I have been trying to classify Tennis vs Badminton raquets and the results vary wildly between run to run. The validation accuracy varies from 76% to 100% randomly for every run.
Secondly, what happens when we rm {PATH}tmp? It reads that we delete the ‘precomputed activations’… is it over and above the precomputation anyway the model comes with in resent?
Because, if i don’t clear the tmp and run the epochs again and again, the accuracy quickly hits 100%.
Data sets 100 each for training 20 each for validation. Google downloads, pic size varying wildly.
The validation accuracy varies from 76% to 100% randomly for every run.
your data set of 100 images is too small to achieve the good or stable result, try to collect more images, at least a couple of hundred (or thousand if you want a good model).
Secondly, what happens when we rm {PATH}tmp?
When precompute=True fastai library calculates the output (activations) of all of frozen layers and stores it in {PATH}tmp folder, so every time we run the run (fit) the model we don’t have to calculate the activations from those layers. It saves us a lot of time.
When you delete the tmp folder, you are deleting the precomputed activations of frozen layers. it will force the model to re-compute the activations again.
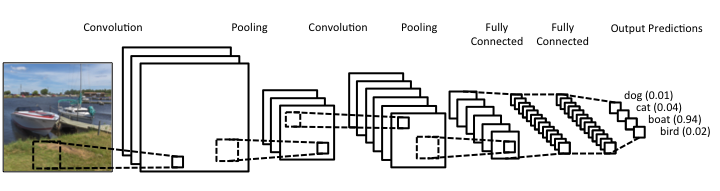
A Convolution network has an architecture like above. When we use pre-trained model, we pop the last layer (output Predictions ) and insert a new layer with outputs equal to classes(for cats-and-dogs it will be 2) in our data set, then we freeze all of the other layers (freezing means, they won’t learn, their weights won’t change)
Now our model will be like this
We have a model with weights that are learnt from a million imagenet images
We ‘fine tune’ that model by popping out the last layer and retrain the last layer for new weights while the weights of all the layers behind the last layer remain unaffected.
With each epoch, we train (only) the last layer better and better.
Right?
Further my question is, does tmp have the learned weights that we inherited from Resnet or the weights we create by training the last layer.
I am confused between two understandings:
1: tmp has those millions of precomputed Resnet model (trained on a million imagenet images) that is a static data store, never touched in this process. So if I do rm tmp, I lose all that wisdom it gained from imagenet and I have a blank architecture with no weights. I need to learn the weights only from my own training on cats and dogs.
(or)
tmp contains that weights of the last layer that has been created from dogs and cats. In that case if I run 3 epochs, then again run 3 epochs, then again run 3 epochs, does each cycle (of 3 epochs) take the weights from tmp and train and store it back into tmp recursively?
Fine tuned model will respond better and faster as it has been already trained with huge datasets and therefore have optimal weights…
Which we don’t want to ruin…
It only works when what we do and what the model had done were alone in nature somewhat…
No, you won’t lose the pre-learned weights of the model, you will only lose the precomputed activation of your training data set.
No tmp doesn’t contain the weights of last or any other layer. Weights of last/all of layer are stored in RAM, unless you specifically store them on harddisk by learn.save()
To make things easy for you
Just consider when you have precompute=True, ‘tmp’ folder just helps your model to learn a little fast, that is all. NOTHING MORE.
Imagenet (or resnet ) model was trained to identify the classes in the Imagenet Dataset, if you are trying to identify a thing that is also present in image data class or very closely related to any of class then you can get a good, and stable result with a small dataset. I am treating the good(high accuracy on val set), stable(good accuracy on never seen before images)
If you need further help put your notebook with the dataset on github and share the link,