Disclaimer, I’m quite new to Python/ML, be kind if I’m suggesting something dumb ![]()
In the code for RNNRegularizer, the TAR is taken as the difference along dimension 1 with h[:,1:] - h[:,:-1].
After wrapping my head around what this actually did, I was curious to see if it was any different to using the .diff method like h.diff(dim=1).
On a CPU, no difference, but on the GPU it is slightly faster.
While I was at it, I also tried comparing .pow(2) with .square(), wondering if there was some hardware-level acceleration done for the latter. Tests show that it is quite a bit faster.
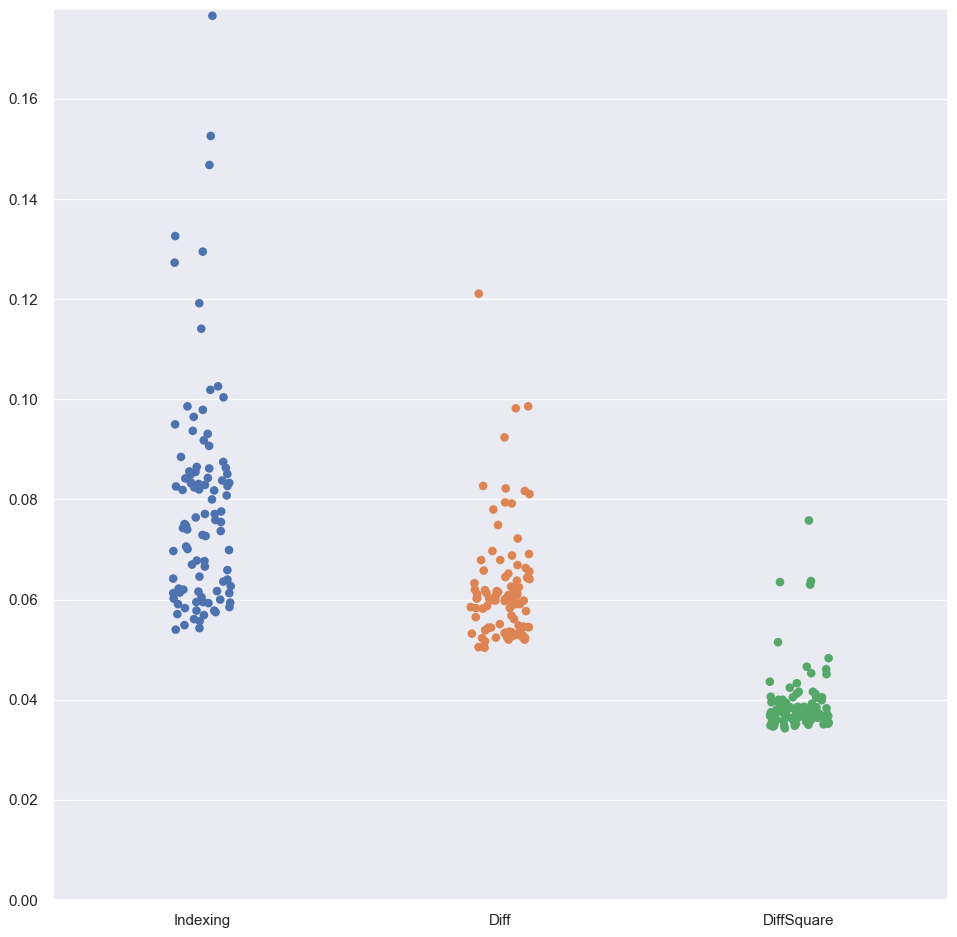
The above compares these three snippets, 100 runs each, on a GPU:
res1 = (h[:, 1:] - h[:, :-1]).float().pow(2).mean()
res2 = h.diff(dim=1).float().pow(2).mean()
res3 = h.diff(dim=1).float().square().mean()
IMO using .diff() is easier on the eye/brain than the indexing method, with mild performance benefit to boot.
And it seems like a global search/replace for .pow(2) → .square() might eek out some more ‘fast’ (and reads nicer, says me).
But perhaps these operations are such a tiny part of any real training process that it’s not worth the effort. Or maybe this is just on my machine and not universal?