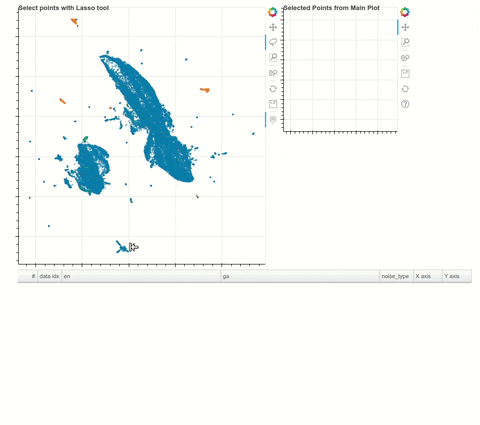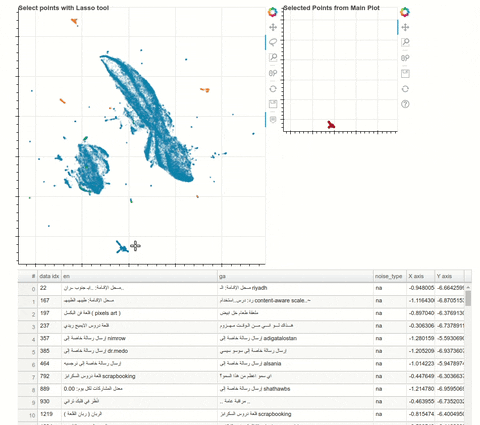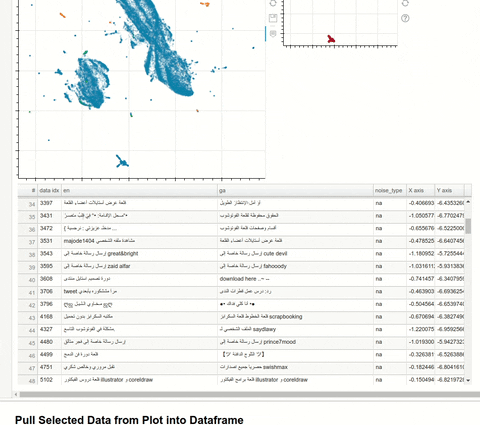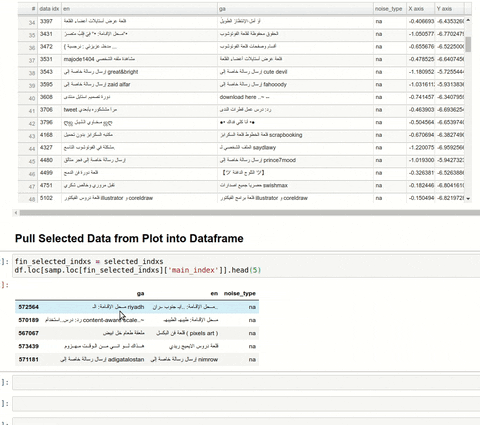
Just sharing an article I wrote recently about how you can explore a text dataset and visualise word or sentence embeddings (extracted via XLM-Roberta) with UMAP and then select and extract datapoints of interest into a dataframe. I found Arabic, cryllic and other text anomalies in my English-Irish dataset with this!
Gif demo:
My main use case was to calculate an average “bad” embedding for certain noisy clusters from a sample (40k rows) of web-scrapped data, from which I could then identify similar “bad” datapoints in my larger (680k rows) dataset. Worked like a treat!
You can open the article below on Github as a notebook and use the code for your own text exploration and cleaning too.
(@hallvagi has a great post here too doing something similar but for exploring word embeddings with UMAP which I’d recommend reading)
Something I want to do is see if I can grab the document embeddings from transformer models, and see if I can meaningfully apply something like PCA to group related documents. If you have any tips, tricks, best practices, and/or insights … lmk if you can
It would be interesting to see how PCA does. UMAP seems like the business, if there is one link that I would suggest reading from all those I mention is would be this one which gives a nice overview of UMAP, including comparison with t-sne
If you start to calculate similarity distances I would stick with the good ole cosine distance functions from Sci-kit Learn or Scipy. Playing around with tools like NMSLib/annoy was fun but unless you need an index for something like high volumes of search queries in production its probably not worth the time testing and waiting for it to generate an index for a lot of data.
Grabbing the embeddings from the pre-trained models is pretty simple as you’d know, one thing thats worth playing with is grabbling multiple embeddings from layers and concatting them. I read (somewhere?) that someone had found richer/more meaningful representations from BERT when they concatted the embeddings from the last 4 layers.
Its also worth labelling a few similar document types that you know are similar (maybe they share specific technical jargon for example) to check whether things are being grouped as expected.
Looking forward to hearing how it goes, let me know if there is anything more specific I can help anwer!
Yah I’ve played with this before and was nice because I’m dealing with several hundred/thousands documents at a time (for example, all the comments for a survey).
I really found this a very useful way of quickly gaining a high level understanding of a large unknown corpus. Since XLM-R is multilingual you can also just use it as is with many languages. I tested it with Norwegian (fairly close to English to be fair), and got good results. The total run time for processing 25k documents was also only around 20 minutes. Doing a first scan like this can lead to many insights into your corpus which would otherwise require a lot of reading time.
