Thanks for all the help. Still not working though.
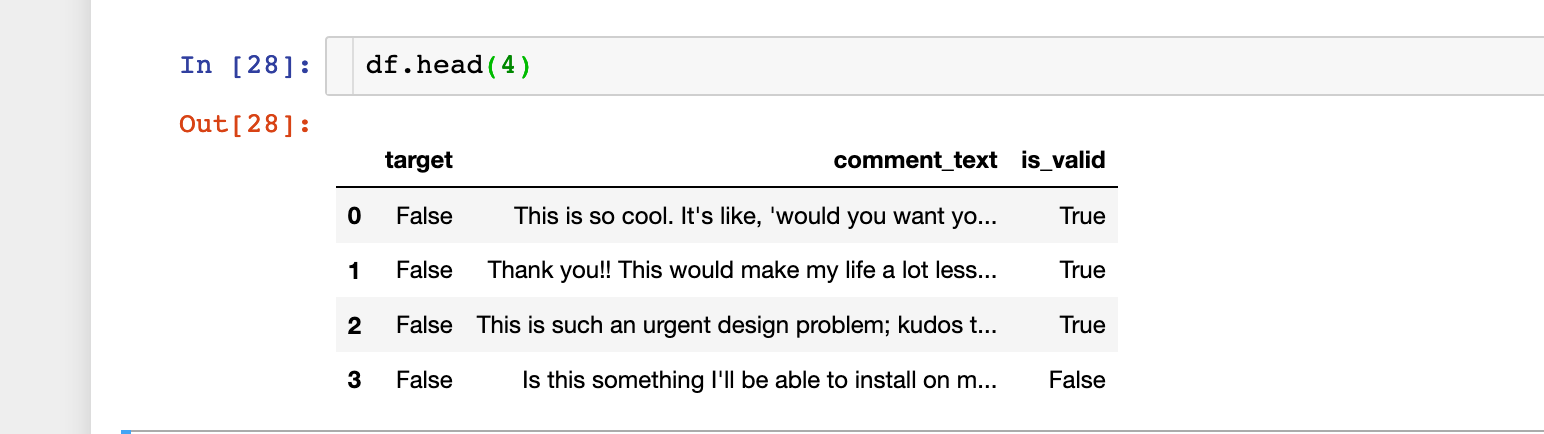
Here is the data:
Here is the code:
bs = 4
data = (TextList.from_df(df, PATH, cols='comment_text')
.use_partial_data(0.2)
.split_by_rand_pct(0.2)
.label_from_df(cols=0)
.databunch(bs = bs))
data.save('data_lm.pkl')
data = load_data(PATH, 'data_lm.pkl', bs = 4)
gc.collect()
learn = language_model_learner(data, AWD_LSTM, drop_mult=0.3)
learn.fit_one_cycle(2, 1e-2, moms=(0.8,0.7))
Here is the error:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-27-92ddd2cbbe29> in <module>
----> 1 learn.fit_one_cycle(2, 1e-2, moms=(0.8,0.7))
/opt/anaconda3/lib/python3.7/site-packages/fastai/train.py in fit_one_cycle(learn, cyc_len, max_lr, moms, div_factor, pct_start, final_div, wd, callbacks, tot_epochs, start_epoch)
20 callbacks.append(OneCycleScheduler(learn, max_lr, moms=moms, div_factor=div_factor, pct_start=pct_start,
21 final_div=final_div, tot_epochs=tot_epochs, start_epoch=start_epoch))
---> 22 learn.fit(cyc_len, max_lr, wd=wd, callbacks=callbacks)
23
24 def lr_find(learn:Learner, start_lr:Floats=1e-7, end_lr:Floats=10, num_it:int=100, stop_div:bool=True, wd:float=None):
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(self, epochs, lr, wd, callbacks)
197 callbacks = [cb(self) for cb in self.callback_fns + listify(defaults.extra_callback_fns)] + listify(callbacks)
198 if defaults.extra_callbacks is not None: callbacks += defaults.extra_callbacks
--> 199 fit(epochs, self, metrics=self.metrics, callbacks=self.callbacks+callbacks)
200
201 def create_opt(self, lr:Floats, wd:Floats=0.)->None:
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in fit(epochs, learn, callbacks, metrics)
99 for xb,yb in progress_bar(learn.data.train_dl, parent=pbar):
100 xb, yb = cb_handler.on_batch_begin(xb, yb)
--> 101 loss = loss_batch(learn.model, xb, yb, learn.loss_func, learn.opt, cb_handler)
102 if cb_handler.on_batch_end(loss): break
103
/opt/anaconda3/lib/python3.7/site-packages/fastai/basic_train.py in loss_batch(model, xb, yb, loss_func, opt, cb_handler)
28
29 if not loss_func: return to_detach(out), yb[0].detach()
---> 30 loss = loss_func(out, *yb)
31
32 if opt is not None:
/opt/anaconda3/lib/python3.7/site-packages/fastai/layers.py in __call__(self, input, target, **kwargs)
265 if self.floatify: target = target.float()
266 input = input.view(-1,input.shape[-1]) if self.is_2d else input.view(-1)
--> 267 return self.func.__call__(input, target.view(-1), **kwargs)
268
269 def CrossEntropyFlat(*args, axis:int=-1, **kwargs):
/opt/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
/opt/anaconda3/lib/python3.7/site-packages/torch/nn/modules/loss.py in forward(self, input, target)
902 def forward(self, input, target):
903 return F.cross_entropy(input, target, weight=self.weight,
--> 904 ignore_index=self.ignore_index, reduction=self.reduction)
905
906
/opt/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in cross_entropy(input, target, weight, size_average, ignore_index, reduce, reduction)
1968 if size_average is not None or reduce is not None:
1969 reduction = _Reduction.legacy_get_string(size_average, reduce)
-> 1970 return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
1971
1972
/opt/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in nll_loss(input, target, weight, size_average, ignore_index, reduce, reduction)
1786 if input.size(0) != target.size(0):
1787 raise ValueError('Expected input batch_size ({}) to match target batch_size ({}).'
-> 1788 .format(input.size(0), target.size(0)))
1789 if dim == 2:
1790 ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
ValueError: Expected input batch_size (1640) to match target batch_size (4).
I’m going to try the same without the data block. Just the quick fix like in the documentation examples.