After working through some notebooks, I decided to try my hand at a small contest.
It’s a structured data contest in order to predict the severity of an airplane crash based on some input data (altitude, cabin pressure, temperature etc)
The dataset has 10,000 entries.
At first, I tried to have a fixed validation set (last 2000 values) and I got some results. (test set - f1score 84.3%)
I tried to find ways to improve this, and felt one promising way would be to do some form of cross-validation because none of the input variables seem to have any specific order (no time-series)
So I randomly shuffled train/validation data and trained the model again for a few epochs using the new data.
Surprisingly, the model performed worse (test set - best f1 score 84.1% after several iterations)
Am I doing something wrong in theory?
Wouldn’t the model generalise better if I kept shuffling the data, say once every three epochs , 6 times, rather than fit it on the same training set for 18 times?
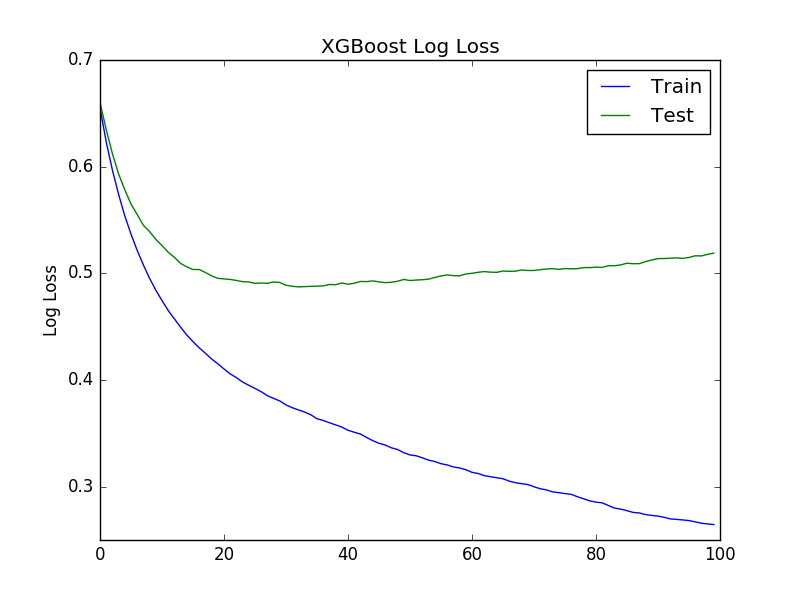
Validation set is how you know when your model is fit well:
(pretend that the green line’s label is validation, some non-fastai people use “test” in place of “valid”)
As you can see after some training the validation loss starts to increase (like in the picture) or doesn’t decrease anymore. When the validation loss is at its minimum, training more won’t help and might even be harmful to your model.
Test set is to see how good your model would work in practice (well as close as we can get to knowing that ).
Shuffling the data between validation and training, while training, defeats their purpose (you won’t know when to stop training).
What you could try:
If the order of the data doesn’t matter then you can have the validation set as some percent of your data. Of course it wouldn’t change while training. It might or might not help but it probably won’t help a lot.
To anyone who will ever come to this thread looking for answers on cross-validation, I stumbled upon this blog post in fastai extensively talking about this.
It further validates the answer by @Hadus