The same preprocessing should be done to your test set, so if you used all three it should be done there as well, as those statistics and patterns are what your model was trained on.
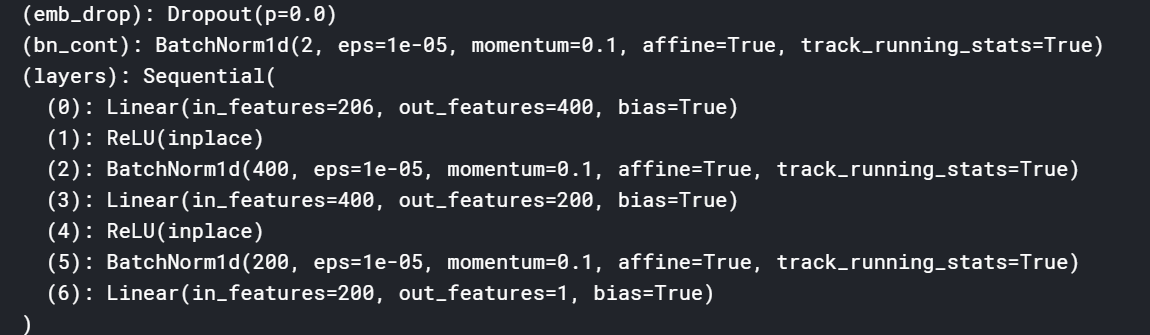
To the second, that is how many neurons are in the fully connected layers that make up our tabular models. There is not a real ‘method’ per-se to a size. Either 200,100, or 1000,500 (like in rossmann) works well. But you could try and see what layer sizes work well
I saw some work a few months ago that saw that 3 layers was the ‘ideal’ model size. Eg 200,200,200. FFT
***** (bn_cont) : BatchNorm1d(2 (what does it mean), eps=1e-05 (whats this)
***** in_features=206, out_features=400 : can I handle them? what is the meaning of this?
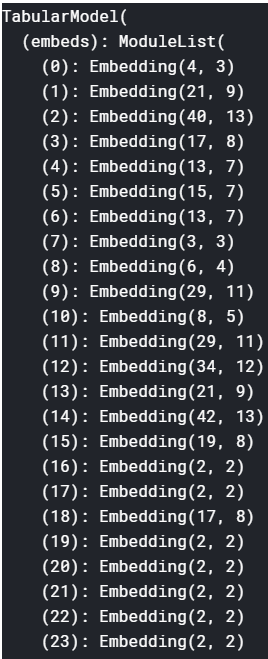
Embedding are for your categorical data - (0): Embedding(4,3) means you have four unique values for the first categorical variable, and three dimensions have been provided to describe that variable. The actual number of dimensions can be changed in the setup. The default is set in tabular.data.py:
def def_emb_sz(classes, n, sz_dict=None):
“Pick an embedding size for n depending on classes if not given in sz_dict.”
sz_dict = ifnone(sz_dict, {})
n_cat = len(classes[n])
sz = sz_dict.get(n, int(emb_sz_rule(n_cat))) # rule of thumb
return n_cat,sz
But you can directly specify the size in your code.
For the in/out sizes, these are your layers. The first in size is the width of your data (including embeddings) and out is the first layer size. For the middle layers, you will see the previous out size become the next in size. Your final out size is the number of possible classifications.
In that post, I just tweaked the number of layers, the number of unit for each layer, and the dropout ratio of each layer while I could set the embedding size for each categorical attribute.