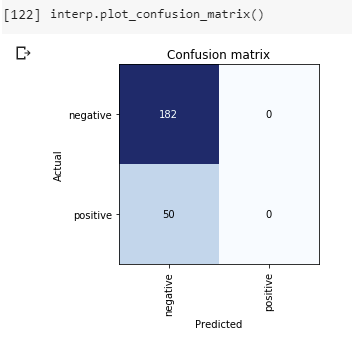
Hi, I’m building a text classification model in fastai. The problem is that when the model is complete, all predictions default to all negative and accuracy is about 80%. (The labels have an 80/20 frequency split.)
I can adjust the classification threshold within the nearest percentage integer to get from 0% to 71% sensitivity.
If I were using standard ML methods, I would apply some sort of hybrid sampling technique, but I’m not sure what to do here
When you split the data to train and test, make sure to do a stratified split. If you do value_counts on the test data set and look at the ratio or positive to negative labels, it should be representative of your original data set.
Give the above approach a try before you do the up-sampling the minority class approach.
Thanks for the advice. By stratifying my data, my AUC increased from .83 to .85 and the classifier.predict() gave probabilities that made much more sense.