Can anybody give some insights into the current text augmentation techniques in practice.
@darek.kleczek won a Kaggle competition by adapting some computer vision augmentations to text:
Hopefully this is helpful.
2 Likes
Yes, that’s creative to extrapolate image augmentation techniques to text 
There are a couple of text augmentation techniques I heard of ( I did not implement these techniques myself yet):
- Shuffle your text
- Train a word2vec embedding, and use this to alter your text with synonyms.
- Translate your text to another language and then translate it back to your original language.
Perhaps you can combine several techniques. Hopefully this helps 
This provides a good survey on Data Augmentation.
Data Augmentation Approaches in Natural Language Processing: A Survey
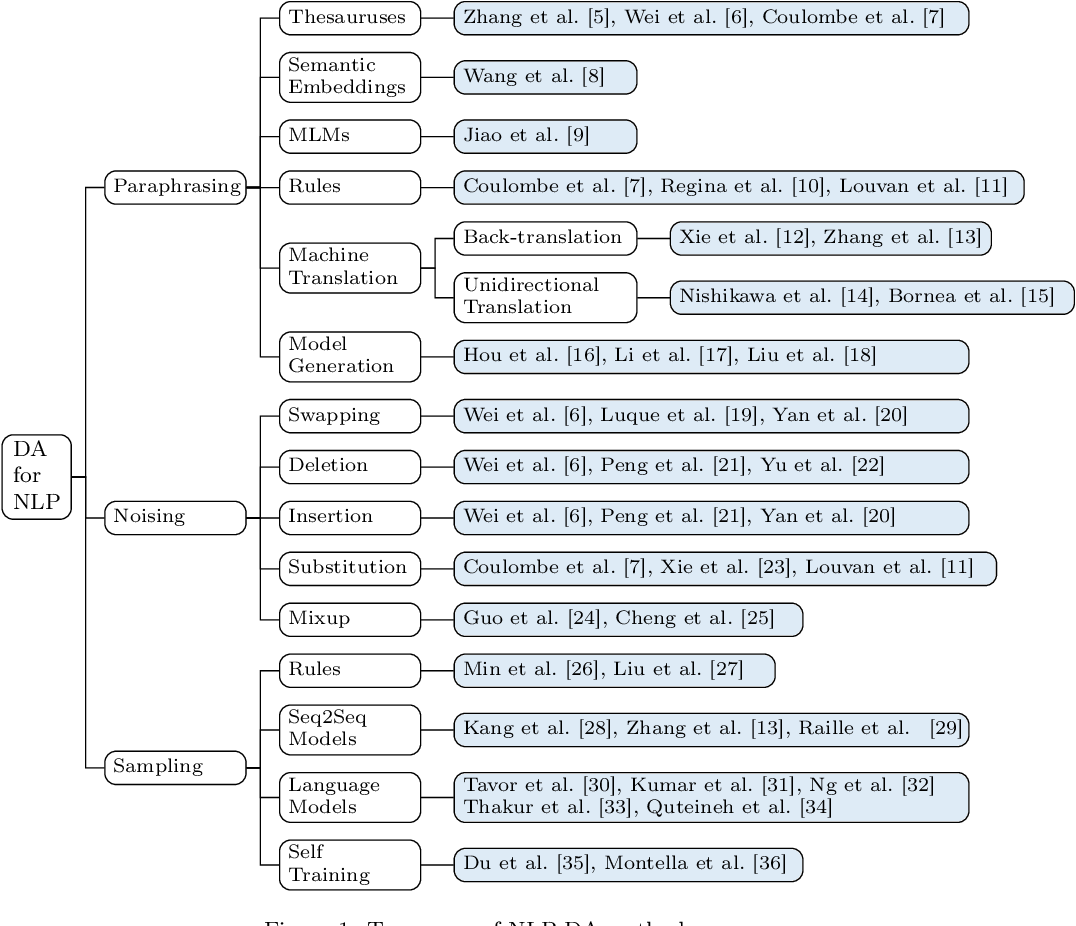
2 Likes
Those were helpful!
- Replace a few words with their synonyms.
- Replace a few words with words that have similar (based on cosine similarity) word embeddings (like word2vec or GloVe) to those words.
- Replace words based on the context using powerful transformer models (BERT).