Hello,
I’m training an ULMFiT model for text classification, starting with a language model - but I think the length of data present in my TextDataLoader is incorrect.
I ran:
dls_lm = TextDataLoaders.from_df(ans,
text_col=wandb.config.text_col,
is_lm=True,
seq_len=wandb.config.seq_len
)
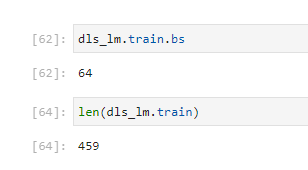
Using the DataFrame “ans” which has 101618 rows. I noticed while it was training that it had fewer batches than expected. It runs 459 batches, with batch size 64 (double checked), meaning it’s using just 29,376 samples for training. Am I misunderstanding the lengths and batch size values? Or is it throwing away data?
I checked and there are no nulls in the text field of the DataFrame I’m passing in.