Any resources, explanations, or discussions pertaining to the cold start problem are welcome here!
Link to the part of the lesson 4 video where Jeremy talked about the cold start problem:
The associated text transcript from my notes:
The cold start problem is at the time you particularly want to be good at recommending movies is when you have a new user and the time you particularly care about recommending a movie is when it’s a new movie but at that point you don’t have any data in your collaborative filtering system and it’s really hard.
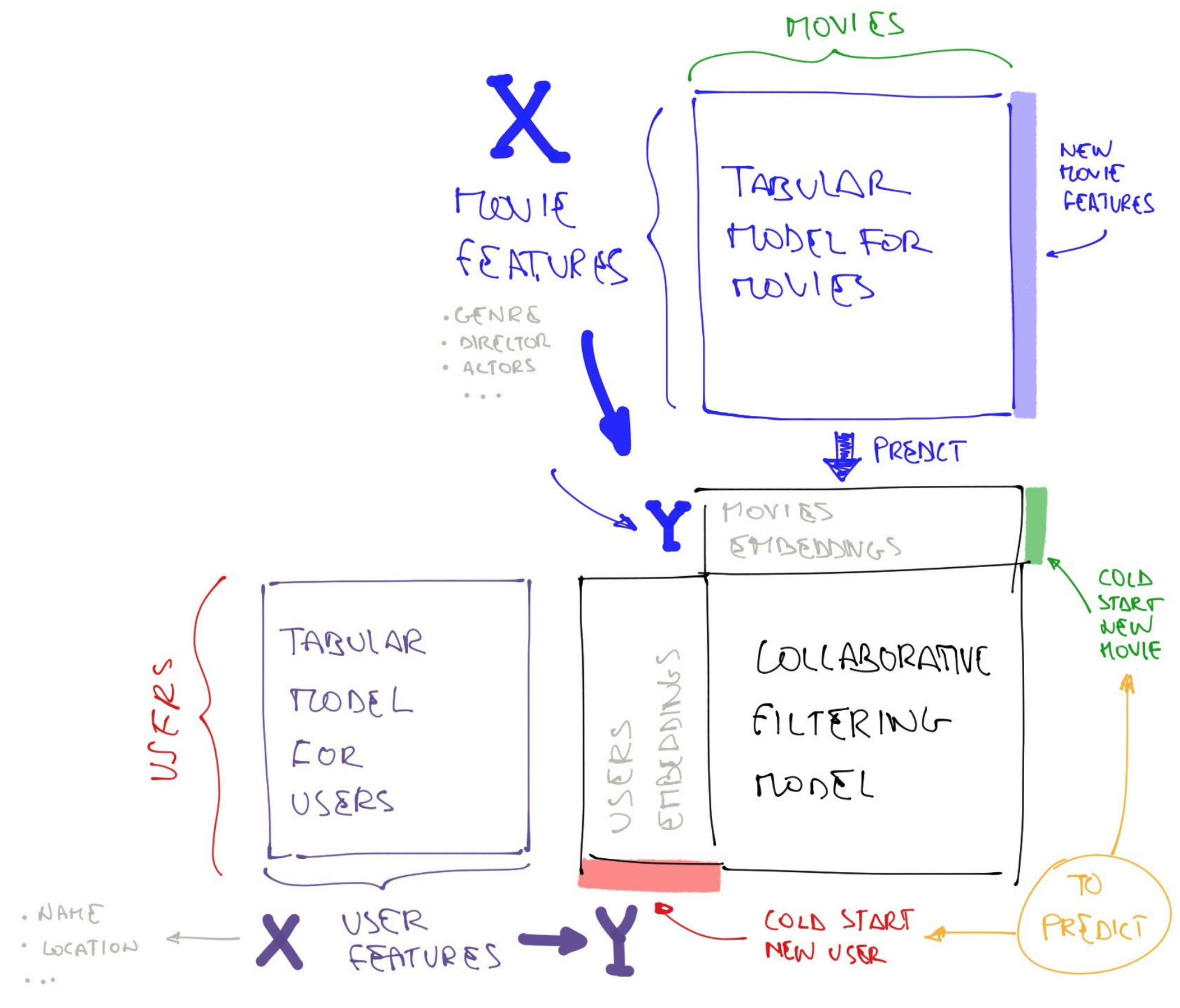
As I say this, we don’t have anything built into fastai to handle the cold start problem and that’s really because the cold start problem the only way I know of to solve it in fact I think that conceptually can solve it is to have a second model which is not a collaborative filtering model but a metadata driven model for new users or new movies.
I don’t know if Netflix still does this but certainly what they used to do when I signed up to Netflix where they started showing me lots of movies and saying have you seen this, did you like it. Netflix fixed the cold start problem through the UX (User Experience). So, there was no cold start problem they found like 20 really common movies and asked me if I like them. They used my replies to those 20 to show me 20 more that I might have seen and by the time I had gone through 60, there was no cold start problem anymore. And for new movies, it’s not really a problem because like the first hundred users who haven’t seen the movie, they go in and say whether they like it and then the next hundred thousand, the next million, it’s not a cold start problem anymore.
But the other thing you can do if for whatever reason kind of can’t go through that UX of like asking people did you like those things, so for example if you’re selling products and you don’t really want to show them like a big selection of your products and say did you like this because you just want them to buy, you can instead try and use a metadata based kind of tabular model, what geography did they come from, maybe their age and sex, make some guesses about the initial recommendations. Collaborative filtering is specifically for once you have a bit of information about your users and movies or customers and products or whatever.
5 Likes
Maybe we can train a tabular regression model for users or movie that predict the embedding vector and use the known embeddigs of collaborative filtering model as train/valid set 
3 Likes
There are smarter people than me who have looked at this and since the research/findings/intuition is not in this post I want to ask a question. What is wrong with listing the attributes of current/known users (only attributes that a new user would give you) and the attributes of current/known movies and put all of that data in a table and train the model to predict the rating the user gave that movie? Then group the known users, find a centroid for the group (based on the known attributes), then compare new users to the centroid, then find the average parameters for the group and give the new user those parameters.