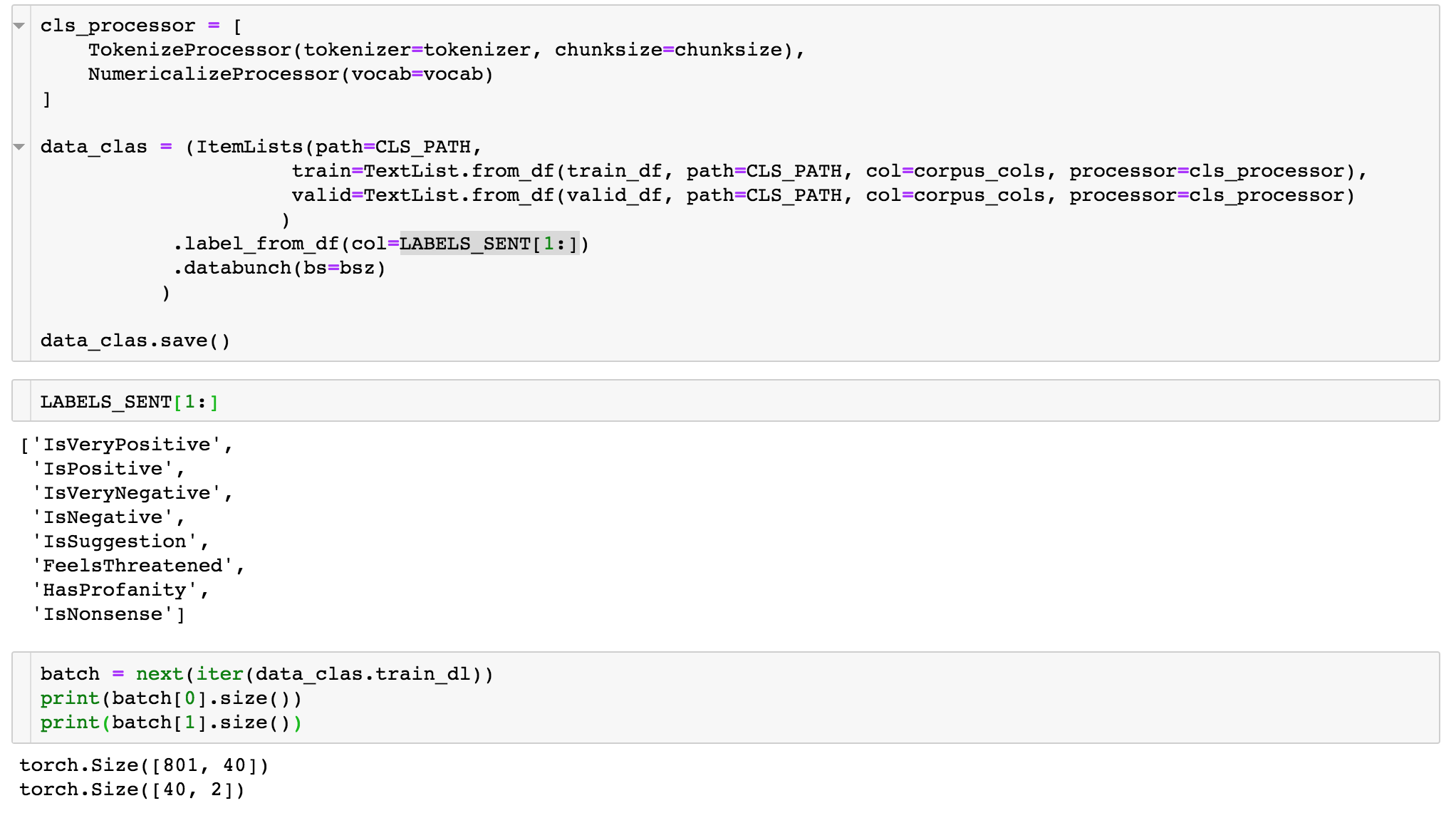
Attempting to build a multi-label dataset for text classification but the dimensions of the target batch size is wrong. It shows (40,2) when it should be (40,8)
Is there something else I need to do in the data block API to let it know this is a multi-label problem? Right now its determining the # of columns by distinct values (eg. 2 because they are all 0 or 1) instead of the number of labels (e.g., 8)
… and enjoy your multi-label classification training
For the core fastai dev team, I’d recommend that we simply incorporate what I did into the framework … so that if folks pass in multiple columns into .label_from_df, it would run the code at the top of this post. If you’d like a PR I’m glad to do it, but given this is a major change I leave it to you to lmk before I do anything.
I think we have already been through this particular issue before – you are correct, it did break with the new datablock API (as a lot of redundant code was refactored)
Looking at the latest codebase, I suspect it has something to do with the call one_hot that is part of the problem, not sure though.
How my DataFrame looks above makes sense to me, but perhaps it doesn’t make sense to fastai … so again maybe the/my real question is: “What should the Dataframe look like?”