Thanks - I’ll check it out after I’ve got the rest of it sorted!
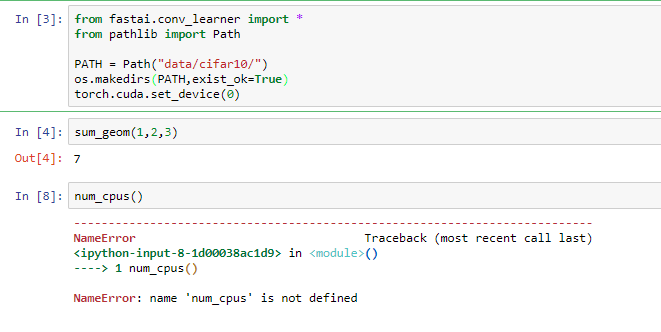
I have recreated the fastai environment, uninstalled the Pytorch it put in place, then pip installed the working peterjc123 version 0.4.0. I got got past the call to num_cpus() without an error, but I am still getting the problem with ConvLearner not seeing the data_path attribute in the parent class - I think this is a genuine bug - see below:
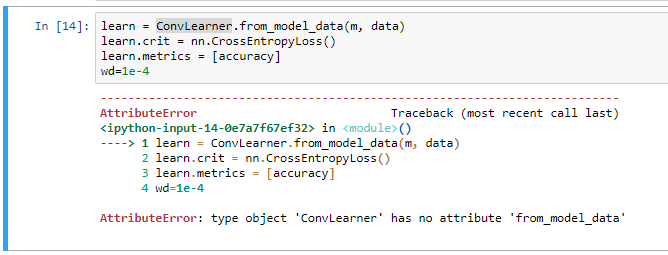
learn = ConvLearner.from_model_data(m, data)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-14-bb021e2adc7e> in <module>()
----> 1 learn = ConvLearner.from_model_data(m, data)
d:\FASTAI\fastai\fastai\learner.py in from_model_data(cls, m, data, **kwargs)
44 @classmethod
45 def from_model_data(cls, m, data, **kwargs):
---> 46 self = cls(data, BasicModel(to_gpu(m)), **kwargs)
47 self.unfreeze()
48 return self
d:\FASTAI\fastai\fastai\conv_learner.py in __init__(self, data, models, precompute, **kwargs)
95 def __init__(self, data, models, precompute=False, **kwargs):
96 self.precompute = False
---> 97 super().__init__(data, models, **kwargs)
98 if hasattr(data, 'is_multi') and not data.is_reg and self.metrics is None:
99 self.metrics = [accuracy_thresh(0.5)] if self.data.is_multi else [accuracy]
d:\FASTAI\fastai\fastai\learner.py in __init__(self, data, models, opt_fn, tmp_name, models_name, metrics, clip, crit)
35 self.opt_fn = opt_fn or SGD_Momentum(0.9)
36 self.tmp_path = tmp_name if os.path.isabs(tmp_name) else os.path.join(self.data.path, tmp_name)
---> 37 self.models_path = models_name if os.path.isabs(models_name) else os.path.join(self.data_path, models_name)
38 os.makedirs(self.tmp_path, exist_ok=True)
39 os.makedirs(self.models_path, exist_ok=True)
AttributeError: 'ConvLearner' object has no attribute 'data_path'
The ConvLearner declaration is class ConvLearner(Learner):
Learner contains a reference to self.data_path - is this a bug - should it read self.data.path as in the line above it in the Learner class definition? I edited the class definition and changed this to self.data.path, and I no longer get an error…
class Learner():
def __init__(self, data, models, opt_fn=None, tmp_name='tmp', models_name='models', metrics=None, clip=None, crit=None):
"""
Combines a ModelData object with a nn.Module object, such that you can train that
module.
data (ModelData): An instance of ModelData.
models(module): chosen neural architecture for solving a supported problem.
opt_fn(function): optimizer function, uses SGD with Momentum of .9 if none.
tmp_name(str): output name of the directory containing temporary files from training process
models_name(str): output name of the directory containing the trained model
metrics(list): array of functions for evaluating a desired metric. Eg. accuracy.
clip(float): gradient clip chosen to limit the change in the gradient to prevent exploding gradients Eg. .3
"""
self.data_,self.models,self.metrics = data,models,metrics
self.sched=None
self.wd_sched = None
self.clip = None
self.opt_fn = opt_fn or SGD_Momentum(0.9)
self.tmp_path = tmp_name if os.path.isabs(tmp_name) else os.path.join(self.data.path, tmp_name)
self.models_path = models_name if os.path.isabs(models_name) else os.path.join(self.data_path, models_name)
os.makedirs(self.tmp_path, exist_ok=True)
os.makedirs(self.models_path, exist_ok=True)
self.crit = crit if crit else self._get_crit(data)
self.reg_fn = None
self.fp16 = False

 I see there is a pull request for this bug at the moment!
I see there is a pull request for this bug at the moment!