I’ve found this article, where they propose an interesting behavior of the Cost, that it’s not what the book shows (not a punch down, I’ve just noticed it). This what they include:
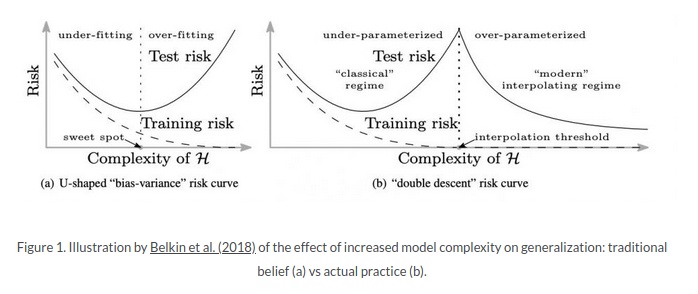
I’m taking it a bit out of context, so you may want to look at the link.
From my interpretation though, this implies that wider networks (more nodes, more parameters) will do better and better without any sweet spot.
Do you have any thoughts on this?