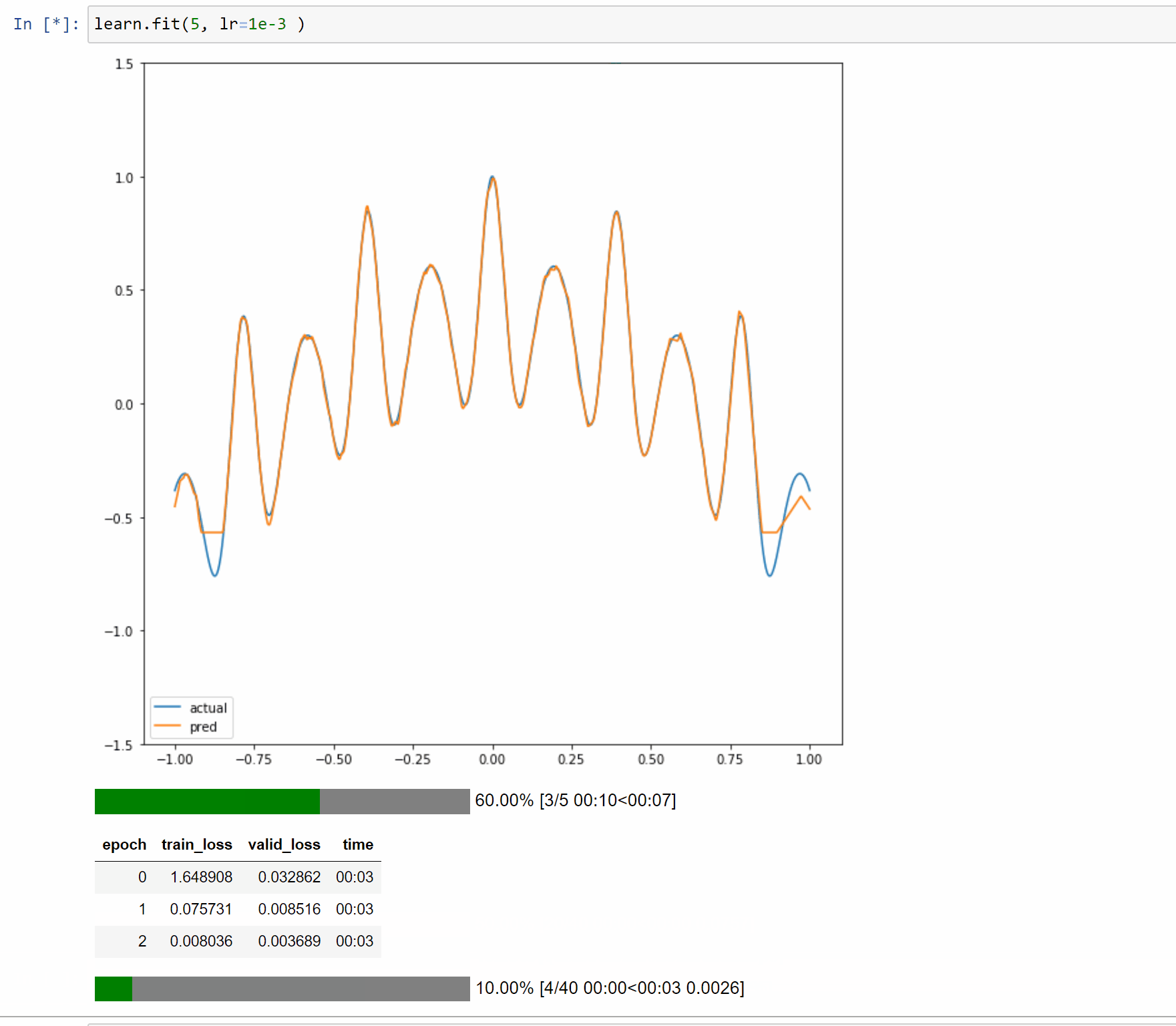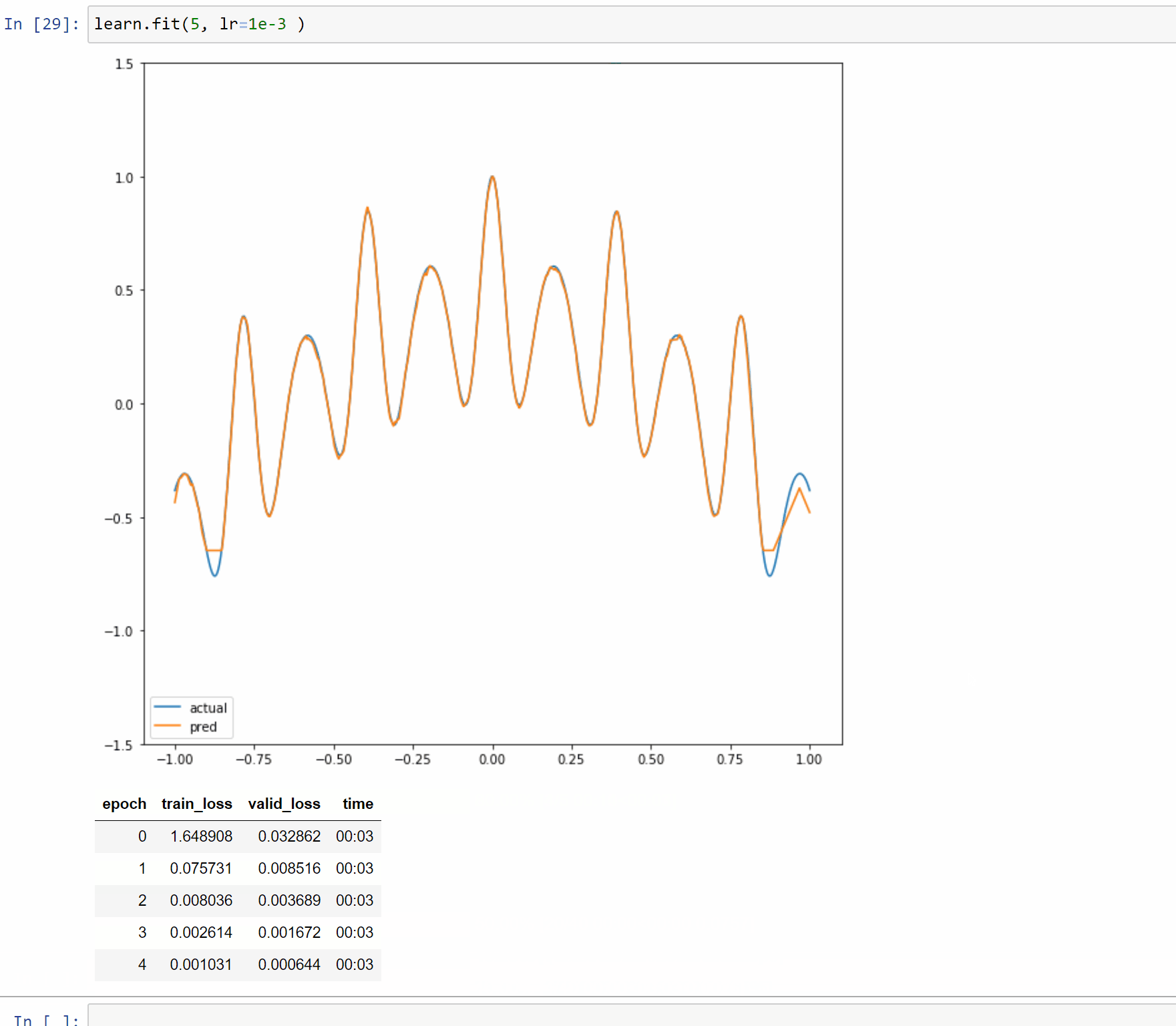
I’ve created a toy example notebook with a single layer model to approximate 1D functions. In this case the forward method is just a few simple computations so it makes it easy to reason about and display.
The notebook is Here so you can play with different functions and input size.
Also a binder instance to run interactively in a browser.
Here are examples on running it with 5, 50 and 500 neurons.
Thanks again for that amazing work. I’ve been thinking about this every day.
So to summarize: you created a wavy line by writing a function, and then you graphed it . You then ran a neural network against the line that was drawn, essentially treating it as a series of target data points. By the universal approximation theory and back propagation, you were able to bring to life an animated illustration of that approximation happening. Which is marvelous.
Two questions. 1) In, for instance, image recognition, you start with an input, and you shoot at a far-off target. So the input is the image, and the target is the label. The difference is that there is no wavy line that we’re trying to fit to. All we know is that we’ve got to end up getting that label right. So we come up with this series of numbers which get us there, and we do it for all the other rows as well. Since there is no line, what are we approximating? Do we end up getting the equivalent of a line? For each row, and also for all rows?
“the function your model realizes has the domain of over 50 thousand dimensions”
What is a ‘dimension’? I’ve been thinking about how many of these we can identify. Is it the assumption that we (unconsciously or consciously) recognize all of these dimensions, and that that’s what makes up the recognized object? Are these dimensions all on the same level, or do they, in combination, make up higher-order concepts, just as we do? If we have no idea what these dimensions are, then why are we even calling them ‘dimensions’?
