I’m trying to use fast.ai to process the Titanic data from Kaggle. There are 890 rows of data in 12 columns. So after loading the data into a data frame I’m doing:
path = '../working/models'
dep_var = 'Survived'
valid_idx = list(range(50))
procs = [FillMissing, Categorify, Normalize]
cat_names = ['Name', 'Ticket', 'Cabin', 'Sex', 'Embarked']
data = TabularDataBunch.from_df(path, train_df, dep_var, valid_idx=valid_idx, procs=procs, cat_names=cat_names)
learn = tabular_learner(data, layers=[4000,2000], metrics=accuracy)
learn.fit_one_cycle(10, max_lr=3e-2)
And getting:
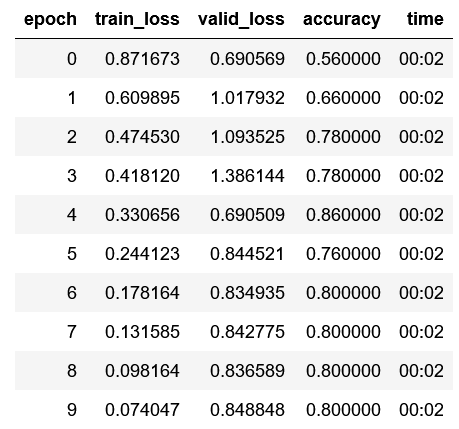
So looks like I’m overfitting like a champ. A couple of questions:
- Is it even reasonable to use deep learning over such a small dataset?
- Am I doing something obviously wrong here? How can I avoid overfitting?
- Are there any guidelines for setting the number of neurons in the hidden layers? The only thing I could find was setting the number in the first layer to 4x the number of inputs.
- When I do
learn.modelI get 171in_featuresfor the first layer. Shouldn’t that be 890, as the number of inputs?