Mikonapoli. Thanks for doing the work
Hi, is there any docs about TextClassificationInterpretation? I can’t find in https://docs.fast.ai/. Thanks a lot!
No, this is a new experimental feature developed by @herrmann
1 Like
May I add this to the docs in the text.learner section? Mirroring the vision.learner?
A small example might be helpful there.
By all means! Any PR to make the docs better is more than welcome.
1 Like
PR is out there!
Hi,
I’ve wrote a method called show_top_losses() to enhance TextClassificationInterpretation inspired by plot_top_losses in vision.learn.
This method can creates a tabulation showing the first k texts in top_losses along with their prediction, actual, loss, and probability of actual class.
like this: (on my own dataset)

my code:
def show_top_losses(self, k:int)->None:
table_header = ['Text', 'Prediction', 'Actual', 'Loss', 'Probability']
table_data = []
tl_val,tl_idx = self.top_losses()
for i,idx in enumerate(tl_idx):
tx,cl = self.data.dl(self.ds_type).dataset[idx]
cl = cl.data
classes = self.data.classes
tmp = (self.cut_by_line(tx.text), f'{classes[self.pred_class[idx]]}', f'{classes[cl]}', f'{self.losses[idx]:.2f}', f'{self.probs[idx][cl]:.2f}')
table_data.append(tmp)
k -= 1
if k==0: break
print(tabulate(table_data, headers=table_header, tablefmt='orgtbl'))
def cut_by_line(self,text):
res = ""
width = 80
lines = len(text) // width
if lines == 0:
res += text
else:
for i in range(lines):
res += text[i * width:(i + 1) * width] + '\n'
res += text[(range(lines)[-1] + 1) * width:]
return res
I thought it is useful to me. May I add this to awd_lstm.py?@sgugger
3 Likes
That looks useful, don’t hesitate to suggest a PR with it!
1 Like
thanks! PR is here 
2 Likes
Thank you. I will definitely use this!
1 Like
From: Sequential Jacobian section at https://www.cs.toronto.edu/~graves/preprint.pdf
However it should be stressed that
sensitivity does not correspond directly to contextual importance. For example,
the sensitivity may be very large towards an input that never changes, such
as a corner pixel in a set of images with a fixed colour background, or the
first timestep in a set of audio sequences that always begin in silence,
I believe this explains why xxbos has high sensitivity. Maybe you can ignore it in gradient normalizations to better see the relative sensitivity of the actual tokens.
Possibly, but I guess I would expect xxbos to always be highlighted since it starts every sequence. When running on my target data set with longer sequences the special character xxbos was rarely highlighted. But other special characters like xxmaj and xxup were highlighted fairly often. Overall this technique produced some really interesting results.
Can anyone tell me from where to import ‘TextClassificationInterpretation’?
It should be under fastai.text.intepret. You may also use an IDE like vscode to search class definitions, I do that whenever I want to look up something 
Thanks for your advice.
I have searched it earlier(before writing here) as you suggested and also in some other modules but its neither in the module you suggested nor at other modules I searched.
I could find ‘ClassificationInterpretation’ but not the ‘TextClassificationInterpretation’.
Again the associated attributes after importing ‘ClassificationInterpretation’ is not found.

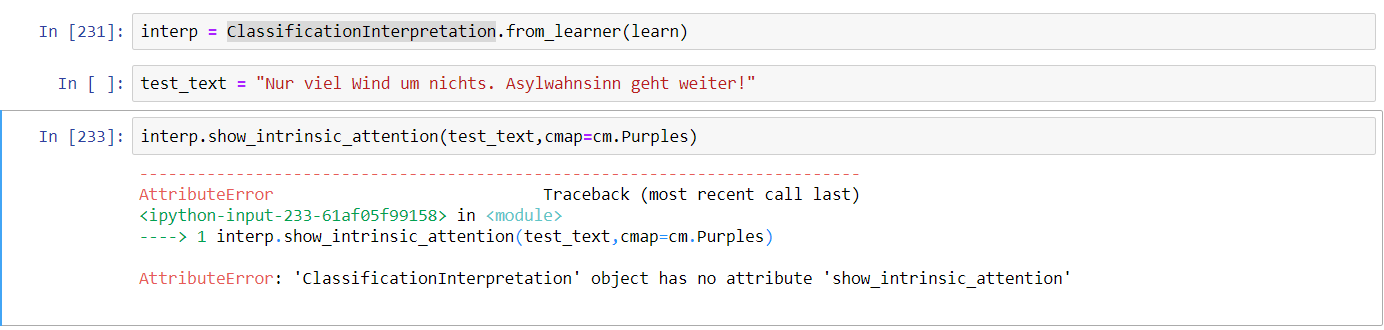
You miss the interpret module all together. Try doing the latest dev install.
Here is the source code:
Thanks.
Sorry for bothering you, as I still have a question.
Actually, I am running a standalone notebook without Developer Install.
I am just running pip install -U fastai to update the fastai library.
But it is not recognizing fastai.text.interpret. Do you know, if Dev install can only solve this problem?
Yes dev install will get you master
1 Like