In my experience PCA seems to clump most of the data points together, and t-SNE/UMAP simply gives much more interesting results. Chris Olah, btw, has a very nice post on dimensionality reduction. t-SNE/UMAP also sometimes require a bit of fiddling to give great results, see e.g. this distill article.
UMAP/t-SNE does suffer a bit though when the data size grows. One possibility is to use PCA first, to get the data into a more manageable size. Also, the sklearn t-SNE is very slow compared to UMAP, but RAPIDS have GPU accelerated implementations which makes both algorithms much faster, see eg. t-SNE and UMAP.
Finally, t-SNE results seems to be dependent on how it is initialized. I haven’t looked into this in much detail. But I couldn’t help thinking that there were some parallels to how nn’s need to be properly initialized in order to learn?
Anyway, I’m really interested in seeing other usecases of xlm-r + umap or similar!
Great work and blog post! That’s clearly an improvement over simple language detection, since your technique also allows to identify other text anomalies which are always present in web scraped data.
I’m also very interested in clustering the embeddings of longer documents. However, I suppose there is a length limit for encoding documents with transformer models such as XLM-Roberta. @morgan@wgpubs : do you know what’s the best way of handling this? Maybe processing the sentences in a doc separately and then calculating the average embedding?
Yah, for most of the models there is a length limit. Best thing to do is look at their docs … for example, since you mentioned XLM-Roberta, see here to understand what comes out of it and what goes into it.
There are newer models, like Longformer and Reformer, that work with longer sequences primarily because of changes they made to how the attention mechanism works. You may want to check those out too. Thanks to coding conventions, its pretty easy to take your code and make it work with whatever models you want.
Otherwise @wgpubs Reformer/Longformer solution could be an option (although you might have to do some pretraining if you’re not working with english docs)
Or else taking the averages could work yep.
Maybe concatenating the embeddings instead might work too (if you figure out a good way to deal with docs of different lengths)? Depends on your doc lengths too, not sure at what embedding size UMAP blows up! Using a smaller XLM-R model might help in producing a manageable embedding size.
Hi! If you are working in standard English, then I woudl look into models that don’t have this limitation, like XLNet or the QRNN used by Fastai!
Otherwise, there is no perfect solution. It seems like fine-tuning a model like XLNet to a new language is actually feasible (I can’t find a blog post I’m looking for now, but the idea is that you can fine tune from English to accelerate the process with good results, as long as you remember to also update the vocabulary).
Our experience is mostly in classification, but this probably works for embeddings as well; what has worked best for us is to train the model on random chunks of text and only in inference use the model for all chunks needed (splitting the text into blocks of 512 tokens for Bert, for instance) and then combining predictions or embeddings.
I’m thinking of applying this technique to product reviews that have been translated from different source languages (incl. Russian, German and Czech) to English using NMT. The goal is to a) identify poorly translated and noisy reviews and b) cluster the dataset into different types of reviews/topics.
I’ve already worked with QRNN and XLNet on text classification, so I’ll try these architectures first. But I’ll also start looking into Longformer and Reformer which sound very promising
Interesting, I wonder if you added native english reviews and then sampled, embedded and plotted the first n tokens (depending on your model choice) of both your translations and the native english would the distance between the translated english texts to the native english texts on the plot help identify poor translations…or maybe it’ll just group by subject/domain type, or the translations won’t mix at all with the native english…curious to see how it goes!
Doesn’t sound like big documents so I’d see if any of the pre-trained multi-lingual models work so you don’t have to risk losing info in the translation to English for non-English texts. It’s a win for you if you can do this as training a custom LM for ea. language against most any architecture, whether it be a transformer model or ULMFiT, is going to take considerable time and resources.
Re: ULMFiT, like Pablo, I’ve had good success with it for LM, document embeddings, and sequence classification tasks on English texts. For things like NER and summarization, I use huggingface with plans to explore using it for document embeddings and classification tasks as well to see how it compares with what I get from ULMFiT.
I’ve read both their papers and I lean towards using Longformer as it appears to be more friendly in customizing for various downstream tasks. I can’t remember why, but while Reformer may allow you to train on longer sequences than Longformer, there is something about it that limits its usability (or at least makes it difficult) for tasks outside of LM.
On average the documents are not very long but they do vary a lot in length and quite often the longest ones are the most informative. I guess I wouldn’t fit those for example in a sequence length of 512 using subword tokenization. Anyway, I already did some experimentation with training ULMFit on original language vs. auto-translated texts. Turned out that in my case the benefit of being able to use a larger training dataset (containing labeled examples from both Russian and German) outweighed any potential information loss due to translation errors. But I haven’t applied multi-lingual models so far.
I had the same experience for text classification. ULMFit actually outperformed fine-tuning Roberta or XLNet on my dataset. I think the reason behind it is that I have a large unlabeled dataset available for the language model fine-tuning step. Could you maybe share or point me to a notebook for extracting document embeddings from ULMFit? That would be super helpful.
Run through your dataset with whatever tokenizer(s) you are looking at and get some metrics on length (e.g., max, avg) to determine if you can fit everything.
There was for the v1. bits … not sure if there is anything out there for the v.2 bits. The hidden states for the documents are returned with both the LM and classification models so it should be pretty easy to loop through your batch, do a model(*xb), and collect them. There’s a good article showing how to do this with v1. here that should help.
You may want to search for document embeddings on the forum as its frequently discussed.