Hello everyone-
I discussed this with @jeremy and @sgugger already. But the gist is I’m planning on submitting a pull request to add built-in TensorboardX functionality. There’s still a lot more functionality that could be built on top of this, but here’s what I intend on putting up:
- Image generation visualization (for both GAN and non GAN learners)
- Model histograms/distributions for each of the layers
- Various gradient stats
- All available metrics/losses (losses are reported as a ‘metric’ currently).
The single file I plan on putting up is here:
https://github.com/jantic/fastai/blob/Tensorboard-Integration/fastai/callbacks/tensorboard.py
The usage is as follows (example directly from DeOldify):
proj_id = 'Colorize'
tboard_path = Path('data/tensorboard/' + proj_id)
learn.callback_fns.append(partial(GANTensorboardWriter, base_dir=tboard_path, name='GanLearner'))
The approach Jeremy suggested was that I’d just submit the single tensorboard.py file in callbacks without adding dependencies to install files (which would be tensorboard and tensorboardx). He’d add the logic from there to handle the case where the the (still optional) prerequisites aren’t installed- logic that would basically inform the user that if they want to use these callbacks, they’ll have to install these additional dependencies.
I tried to tackle the performance issues and basically that amounted to putting blocking i/o operations into a simple request/queue daemon thread based writer (AsyncTBWriter). This shouldn’t actually be necessary on our part though- it should be handled on the TensorboardX end. So I plan on digging further on that and raising the issue in that project. Anyway my Python isn’t all that great yet so there’s a good chance there’s a better way than what I did there. Just let me know- it won’t hurt my feelings 
A few other things to scrutinize would be GPU to CPU logic on the tensors, the way I’m handling getting and caching batches from one_batch calls (which is slow with ImageNet at least), and the defaults I set for how often these things get written (stats_iters, hist_iters, etc). I basically did what worked for me but this isn’t battle tested for everything. I’ve been running this for a while as is and I haven’t had any noticeable issues.
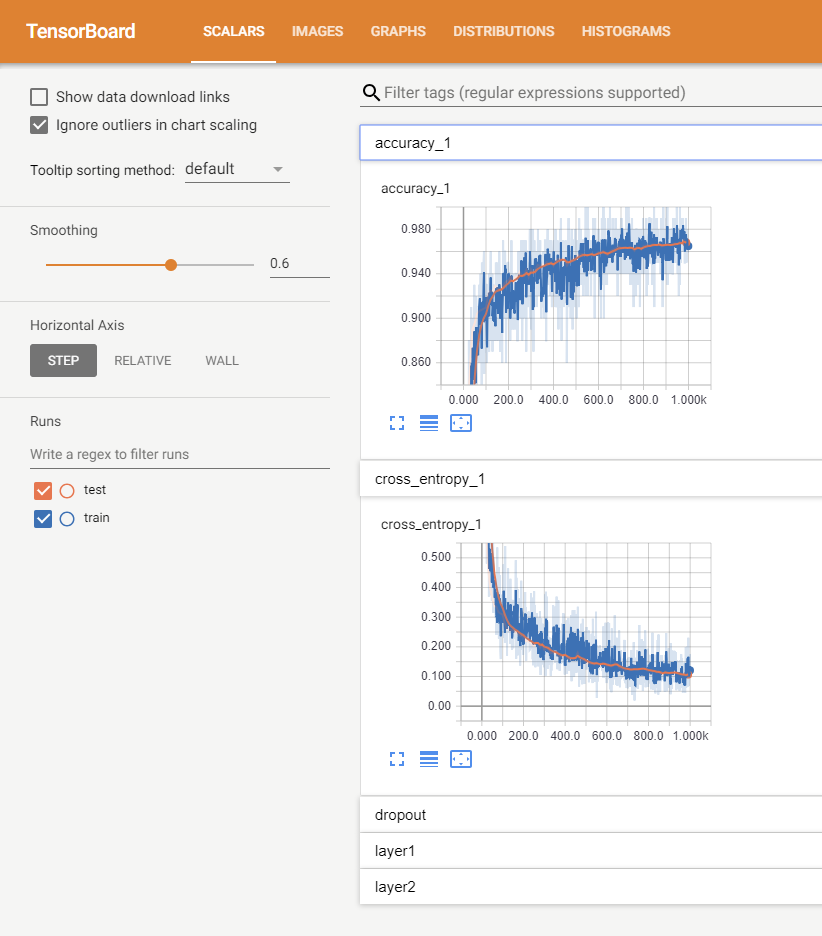
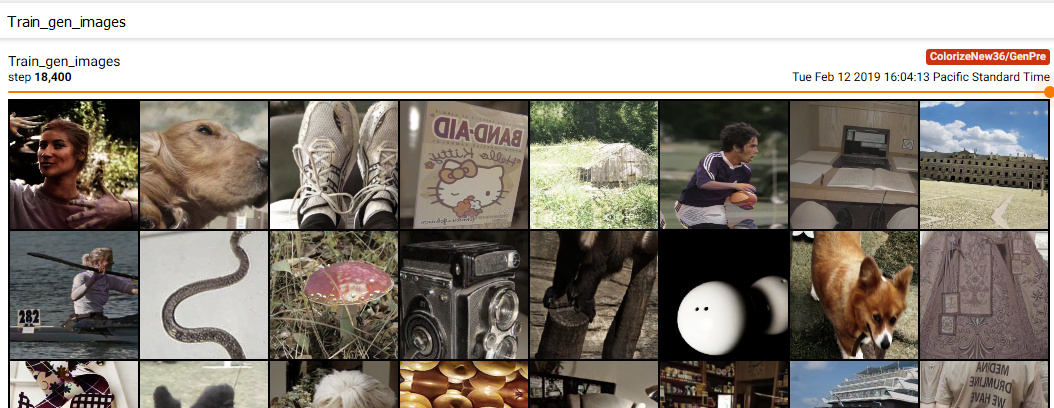
Anyway, I really do recommend using Tensorboard, in particular for image generation and the model histograms. It’s enormously helpful to see the transitions with the image sliders to see the subtle changes in the images.
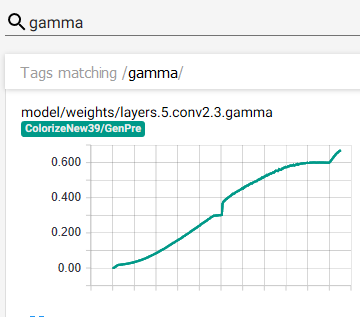
And some puzzling bugs in the model can be readily exposed with the histogram graphs- this happened recently when I found a bug in the new fastai SelfAttention module a few weeks ago, where it wasn’t actually learning. This was obvious in the graphs- gamma remained 0.
I’m new to the whole pull request process so just let me know if I screwed anything up. And i’m certainly willing to put up documentation. Also- the pull request instructions for new features suggest adding tests but I’m honestly not sure what that would consist of in this case (and I’m a guy who is really into testing). Any pointers?
I’ll formally submit the pull request once I get the green-light here.