So: 2) What is a ‘dimension’?
[Side note for distraught grammarians: I know you’re supposed to put a comma or period or question mark before a closing quotation mark. But I think that’s often wrong – better to keep the brackets around the thing you’re looking at. True in programming syntax, true for vision, true for language, and true here for me.]
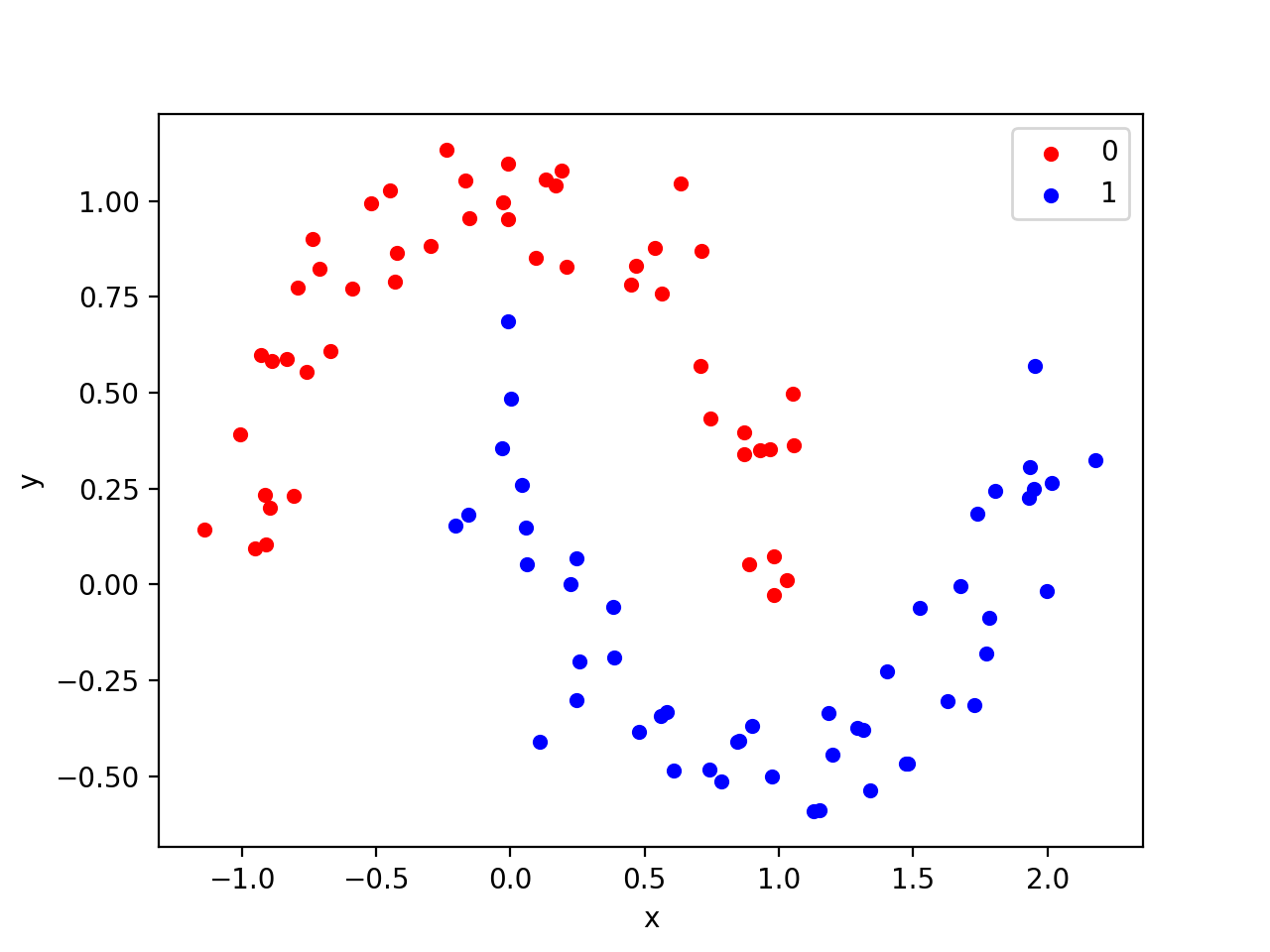
You have to imagine that there exists a function we want to approximate. See the example bellow for classifying 2D objects (points), you can draw a line that has blue points on one side and red on the other. And so you can create a neural network that does that.
Now if you have points in 3D you can also divide them, but instead of a wavy line you’d have to imagine something like a wavy surface. You can extend it to as many dimensions as you want, though it gets harder to imagine or visualize it that way.
I use the term in the linear algebra sense. I.e. a vector of N numbers is a point in an N-Dimentional space. And so a neural network that takes N inputs and returns one output is a function RN → R1.
Going back to the image example, if you have a 100x100 pixels grayscale image that’s 10000 pixels, each with a numeric value, so the image is represented as a vector with 10000 dimensions and that’s the domain of the function we try to find.
Disclaimer: I’m neither teacher nor a scholar, I’m glossing over details and simplifying things here. My best advice to get an understanding of how it all fits together is to actually carefully watch the Jeremy’s lectures here and do your own experiments
My understanding ,at a high level, although I can’t remember exactly were (On Coursera) or who (Hinton or Andrew Ng) put it in my head is :
The Universal Approximation Theory is just averaging the residual errors and going round again until they match. When I find my source I will post here.
Here is another link to I think the originator Cybenko 1989
Hi David @quantum. I like that you are curious about these questions. I’ll offer my take on them, but know it’s my own opinions mixed with facts. And I am not a great mathematician.
I think it’s best not to get too hung up on this Universal Approximation Theorem. It is an existence proof only, and does not offer any great insights about how to set or train weights in practice. Mathematical existence theorems are usually proved using other existence theorems which, if you trace them all the way down, reduce to a klunky but provable construction of the solution. In the case of the UAT, I have seen constructions made from step functions and sigmoids. No one ever would use such constructions in practice because they are too inefficient computationally in terms of units and processing. And no one would be interested in the equations for that construction because (besides being highly verbose) they would offer no insight into the function being approximated.
At best, the UAT tells up we are not trying to do an impossible task when training a machine learning network. There’s some comfort in knowing that - at least we are not wasting our efforts. But the UAT does not help with the actual practice of machine learning: which architecture to choose, how to train to a usable accuracy in a reasonable amount of time.
As for reversing a trained network, a model made up of Linear’s and ReLU’s approximates a curvy function as a series of straight line segments. (Bounded hyperplanes in higher dimensions.) It can’t make curves. But if you use enough units it gets as close to a curve as you want. The model happens to be simple enough that you could write down the equations and understand them. However, those equations are never going to tell you “this is a parabola”.
Likewise, every complex model can be written a giant equation, but I think what you are asking for is insight into the meaning of that equation. People currently use various method to make sense of the equation: activation maps, ablation studies, PCA, for example. I personally suspect and hope that someday machine learning will be able to extract and express higher level concepts that humans can relate to. But today they are merely very capable numerical approximators.
HTH a bit.
P.S. I recently skimmed a paper called “AI Feynman”. Maybe what they are doing is closer to what you want to be able to do. https://arxiv.org/abs/1905.11481
For me, it’s more than curiosity. I think it is fundamental to the advancement toward general AI.
Agreed. But without the UAT, none of this works. I understand your point about approximating curves, down to any arbitrary level of accuracy. But about this:
Why not? How is this different from taking a bunch of images of parabolas and labeling each as such, and then trying to get as close to 100% as possible using a CNN for image recognition? I’d think that would be a lot simpler than trying to distinguish grizzly bears from brown bears. In other words, if in fact it turns out to be a parabola, the NN should have no trouble in ‘recognizing’ it as one.
But in actual practice it will rarely turn out to be something so easily recognizable (and this is, importantly, recognizable by us, by human beings). On a more abstract level, this raises some startling questions, beginning with: "We are training a machine to ‘recognize’ objects in our world. They can only do so using this UAT, which requires that the recognized objects are able to be fit to a continuous linear function. What does this imply? Does this mean that perception and recognition, for us as humans, is also a linear function? (The fact that computers require this does not mean that humans do, but then again, it well might, and very likely does at least in part.)
That AI Feynmann paper looks very interesting. If anyone knows how to explain the math, please let me know.
These are very interesting questions and I support you to investigate them further. But I think I have said all I have to address the topics. Will be interested to know what you figure out.
I am impressed by @slawekbiel 's notebook and explanation.
I have just updated the callback function, begin_fit --> before_fit (is it a recent change in fastai API?) But it is causing some glinch when updating the graph.
I like your animated gif. How have you created them by the way?
The Universal Equation Solver: A Simple, New Method for Microcomputers 1983 is a very old book which solves how to solve various equations using approximation and damping. I came across it by chance. Now most equations do not have decimal answer sqrt(2) = 1.4 but 1.4*1.4=1.96 so why should the optimal number of baked beans in my store be an integer. Hence deep learning is only every going to be right 99.99% of the time and tomorrow 99.97% so although I like the idea of the universal approximation theorem I think we need to treat it as a tool rather than the key to the universe.